Friday, April 1st 2022

AMD Claims Radeon RX 6500M is Faster Than Intel Arc A370M Graphics
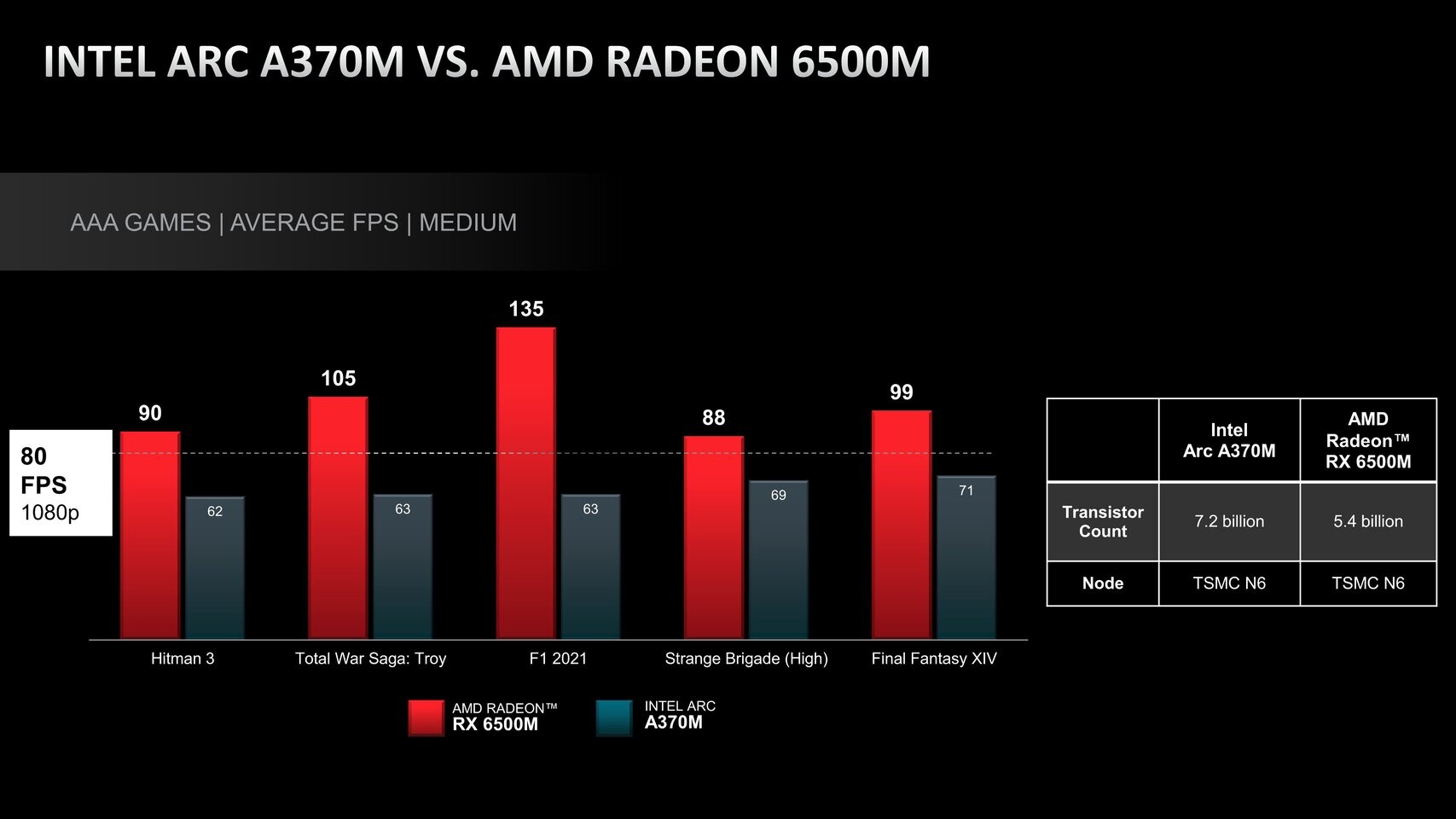
A few days ago, Intel announced its first official discrete graphics card efforts, designed for laptops. Called the Arc Alchemist lineup, Intel has designed these SKUs to provide entry-level to high-end options covering a wide range of use cases. Today, AMD has responded with a rather exciting Tweet made by the company's @Radeon Twitter account. The company compared Intel's Arc Alchemist A370M GPU with AMD's Radeon RX 6500M mobile SKUs in the post. These GPUs are made on TSMC's N6 node, feature 4 GB GDDR6 64-bit memory, 1024 FP32 cores, and have the same configurable TDP range of 35-50 Watts.
Below, you can see AMD's benchmarks of the following select games: Hitman 3, Total War Saga: Troy, F1 2021, Strange Brigade (High), and Final Fantasy XIV. The Radeon RX 6500M GPU manages to win in all of these games, thus explaining AMD's "FTW" hashtag on Twitter. Remember that these are vendor-supplied benchmarks runs, so we have to wait for some media results to surface.
Source:
@Radeon (Twitter)
Below, you can see AMD's benchmarks of the following select games: Hitman 3, Total War Saga: Troy, F1 2021, Strange Brigade (High), and Final Fantasy XIV. The Radeon RX 6500M GPU manages to win in all of these games, thus explaining AMD's "FTW" hashtag on Twitter. Remember that these are vendor-supplied benchmarks runs, so we have to wait for some media results to surface.
48 Comments on AMD Claims Radeon RX 6500M is Faster Than Intel Arc A370M Graphics
Having said all this, TFLOP/performance ratio is a pretty crappy way to evaluate performance since each companies shader cores are different, therefore making the number almost irrelevant outside of inter-architectural comparisons. TMU's, ROP's, and by proxy, texture fill and pixel fill rates, are much more accurate ways to evaluate performance. Even still, it varies pretty wildly sometimes.
Also, comparing TFLOPS is useless with Nvidia now because they base their numbers on using FP and INT calculations at the same time -- which doesn't happen in gaming or general use scenarios. For example, the 2070 super has about 9-10TFLOPS of compute vs the RTX 3050's 9TFLOPS. If you cut the 3050's in half however, you get a closer comparison to traditional TFLOP calculations based on standard FP32 calculations. That would peg the 3050 at 4.5tflops with roughly performance around a 1660 ti.
To bring this all home, those numbers are not safe realistically because they are based on numbers that don't matter. The 512 EU GPU, with 4096 SP's, Will probably be matched by the 3060 ti, a card with 4864 shader cores (but cut that roughly in half) and 16 TFLOPS (again, roughly cut that in half). So Intel's highest end part will most likely match, or barely beat, a 2432 shader core part with 8TFLOPS of true fp32 computational power. If it can do it in the same TGP or TDP, then that's really all that matters. But it still shows that Nvidia and AMD's architecture are so far ahead at this point, Intel won't catch up anytime soon.
This isn't a personal attack or anything. It's just trying to explain that the math doesn't always equal expected results when taken at face value. I want intel to compete as much as anyone else but unfortunately I think we are going to see some pretty lackluster parts. Their ace-in-the-hole has to be pricing and feature-set. If XeSS is as good as it looks, and their media engine is also as good, it could be a pretty nice card at the right price.
Or it could end up sucking complete ass and having us wonder why we were excited at all. That's the fun.
With a lot of what you mentioned I agree and it's not in contrast to what or why I wrote in my post, let me explain:
1. I don't compare performance levels, I compare performance at specific resolution / TFlop (boost) ratios and it is only for the desktop parts.
2. This is not meant to demonstrate a method calculating performance levels for ARC or other architectures, since as you correct say it's meaningless knowing only the TF rating since there are many more characteristics comprising a GPU that this is fundamentally wrong (even in the same architectures you can see how much different results you can get with different pixel/texture/memory configurations, just look 6900XT vs 6800...) , my post is just a statement, a statement that things will not be so bad as some guys think after AMD's performance comparison, since if you look at it, desktop DG2-512 having only -5% 4K performance/TF ratio vs Nvidia's 3070 is not exactly bad, it will not be as good as RDNA2 but still a little bit better than VEGA 64. This does not mean that on its own the performance per terraflop achieved is great, as you point out Turing (first Nvidia design with concurrent TIPS/TFLOPS throughput) for example had much better performance per terraflop than Ampere/Pascal etc.
Well you may guess it by now but first I made my analysis for what ARC architecture might bring and then I choose competing models from AMD & Nvidia to paint a positive picture for ARC because we need a third player, if I wanted I could have picked other competing models from AMD & Nvidia to paint a bad picture, it's all smoke and mirrors, like what AMD is doing comparing transistor counts for A370M & 6500M and then suggesting that they achieved much greater performance although their design is smaller, it's deceiving because it creates a negative picture for their competitor with a comparison that it's not fair (the media engine is more advanced than AMD's and takes more space, also the bus is 96bit and this also take space, ARC supports matrix math and the throughput per SM/Xe Core is twice vs even Ampere devoting a lot of space for neural network/AI processing which takes also a lot of space and will not bare fruits for classic raster, etc) and the most important thing of course is Intel's driver immaturity and that every developer is optimizing their engines for RDNA2, so taking account all the above it's perfectly natural for Intel to have inferior performance while the design is bigger, it doesn't mean much essentially, just like the performance/TFlop comparison...
The numbers I presented does not state performance level directly, you have to choose a frequency for DG2-512 to find what I suggest regarding performance, for example at 2.25GHz it will be -21% slower than 3070 in this worst case scenario (lower even than your 3060Ti performance level suggestion) and DG2-384 at 3060 level, so not exactly so optimistic as the -5% 3070 perf/TFlop phrasing suggest (smoke and mirrors)
Again with the correct pricing (if we don't have driver/software major issues) everything will be fine.
I'm looking forward to seeing a budget thin&light with a Ryzen5 and 6500M - the IGP and dGPU were designed to work together, which is why the 6500XT is short on encoder/decoder/outputs - it'll basically be auxiliary shaders, TMUs, and ROPs for the IGP to draw on, all connected to GDDR6 so that the IGP isn't hampered by shared DDR4.
SLI/Crossfire died a long time ago, but I'm wondering if a Cezanne IGP with Navi24 will actually multi-GPU, or whether the IGP will be solely used for encode/decode/low-power GPU functions and the 6500M will do all the lifting when it's active.
'The next Frontier' Raja must have thought at some point. I think he's a Trekkie at heart. It also explains the mental die size, after all, the Federation doesnt worry about money anymore.
And that's the baseline... they really need per title optimization to overtake Nvidia / AMD drivers that have a massive amount of customization in them.
2030, maybe... I reckon AMD fine wine is nothing compared to what Intel is gonna have to do.
If Intel is smart, they put full GPU control in the hands of the crowd and let them fix it for them. Bethesda style. Any other path is disaster, they will always be behind. Look at how long AMD needed to catch up from their GCN/ Fury > Vega 'dip'... over five years.
It echoes in the time to market they have now for Arc: this train won't stop, even if it seems to have slowed down with Pascal/Turing/Ampere being spaced apart further. Arc is starting the race already barely catching on.
I doubt they'll be trying any kind of mGPU though - it's just too flaky, to difficult to implement, and latency over PCIe negates the possibility of any type of transparent solution. I'm hoping/expecting this to change when we get MCM APUs though - hopefully with some sort of package-integrated bridge IF solution to cut its power draw.
So the 6500M will likely just be the core GPU functionality of 16CU and a GDDR6 controller and any other functions will be handled by the fully-featured IGP.
It's not going to be fast, but in terms of FPS/Watt I expect it to be at or near the top of the charts, and for a thin & light laptop, that's potentially the most important chart to win.
Hopefully enough people will buy their GPUs (probably wont be me) to create more competition.