Thursday, May 17th 2012

GK110 Packs 2880 CUDA Cores, 384-bit Memory Interface: Die-Shot
With its competition checked thanks to good performance by its GK104 silicon, NVIDIA was bold enough to release die-shots of its GK110 silicon, which made its market entry as the Tesla K20 GPU-compute accelerator. This opened flood-gates of speculation surrounding minute details of the new chip, from various sources. We found one of these most plausible, by Beyond3D community member "fellix". The source of the image appears to have charted out component layout of the chip by some pattern recognition and educated guesswork.
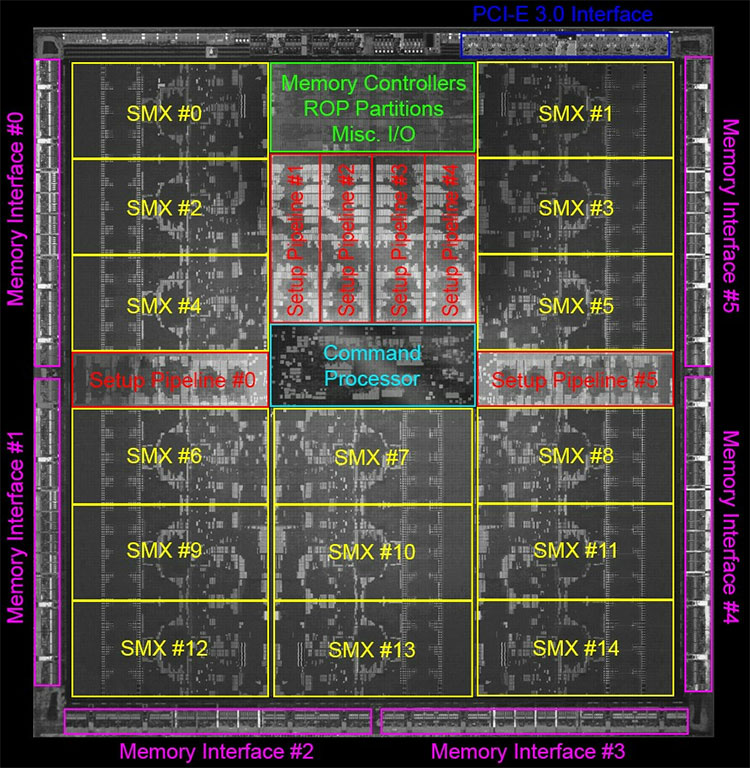
It identifies the the 7.1 billion transistor GK110 silicon to have 15 streaming multiprocessors (SMX). A little earlier this week, sources close to NVIDIA confirmed the SMX count to TechPowerUp. NVIDIA revealed that the chip will retain the SMX design of GK104, in which each of these holds 192 CUDA cores. Going by that, GK110 has a total of 2880 cores. Blocks of SMX units surround a centrally-located command processor, along with six setup pipelines, and a portion holding the ROPs and memory controllers. There are a total of six GDDR5 PHYs, which could amount to a 384-bit wide memory interface. The chip talks to the rest of the system over PCI-Express 3.0.
Source:
Beyond3D Forum
It identifies the the 7.1 billion transistor GK110 silicon to have 15 streaming multiprocessors (SMX). A little earlier this week, sources close to NVIDIA confirmed the SMX count to TechPowerUp. NVIDIA revealed that the chip will retain the SMX design of GK104, in which each of these holds 192 CUDA cores. Going by that, GK110 has a total of 2880 cores. Blocks of SMX units surround a centrally-located command processor, along with six setup pipelines, and a portion holding the ROPs and memory controllers. There are a total of six GDDR5 PHYs, which could amount to a 384-bit wide memory interface. The chip talks to the rest of the system over PCI-Express 3.0.
65 Comments on GK110 Packs 2880 CUDA Cores, 384-bit Memory Interface: Die-Shot
Give us the $200 660Ti with 2GB Vram and low power draw, you know, a card that the majority of Pc gamers can actually afford to buy or sensible enough not to want OTT crap like a 690.
Anandtech also has a nice breakdown of K10 and K20.
www.anandtech.com/show/5840/gtc-2012-part-1-nvidia-announces-gk104-based-tesla-k10-gk110-based-tesla-k20
Adds this about the CUDA cores:
Tesla cards are always clocked low for power efficiency but a fast clocked GK110 will consume quite a bit of power. I don't know if Nvidia have any plans to release GK110 as a desktop. Maybe there will be a revision of GK110 to GK114 for desktop as a GTX7xx card.
And history repeats itself like with 8800GT 128 core to GTX280 240 core separated by 9 months. 8800GT dropping to 160, 110 and $86 shortly after that, the GTX670 being comparable to 8800GT in this case.
But what I'd like to know is if the SMX is composed of 192 FP32 + 64 FP64 shaders or only 192 shaders of which 64 are DP? And is either one of those options really so much better than what they did on Fermi (for a HPC part I mean, for gaming there is no doubt)? Because 7 billion transistors is quite a lot, it would allow for a Fermi based chip with at least 1280 SPs, I'm sure. How that would translate to performance and perf/watt, that's another story, but remember that a large part of why Kepler is so much more efficient is because nvidia worked closely with TSMC from the start, something they never did for Fermi. The sheer architectural benefit on the perf/watt front is not so clear to me since I heard of such a relationship*. For GK107 the benefit is more clear, but Kepler does not seem to scale as you add SM(X)'s as well as Fermi did. Or maybe it's just GK104 that has too many, admittely it's not like we have too many chips to compare. Of course GK110 might/should use dynamic schedulers if they reall want good HPC performance in all situations and that might be the culprit of the "poor" scaling, so we'll see. And I'm just rambling so...
*Or lack of relationship with Fermi, because I admit that I used to give such collaboration between a foundry and its customers as granted, I never thought it would be something "extraordinary".Remember that all Fermi chips, including low-end ones had DP capable shaders (1:4 ratio) and GF100/110 had 1:2 DP shaders. Now gaming oriented Kepler chips have a lot less DP capabilities, which does not mean that GK110 is less aimed at gaming than the entire Fermi line was. For example there's no mention of reduced amount of texture mapping units and except for the additional FP64 shaders the SMX are suposedly equal, so that means they didn't want to compromise gaming performance.
Please don't double post, there is an edit button for a reason. Thanks. :)
You do realize that this is a tech site ?
www.nvidia.com/content/PDF/kepler/NVIDIA-Kepler-GK110-Architecture-Whitepaper.pdf
Lots of interesting stuff. After a quick look at it, it does look like everything related to scheduling and warp creation is not only back to GF100 levels, but it goes a lot further. Honestly looking at how they crammed 2880 FP32 and 960 FP64 and all the other stuff that is close to 2x that of GK104, was it really necessary to simplify/cripple GK104's GPGPU capabilities so much? Apparently not on an area efficiency basis, maybe for perf/watt? Not really if their claim of 3x perf/watt is true. Maybe it was just so that GPGPU users had an only option: GK110 based parts. Damn you nvidia.
Ok. I'll continue reading.
nvidia clearly has split gaming cards and professional cards based..
so, this is tesla cards for gpu computations :)
Those GPU's are not for "nerds jerking off" or even PC gaming, but for professional use, like CAD workstations, 3D simulations servers, etc, not for average Joe. :shadedshu:shadedshu:shadedshu
even nvidia hasnt yet releasing an official statement about GTX780 nor GTX685 :), i'm sorry, i'm not a paranormal so the fact for me now that GK110 is Tesla Cards and also nvidia clearly has already split gaming cards and professional cards. ;)