Monday, July 11th 2022

NVIDIA PrefixRL Model Designs 25% Smaller Circuits, Making GPUs More Efficient
When designing integrated circuits, engineers aim to produce an efficient design that is easier to manufacture. If they manage to keep the circuit size down, the economics of manufacturing that circuit is also going down. NVIDIA has posted on its technical blog a technique where the company uses an artificial intelligence model called PrefixRL. Using deep reinforcement learning, NVIDIA uses the PrefixRL model to outperform traditional EDA (Electronics Design Automation) tools from major vendors such as Cadence, Synopsys, or Siemens/Mentor. EDA vendors usually implement their in-house AI solution to silicon placement and routing (PnR); however, NVIDIA's PrefixRL solution seems to be doing wonders in the company's workflow.
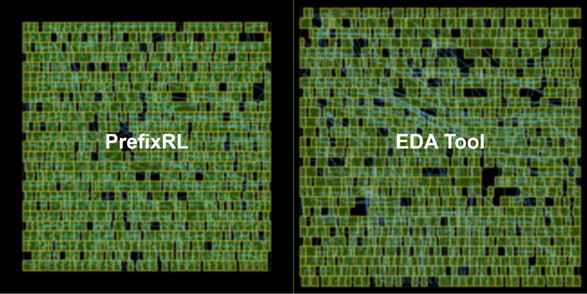
Creating a deep reinforcement learning model that aims to keep the latency the same as the EDA PnR attempt while achieving a smaller die area is the goal of PrefixRL. According to the technical blog, the latest Hopper H100 GPU architecture uses 13,000 instances of arithmetic circuits that the PrefixRL AI model designed. NVIDIA produced a model that outputs a 25% smaller circuit than comparable EDA output. This is all while achieving similar or better latency. Below, you can compare a 64-bit adder design made by PrefixRL and the same design made by an industry-leading EDA tool.
 Training such a model is a compute-intensive task. NVIDIA reports that the training to design a 64-bit adder circuit took 256 CPU cores for each GPU and 32,000 GPU hours. The company developed Raptor, an in-house distributed reinforcement learning platform that takes unique advantage of NVIDIA hardware for this kind of industrial reinforcement learning, which you can see below and how it operates. Overall, the system is pretty complex and requires a lot of hardware and input; however, the results pay off with smaller and more efficient GPUs.
Training such a model is a compute-intensive task. NVIDIA reports that the training to design a 64-bit adder circuit took 256 CPU cores for each GPU and 32,000 GPU hours. The company developed Raptor, an in-house distributed reinforcement learning platform that takes unique advantage of NVIDIA hardware for this kind of industrial reinforcement learning, which you can see below and how it operates. Overall, the system is pretty complex and requires a lot of hardware and input; however, the results pay off with smaller and more efficient GPUs.
Source:
NVIDIA
Creating a deep reinforcement learning model that aims to keep the latency the same as the EDA PnR attempt while achieving a smaller die area is the goal of PrefixRL. According to the technical blog, the latest Hopper H100 GPU architecture uses 13,000 instances of arithmetic circuits that the PrefixRL AI model designed. NVIDIA produced a model that outputs a 25% smaller circuit than comparable EDA output. This is all while achieving similar or better latency. Below, you can compare a 64-bit adder design made by PrefixRL and the same design made by an industry-leading EDA tool.


43 Comments on NVIDIA PrefixRL Model Designs 25% Smaller Circuits, Making GPUs More Efficient
Like @Valantar said, others have not confirmed using AI, so I'm sure there are neural networks or something like that to compare. But the solution overall is clearly better.
www.cnbc.com/2021/06/10/google-is-using-ai-to-design-chip-floorplans-faster-than-humans.html
www.forbes.com/sites/karlfreund/2021/08/09/using-ai-to-help-design-chips-has-become-a-thing
Some sort of "AI" has been employed by these problems for decades.
What we should be concentrating on, is what exactly passes as "AI". Years ago, AI was defined as something able to pass the Turing test (en.wikipedia.org/wiki/Turing_test). It needed to learn and adapt. In the past few years, "AI" means a neural network, deeper than 3 or 4 layers (hence deep-everything). It learns nothing once deployed, but it can be trained further and deployed again. And while that may yet qualify as a passable definition of AI (by very, very lax standards), once AI has become a buzzword, now almost every program that an if in it, claims to be employing "AI".
So you see, it's if other have been employing AI, imho, it's determining what they mean by AI when they said they used it.
Difference between machine learning and AI:
If it is written in Python, it's probably machine learning
If it is written in PowerPoint, it's probably AI
there are formulas for all of this but the actual chip may have required a few spins to get on target and this AI may be able to do it in software and also seems to eliminate the wasted space due to design flaws.