Intel "Sapphire Rapids" Xeon Processor Could Feature Up To 80 Cores: New Leak
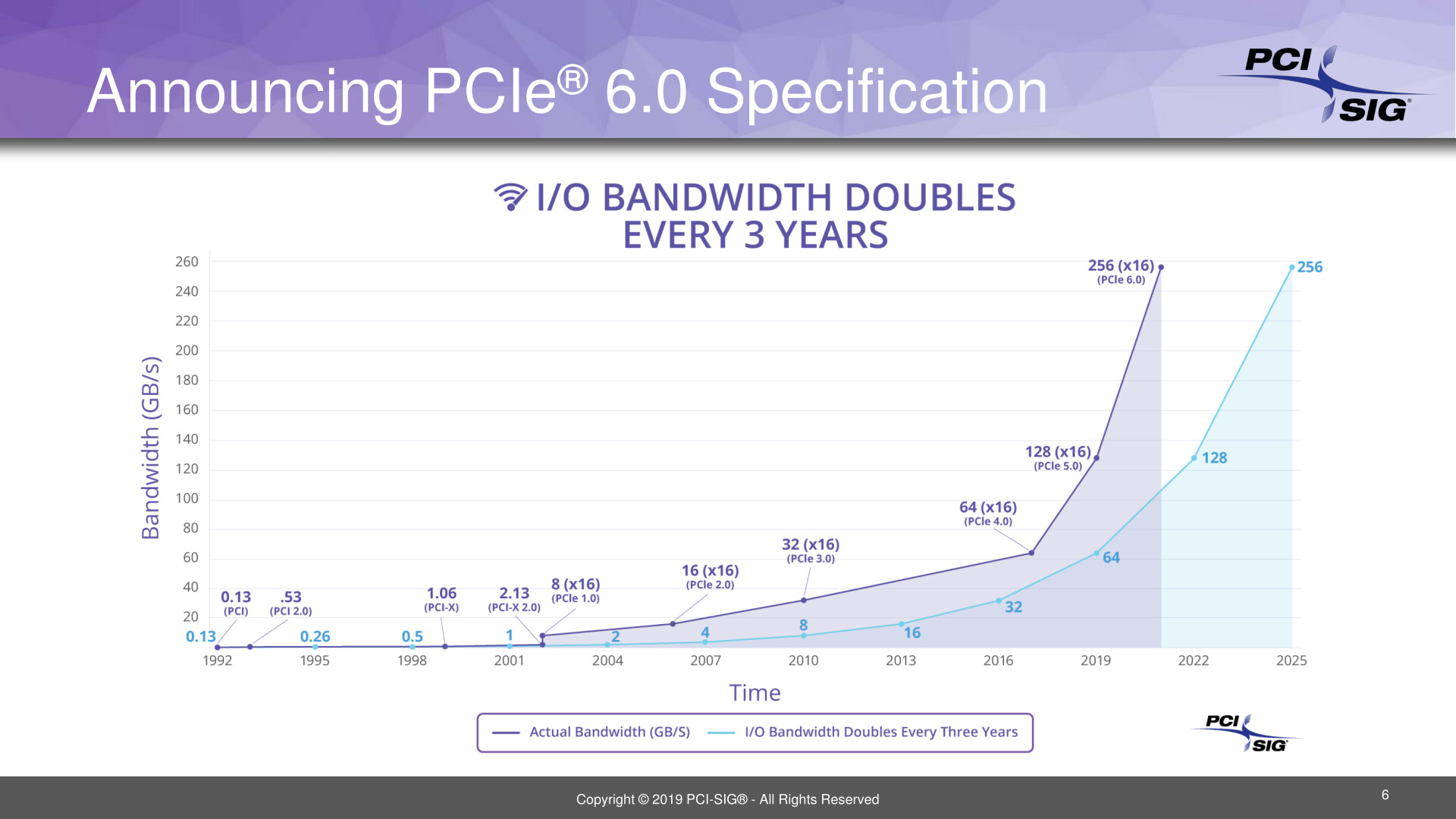
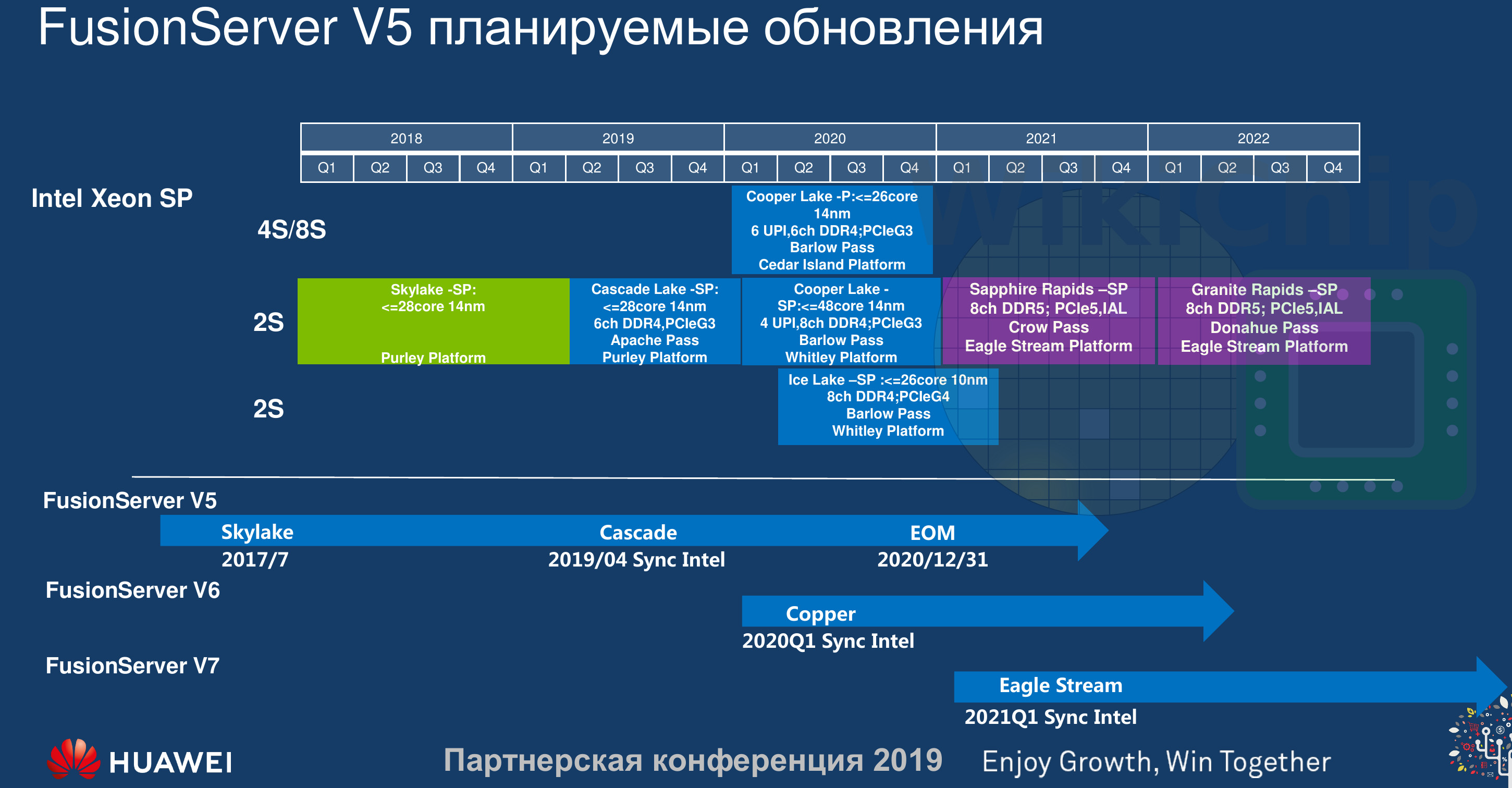
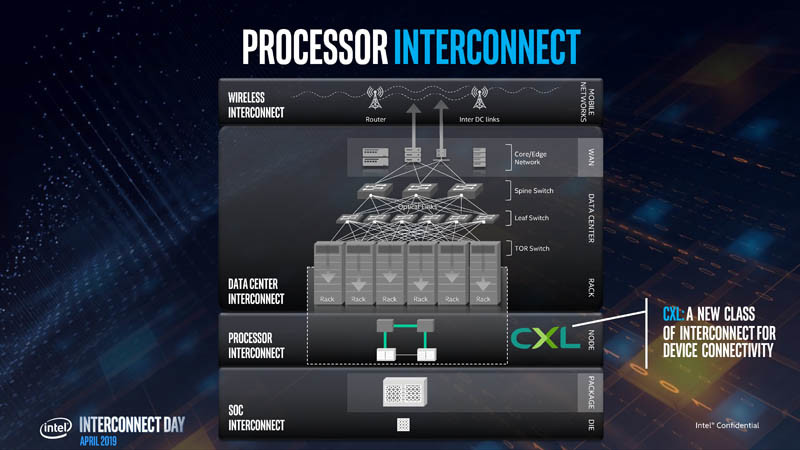
Intel's upcoming Xeon "Sapphire Rapids" enterprise processor come come with CPU core-counts as high as 80, according to the latest round of photo-leaks. An earlier article predicted the chip cram up to 56 cores alongside on-package HBM. The processor reportedly features up to 80 cores, spread across four 20-core chiplets. Unlike on the latest AMD EPYC processor, there doesn't appear to be a centralized I/O controller die. This particular processor is based in the LGA4189 package, which features additional pins compared to the LGA4577-X socket from the 56-core leak. The newer socket has additional pins that enable next-gen I/O, which include PCI-Express Gen 5.0, and CXL 1.1 interface.