Xilinx Announces World's Highest Bandwidth, Highest Compute Density Adaptable Platform for Network and Cloud Acceleration
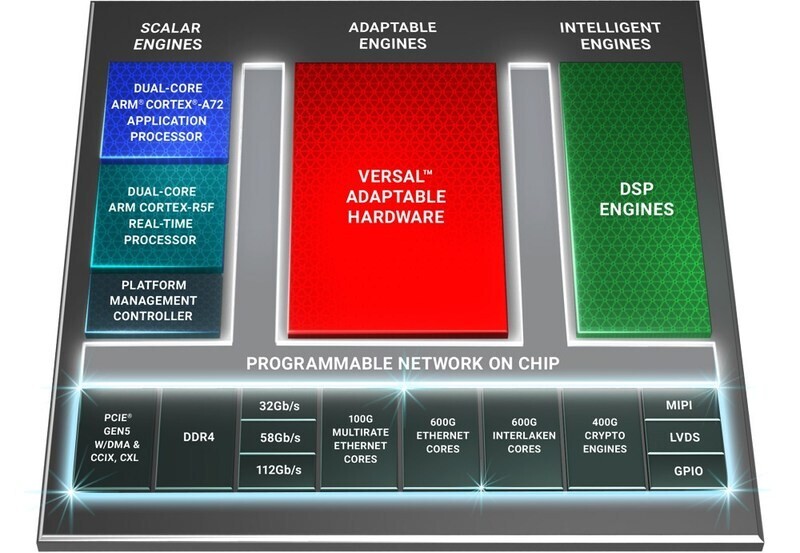
Xilinx, Inc. today announced Versal Premium, the third series in the Versal ACAP portfolio. The Versal Premium series features highly integrated, networked and power-optimized cores and the industry's highest bandwidth and compute density on an adaptable platform. Versal Premium is designed for the highest bandwidth networks operating in thermally and spatially constrained environments, as well as for cloud providers who need scalable, adaptable application acceleration.
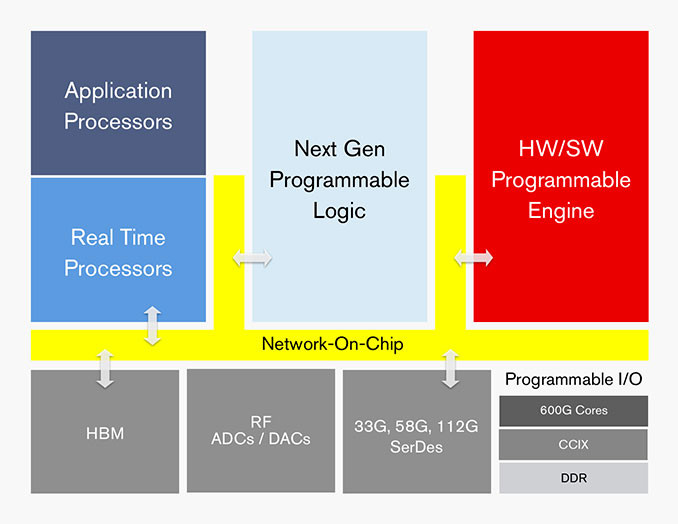
Versal is the industry's first adaptive compute acceleration platform (ACAP), a revolutionary new category of heterogeneous compute devices with capabilities that far exceed those of conventional silicon architectures. Developed on TSMC's 7-nanometer process technology, Versal Premium combines software programmability with dynamically configurable hardware acceleration and pre-engineered connectivity and security features to enable a faster time-to-market. The Versal Premium series delivers up to 3X higher throughput compared to current generation FPGAs, with built-in Ethernet, Interlaken, and cryptographic engines that enable fast and secure networks. The series doubles the compute density of currently deployed mainstream FPGAs and provides the adaptability to keep pace with increasingly diverse and evolving cloud and networking workloads.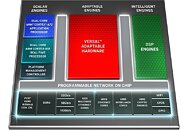
Versal is the industry's first adaptive compute acceleration platform (ACAP), a revolutionary new category of heterogeneous compute devices with capabilities that far exceed those of conventional silicon architectures. Developed on TSMC's 7-nanometer process technology, Versal Premium combines software programmability with dynamically configurable hardware acceleration and pre-engineered connectivity and security features to enable a faster time-to-market. The Versal Premium series delivers up to 3X higher throughput compared to current generation FPGAs, with built-in Ethernet, Interlaken, and cryptographic engines that enable fast and secure networks. The series doubles the compute density of currently deployed mainstream FPGAs and provides the adaptability to keep pace with increasingly diverse and evolving cloud and networking workloads.