Wednesday, January 22nd 2014

AMD Debuts New 12- and 16-Core Opteron 6300 Series Processors
AMD today announced the immediate availability of its new 12- and 16-core AMD Opteron 6300 Series server processors, code named "Warsaw." Designed for enterprise workloads, the new AMD Opteron 6300 Series processors feature the "Piledriver" core and are fully socket and software compatible with the existing AMD Opteron 6300 Series. The power efficiency and cost effectiveness of the new products are ideal for the AMD Open 3.0 Open Compute Platform - the industry's most cost effective Open Compute platform.
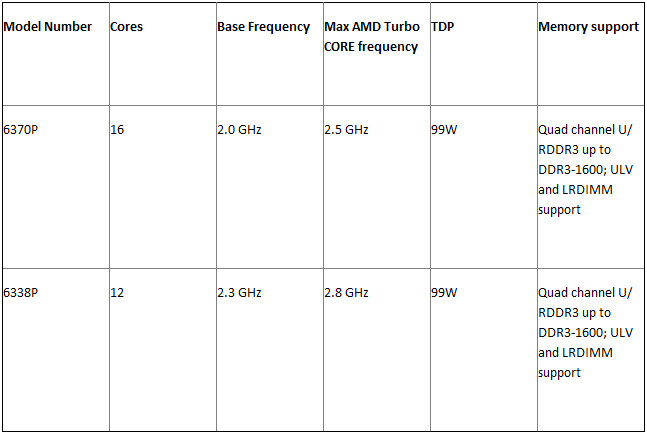
Driven by customers' requests, the new AMD Opteron 6338P (12 core) and 6370P (16 core) processors are optimized to handle the heavily virtualized workloads found in enterprise environments, including the more complex compute needs of data analysis, xSQL and traditional databases, at optimal performance per-watt, per-dollar. "With the continued move to virtualized environments for more efficient server utilization, more and more workloads are limited by memory capacity and I/O bandwidth," said Suresh Gopalakrishnan, corporate vice president and general manager, Server Business Unit, AMD. "The Opteron 6338P and 6370P processors are server CPUs optimized to deliver improved performance per-watt for virtualized private cloud deployments with less power and at lower cost points."
"With the continued move to virtualized environments for more efficient server utilization, more and more workloads are limited by memory capacity and I/O bandwidth," said Suresh Gopalakrishnan, corporate vice president and general manager, Server Business Unit, AMD. "The Opteron 6338P and 6370P processors are server CPUs optimized to deliver improved performance per-watt for virtualized private cloud deployments with less power and at lower cost points."
The new AMD Opteron 6338P and 6370P processors are available today through Penguin and Avnet system integrators and have been qualified for servers from Sugon and Supermicro at a starting price of $377 and $598, respectively. More information can be found on AMD's website.
Driven by customers' requests, the new AMD Opteron 6338P (12 core) and 6370P (16 core) processors are optimized to handle the heavily virtualized workloads found in enterprise environments, including the more complex compute needs of data analysis, xSQL and traditional databases, at optimal performance per-watt, per-dollar.

The new AMD Opteron 6338P and 6370P processors are available today through Penguin and Avnet system integrators and have been qualified for servers from Sugon and Supermicro at a starting price of $377 and $598, respectively. More information can be found on AMD's website.
48 Comments on AMD Debuts New 12- and 16-Core Opteron 6300 Series Processors
16 real cores :twitch:
So i have no choice instead using (buying) xeon server and workstation for my lab which is very expensive..
That was very frustating..
That makes for better power usage.
The fact is that with the Bulldozer architecture AMD choose to implement CMT in the form of modules rather than Hyperthreading as implemented by Intel (here called SMT). A module on an AMD CPU acts as 2 independent cores, but nonetheless they share certain functional units together. So technically they are NOT 2 independent cores. It's more or less the same as with Intels Hyperthreading, where a core can run 2 threads simultaneously and is seen by the OS as 2, but is actually only one core.
So maybe AMDs implementation of CMT/SMT in the form of modules is a step further in the direction of independent cores than Intel is with Hyperthreading. But all that doesn't really matter at all. At the end of the day, what counts is the performance you get out of the CPU (or performance per dollar or performance per watt, whatever matters most to you).
As far as I'm concerned, they should advertise these as 6 modules / 12 threads and 8 modules / 16 threads like Intel does with for instance the 8 core / 16 threads (8c/16t) nomenclature...
Intel uses unused resources in the CPU to get extra multi-threaded performance. AMD added extra hardware for multi-threaded performance as opposed to using just the extra resources available. The performance of a module vs the performance of a single core with HT has costs and benefits of their own. With an Intel CPU, that second thread doesn't nearly have as much processing power that the first thread does, where with AMD, the amount of performance that second "thread" or "core" if you will has much more tangible gains than the HT thread does.
It's worth mentioning that the integer units do have enough hardware to run two full threads side-by-side. It's the floating point unit that doesn't but even still, FMA is supposed to give some ability to decouple the 256-bit FP unit to do two 128-bit ops at once.
I think AMD's goal is to emphasize what CPUs do best, integer math, and let GPUs do what they do best, FP math. Not to say that a CPU shouldn't do any FP math, but if there is a lot of FP math to be done, a GPU is better optimized to do those kinds of operations.
Also, I should add that I'm pretty sure that AMD clocks are controlled on a per-module basis but parts of each module can be power gated to improve power usage. One of the biggest benefits of having a module is that you save die space to add that second thread without too much of a hit on single-threaded performance (relatively speaking).Please don't feed the
duckstrolls.However I have a question. Don't you think this approach is somehow not ideal for AMD, because in this way, a core is having a lot less transistors than Intel's, therefore the bad performance in single-threaded applications, like games for example?
I don't understand why AMD is still going for strong GPU performance, even on the so called top CPU's, instead of having a GPU with only basic stuff to run the Win 7 desktop, then with the available space to increase the transistor count for each of the cores?? This way I think they will finally have a CPU to compete with the I7. Just some thoughts.
Either way, CPUs are fast enough where there definitely is a point of diminishing returns. A CPU will only go so fast and you can only cram so many transistors in any given area. Also, on games that can utilize multi-core systems well, AMD isn't trailing behind all that much. Considering upcoming consoles have 8c CPUs in them, there will be more of a push to utilize that kind of hardware. It's completely realistic for a machine to have at least 4 logical threads now and as many as 8 for a consumer CPU. This wasn't the case several years ago.
An ordinary Core i7-4770K quad-core has a DP performance of about 177 GFLOPS. Thats for a 84W CPU (talking TDP). NVidia's 780Ti though is rated at 210 GFLOPS DP performance (DP is crippled on consumer chips, I know), but this comes at a cost of a whopping 250W TDP, which is about 3x the power draw! So simple math tells me that the Haswell i7 is about twice as efficient in DP-FP calculations as the current-gen GPU hardware is...
Single precision might be a totally different story though. :)
A nVidia Titan has ~1300 GFLOPS DP at 250W TDP, but that was not the point.
All that compute power on your GPU is pretty useless unless you have a task where you have to crunch numbers for an extended period of time AND your task can be scheduled in parallel, but I guess you know that. The latencies for copying data to the GPU and after processing there from the GPU back to the main memory / CPU are way to high for any mixed workload to perform well, so strong single-threaded FP performance will always be important in some way.
Basically CPUs are good at working with data that changes a lot (relatively small amounts of data that change a lot). GPUs are good at processing (or transforming if you will) a lot of data in a relatively fixed way.
So a simple example of what GPUs do best would be something like.
Where a CPU would excel at something like adding all of those elements, or doing something that reduces those values, as opposed to transforming it to a set of the same size as the input.See Stream Processing on Wikipedia.
Edit: Aquinius you speedy guy beat me to it with more eloquence.