Monday, April 30th 2018

AMD "Vega 20" with 32 GB HBM2 3DMark 11 Score Surfaces
With the latest Radeon Vega Instinct reveal, it's becoming increasingly clear that "Vega 20" is an optical shrink of the "Vega 10" GPU die to the new 7 nm silicon fabrication process, which could significantly lower power-draw, enabling AMD to increase clock-speeds. A prototype graphics card based on "Vega 20," armed with a whopping 32 GB of HBM2 memory, was put through 3DMark 11, on a machine powered by a Ryzen 7 1700 processor, and compared with a Radeon Vega Frontier Edition.
The prototype had lower GPU clock-speeds than the Vega Frontier Edition, at 1.00 GHz, vs. up to 1.60 GHz of the Vega Frontier Edition. Its memory, however, was clocked higher, at 1250 MHz (640 GB/s) vs. 945 MHz (483 GB/s). Despite significantly lower GPU clocks, the supposed "Vega 20" prototype appears to score higher performance clock-for-clock, but loses out on overall performance, in all tests. This could mean "Vega 20" is not just an optical-shrink of "Vega 10," but also benefits from newer architecture features, besides faster memory.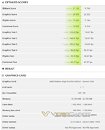
Source:
VideoCardz
The prototype had lower GPU clock-speeds than the Vega Frontier Edition, at 1.00 GHz, vs. up to 1.60 GHz of the Vega Frontier Edition. Its memory, however, was clocked higher, at 1250 MHz (640 GB/s) vs. 945 MHz (483 GB/s). Despite significantly lower GPU clocks, the supposed "Vega 20" prototype appears to score higher performance clock-for-clock, but loses out on overall performance, in all tests. This could mean "Vega 20" is not just an optical-shrink of "Vega 10," but also benefits from newer architecture features, besides faster memory.

77 Comments on AMD "Vega 20" with 32 GB HBM2 3DMark 11 Score Surfaces
TMUs and ROPs are not, by any stretch of the imagination, the only classifiers as far graphics processing goes. It's the reason they have been decoupled from the graphics pipeline more than a decade ago and now shaders far outnumber TMUs and ROPs. It used to be that for each shader you would have one ROP and one TMU but that proved to be wasteful and it turned out you can extract more performance by adding more shaders since rasterization does not require the same scaling in terms of performance.
The ratio of ROP to shader of the new RTX 2080ti is 1 to 49, that's how important they are to graphics performance.
Seriously, ROPs and TMUs is the only hardware that dictates traditional GPU performance ? I feel like I would hear that 20 years ago.
GTX 1080 Ti has more rasterization (6 GPCs) and ROPS (88 ROPS at 1600 Mhz to 1800 Mhz) power when compared to Vega 64's 4 GPC equivalent and 64 ROPS at 1550 Mhz to 1600Mhz.
With AMD GPUs, pixel and computer shader read/write paths are different i.e. common ALUs with different read/write paths. AMD's pixel shader read/write path is bottleneck'ed by 64 ROPS units.
RTG changed thier CU/TMU vs ROPS ratio with recent Vega 24 M GH i.e. 24 CU (96 TMU) vs 64 ROPS (64 pix/clk)
NVIDIA Maxwell/Pascal GPUs still has split TMU and ROPS read/write paths with common shader ALUs.
RTX cores in RTX 2070/2080/2080 Ti marks the return non-unified shader/compute cores.