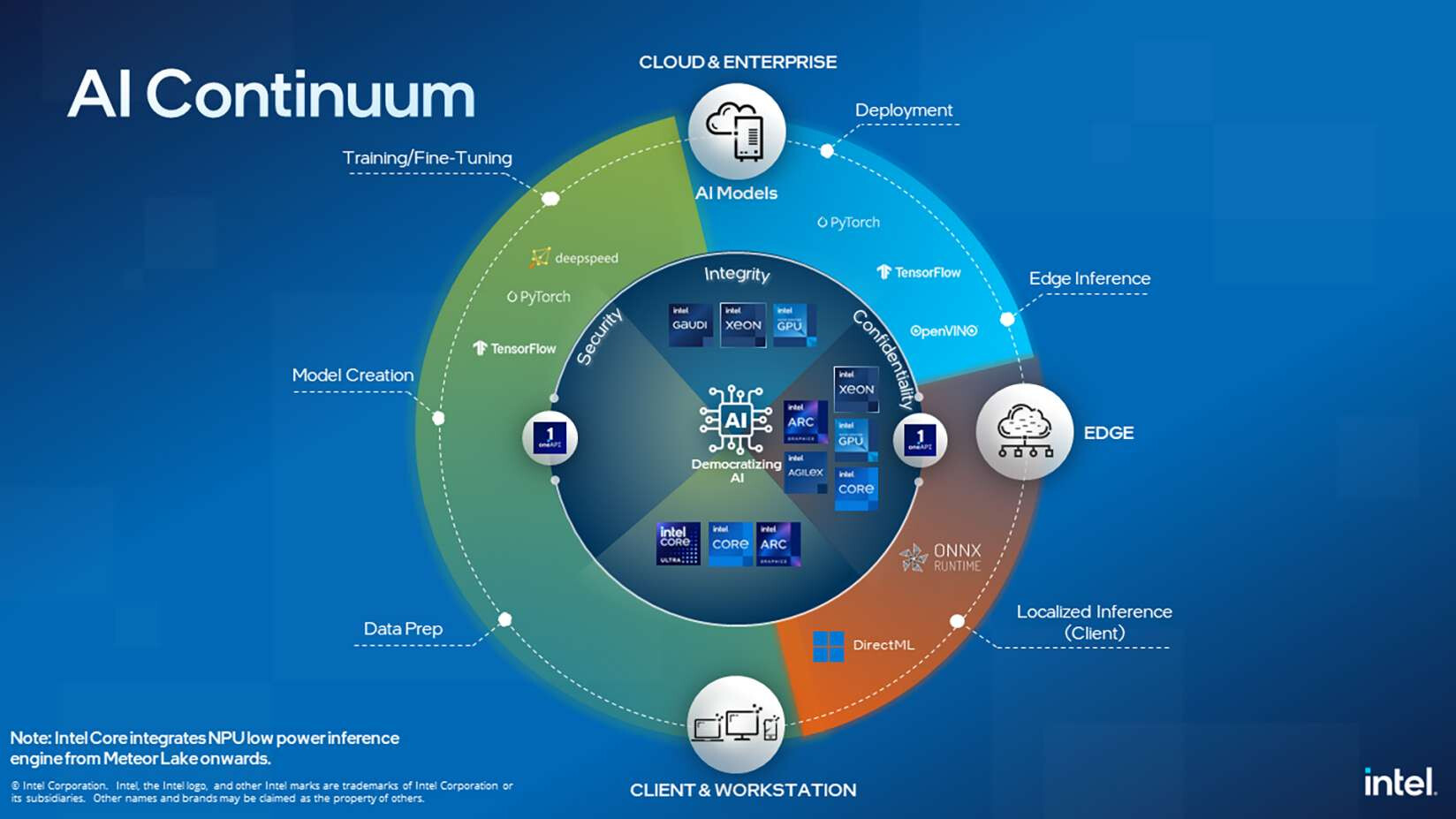
Intel Gaudi 2 Remains Only Benchmarked Alternative to NV H100 for Generative AI Performance
Today, MLCommons published results of the industry-standard MLPerf v4.0 benchmark for inference. Intel's results for Intel Gaudi 2 accelerators and 5th Gen Intel Xeon Scalable processors with Intel Advanced Matrix Extensions (Intel AMX) reinforce the company's commitment to bring "AI Everywhere" with a broad portfolio of competitive solutions. The Intel Gaudi 2 AI accelerator remains the only benchmarked alternative to Nvidia H100 for generative AI (GenAI) performance and provides strong performance-per-dollar. Further, Intel remains the only server CPU vendor to submit MLPerf results. Intel's 5th Gen Xeon results improved by an average of 1.42x compared with 4th Gen Intel Xeon processors' results in MLPerf Inference v3.1.
"We continue to improve AI performance on industry-standard benchmarks across our portfolio of accelerators and CPUs. Today's results demonstrate that we are delivering AI solutions that deliver to our customers' dynamic and wide-ranging AI requirements. Both Intel Gaudi and Xeon products provide our customers with options that are ready to deploy and offer strong price-to-performance advantages," said Zane Ball, Intel corporate vice president and general manager, DCAI Product Management.

"We continue to improve AI performance on industry-standard benchmarks across our portfolio of accelerators and CPUs. Today's results demonstrate that we are delivering AI solutions that deliver to our customers' dynamic and wide-ranging AI requirements. Both Intel Gaudi and Xeon products provide our customers with options that are ready to deploy and offer strong price-to-performance advantages," said Zane Ball, Intel corporate vice president and general manager, DCAI Product Management.