NVIDIA Blackwell Platform Pushes the Boundaries of Scientific Computing
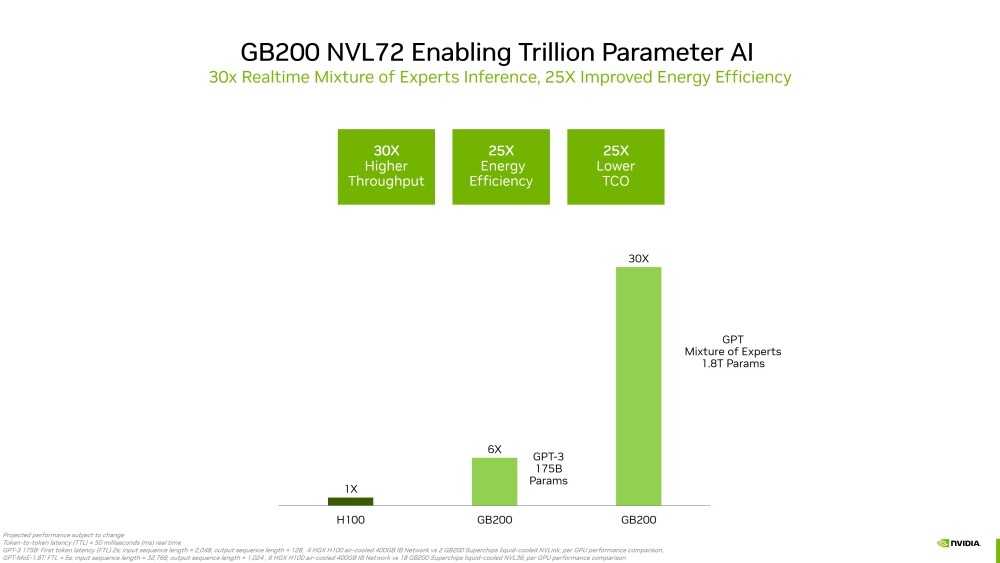
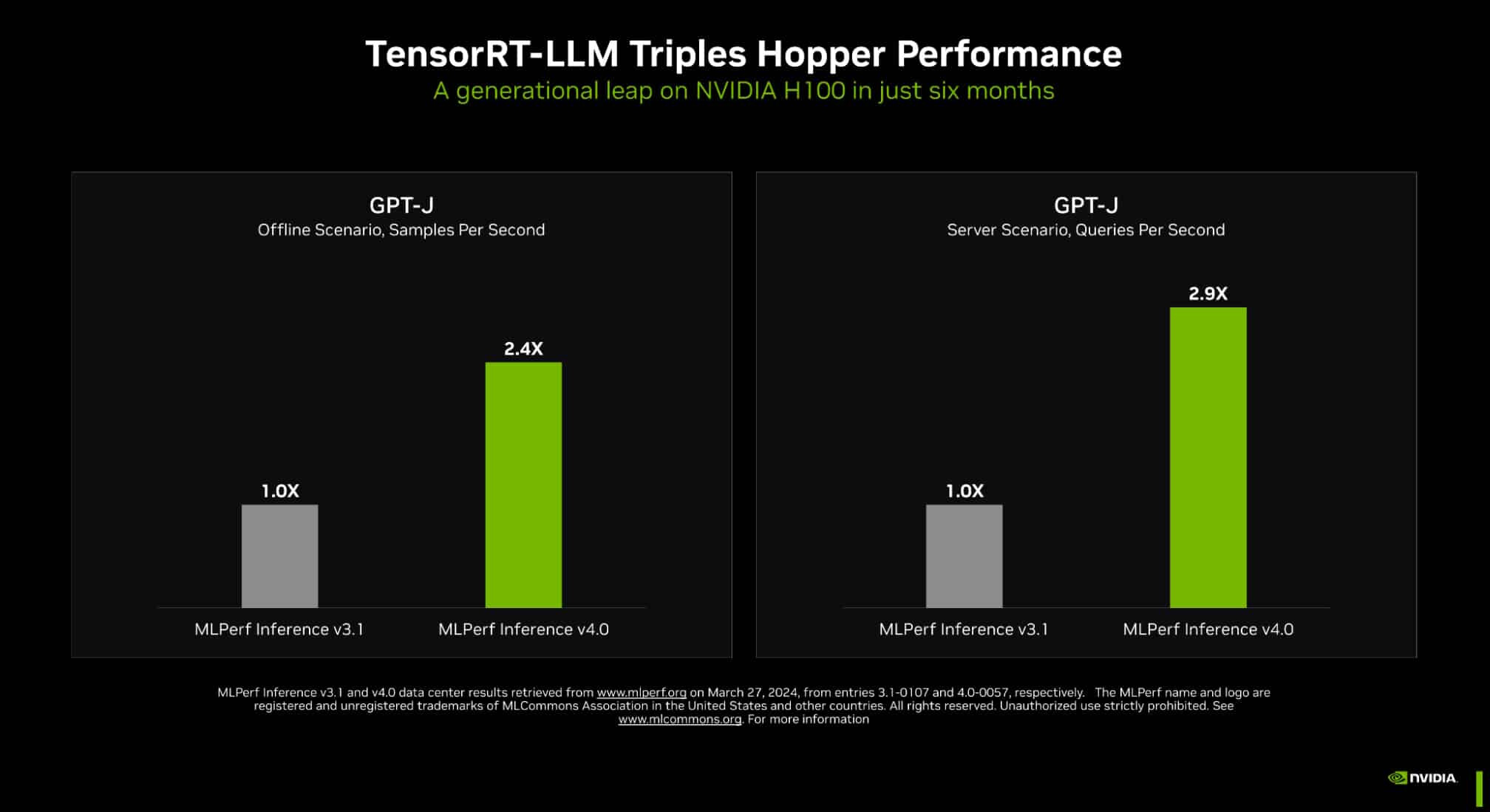
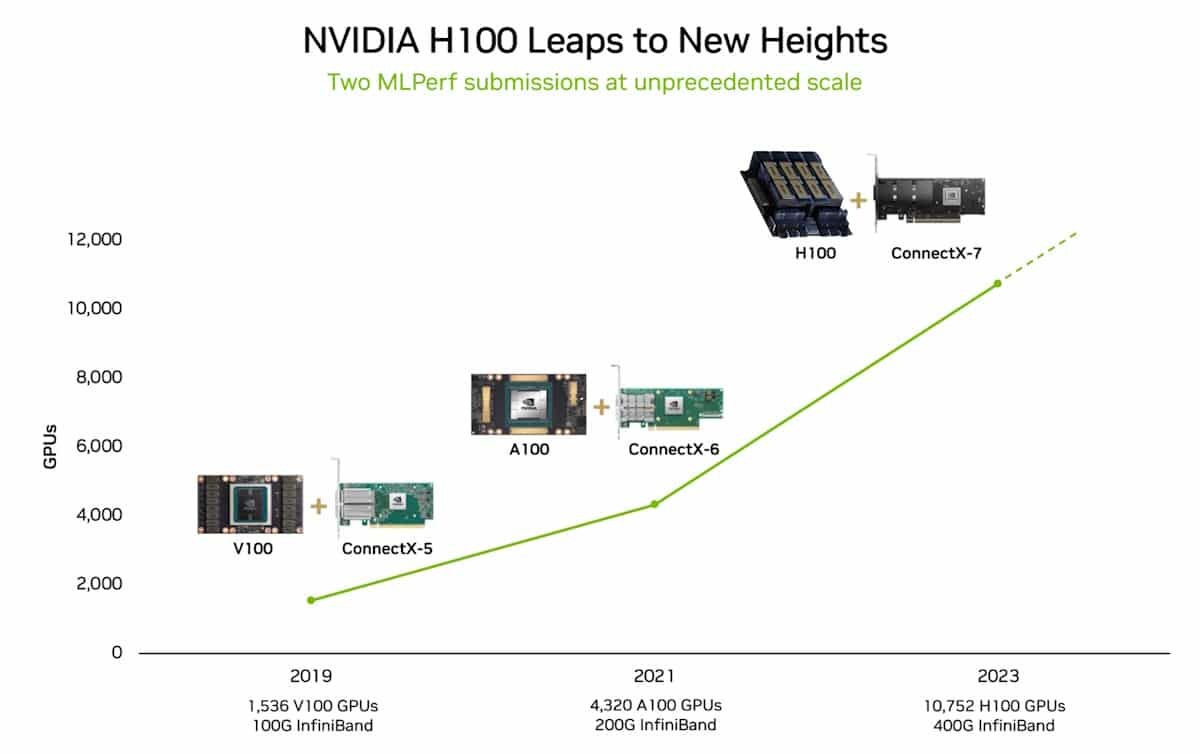
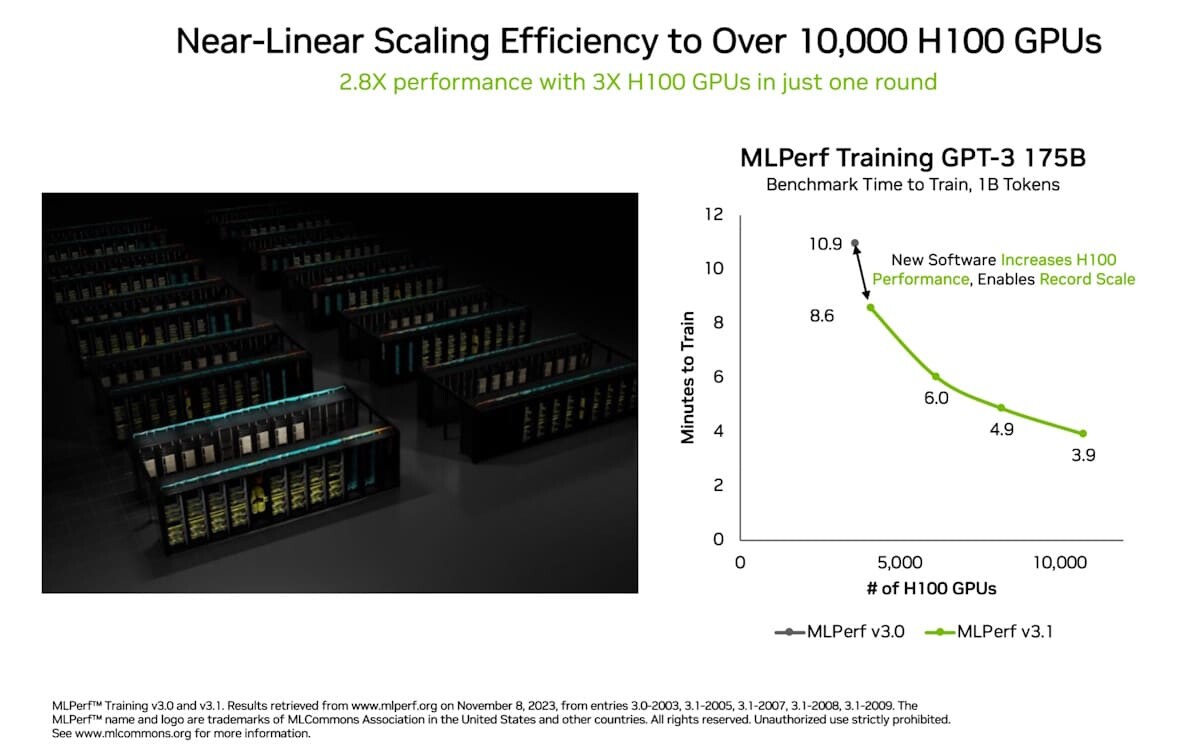
Quantum computing. Drug discovery. Fusion energy. Scientific computing and physics-based simulations are poised to make giant steps across domains that benefit humanity as advances in accelerated computing and AI drive the world's next big breakthroughs. NVIDIA unveiled at GTC in March the NVIDIA Blackwell platform, which promises generative AI on trillion-parameter large language models (LLMs) at up to 25x less cost and energy consumption than the NVIDIA Hopper architecture.
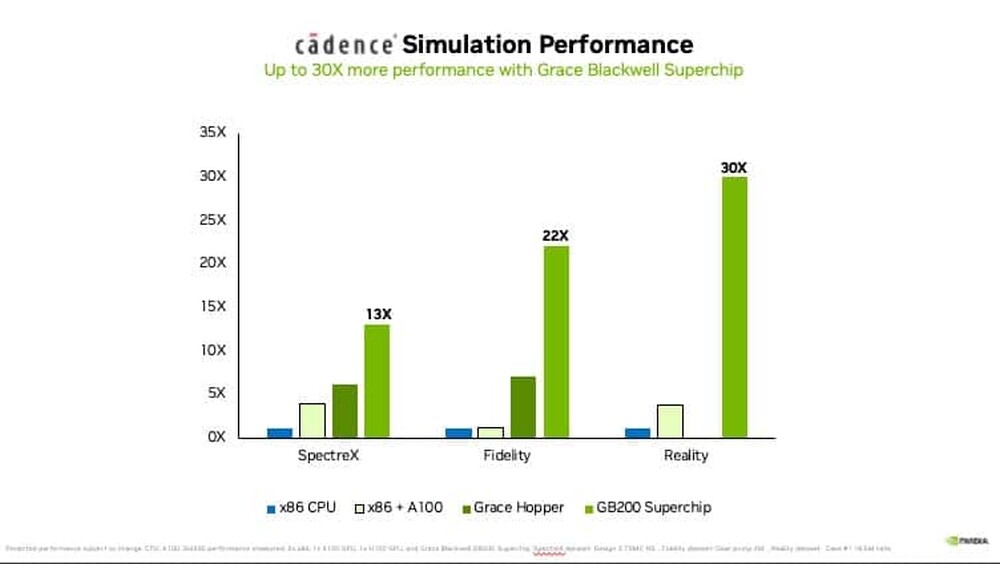
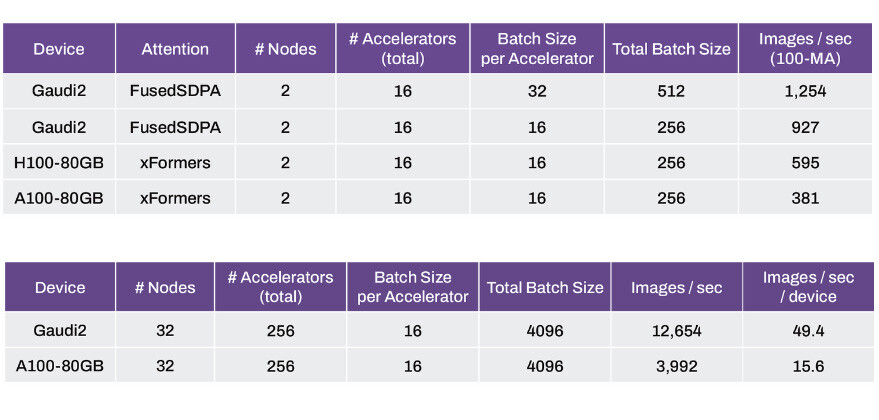
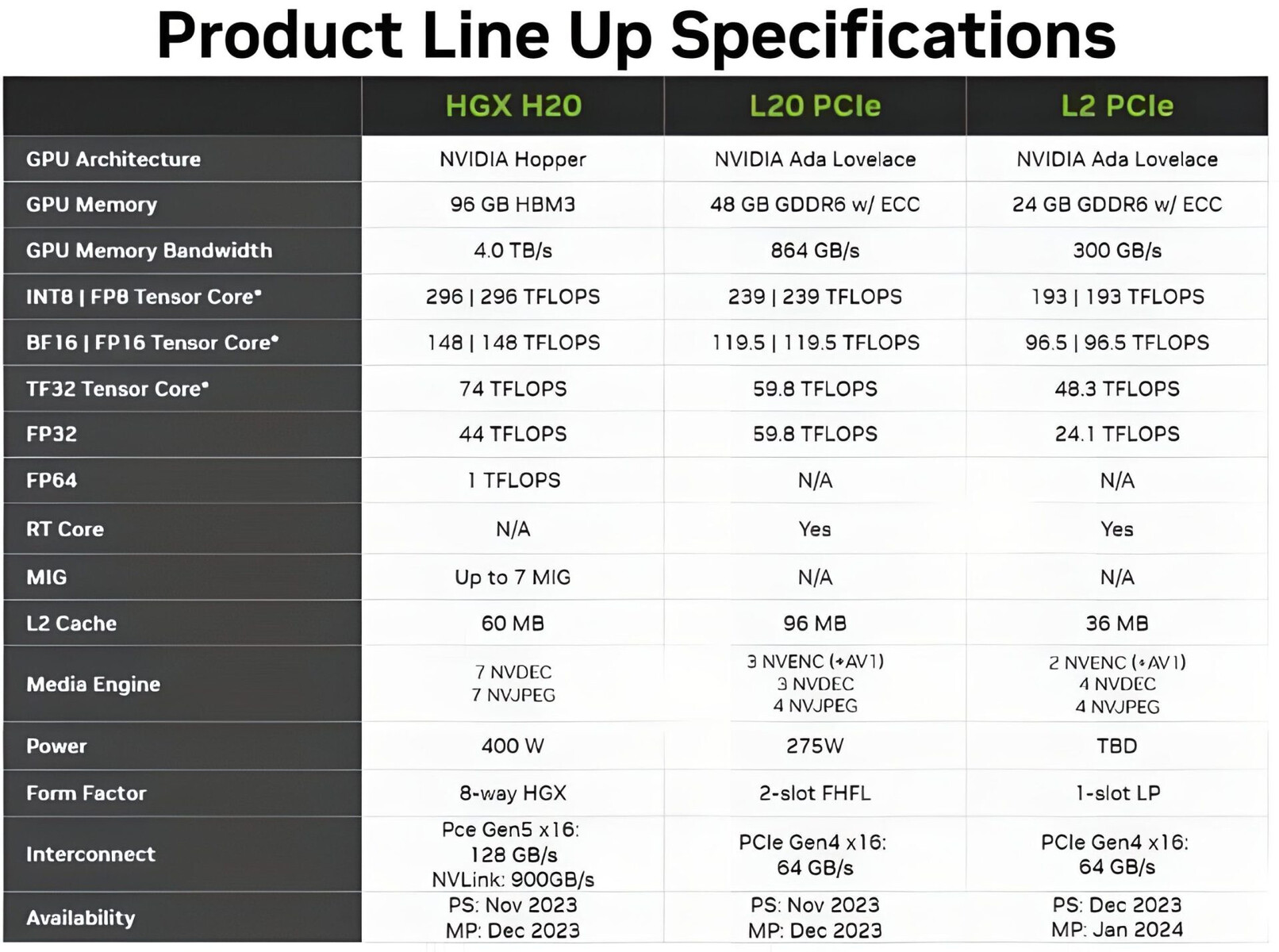
Blackwell has powerful implications for AI workloads, and its technology capabilities can also help to deliver discoveries across all types of scientific computing applications, including traditional numerical simulation. By reducing energy costs, accelerated computing and AI drive sustainable computing. Many scientific computing applications already benefit. Weather can be simulated at 200x lower cost and with 300x less energy, while digital twin simulations have 65x lower cost and 58x less energy consumption versus traditional CPU-based systems and others.



Blackwell has powerful implications for AI workloads, and its technology capabilities can also help to deliver discoveries across all types of scientific computing applications, including traditional numerical simulation. By reducing energy costs, accelerated computing and AI drive sustainable computing. Many scientific computing applications already benefit. Weather can be simulated at 200x lower cost and with 300x less energy, while digital twin simulations have 65x lower cost and 58x less energy consumption versus traditional CPU-based systems and others.