Sony PlayStation 5 Pro Specifications Confirmed, Console Arrives Before Holidays
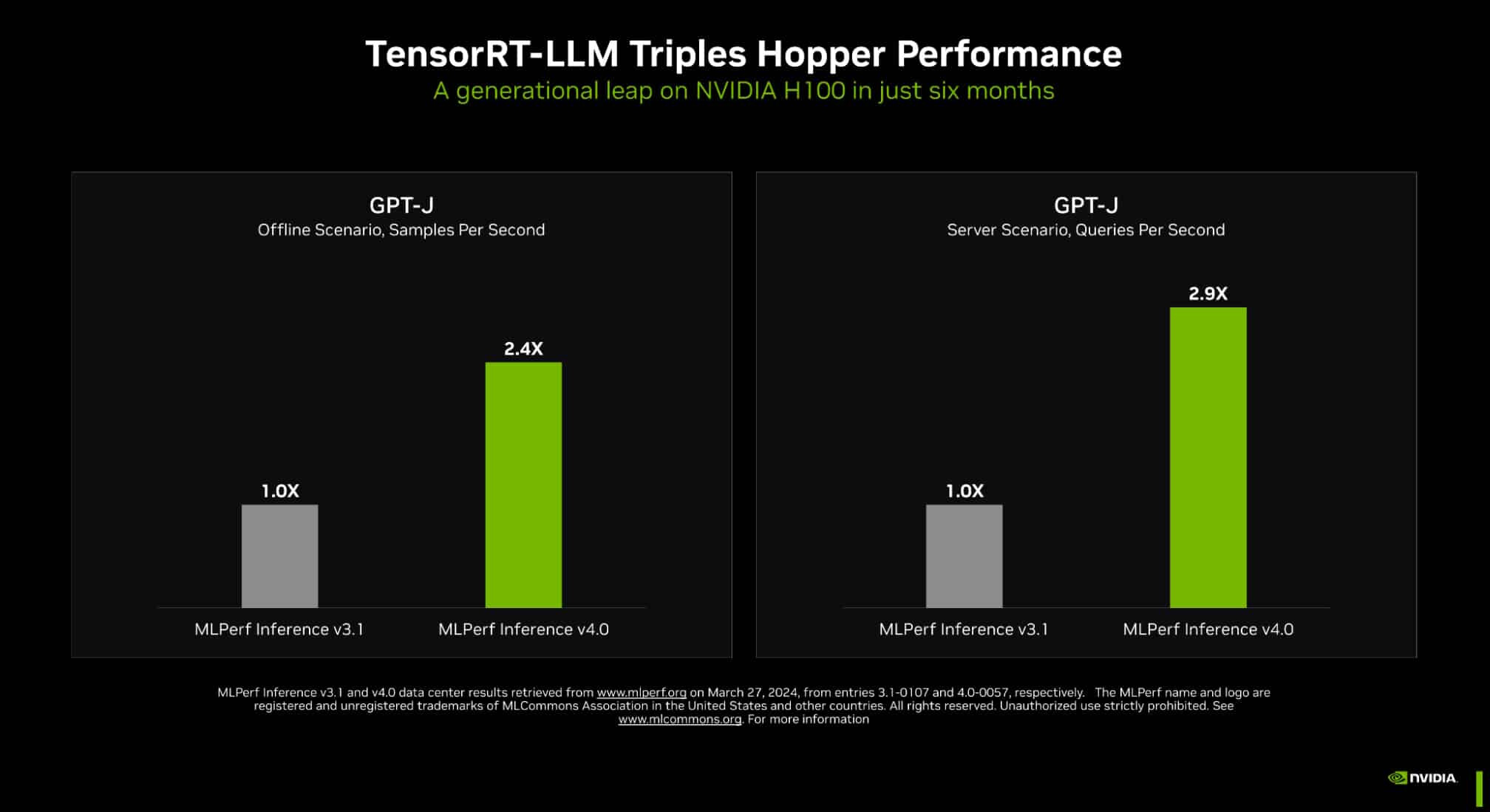
Thanks for the detailed information obtained by The Verge, today we confirm previously leaked details as Sony gears up to unveil the highly anticipated PlayStation 5 Pro, codenamed "Trinity." According to insider reports, Sony is urging developers to optimize their games for the PS5 Pro, with a primary focus on enhancing ray tracing capabilities. The console is expected to feature an RDNA 3 GPU with 30 WGP running BVH8, capable of 33.5 TeraFLOPS of FP32 single-precision computing power, and a slightly quicker CPU running at 3.85 GHz, enabling it to render games with ray tracing enabled or achieve higher resolutions and frame rates in select titles. Sony anticipates GPU rendering on the PS5 Pro to be approximately 45 percent faster than the standard PlayStation 5. The PS5 Pro GPU will be larger and utilize faster system memory to bolster ray tracing performance, boasting up to three times the speed of the regular PS5.
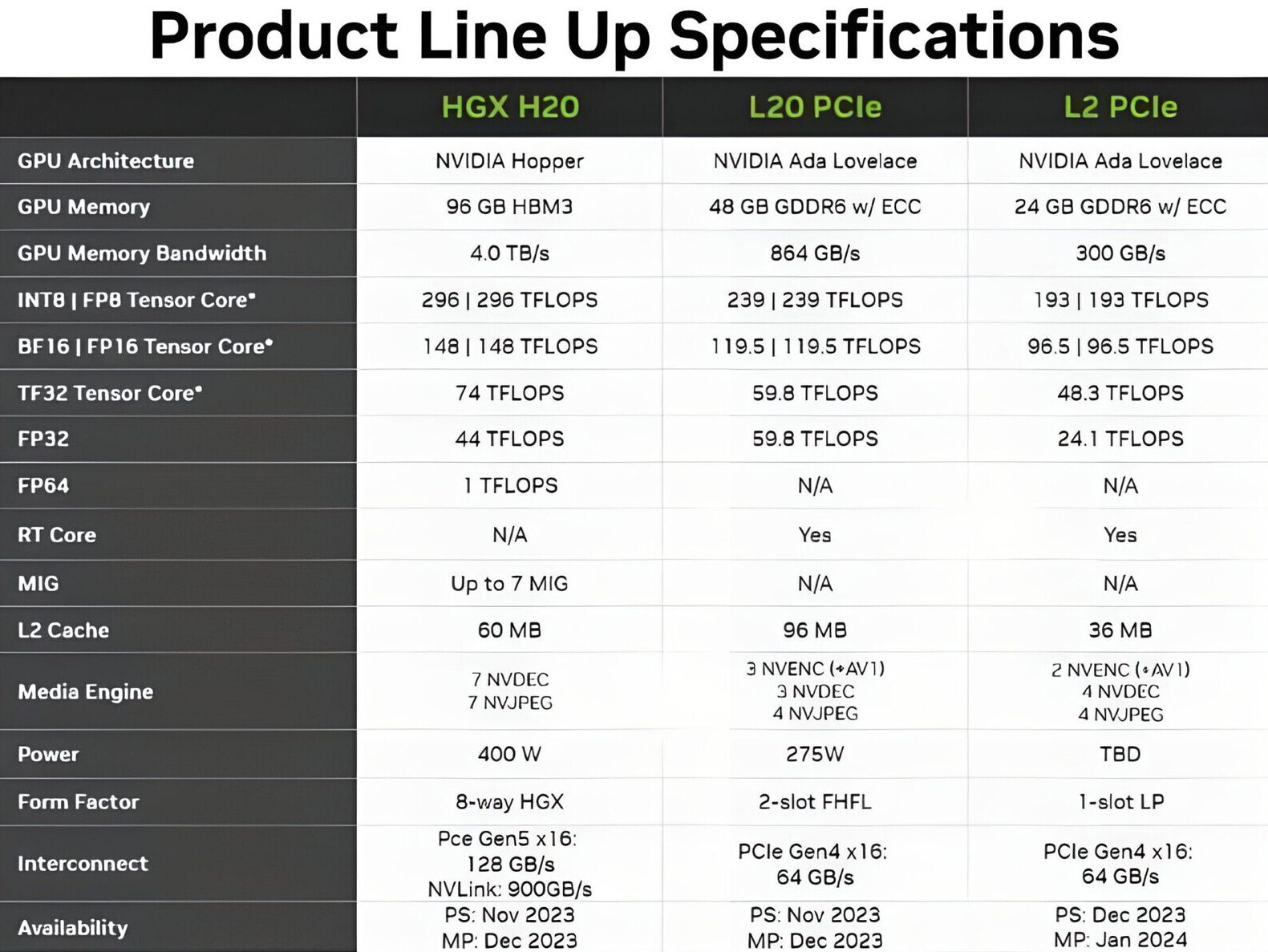
Additionally, the console will employ a more powerful ray tracing architecture, backed by PlayStation Spectral Super Resolution (PSSR), allowing developers to leverage graphics features like ray tracing more extensively. To support this endeavor, Sony is providing developers with test kits, and all games submitted for certification from August onward must be compatible with the PS5 Pro. Insider Gaming, the first to report the full PS5 Pro specs, suggests a potential release during the 2024 holiday period. The PS5 Pro will also feature modifications for developers regarding system memory, with Sony increasing the memory bandwidth from 448 GB/s to 576 GB/s, enhancing efficiency for an even more immersive gaming experience. To do AI processing, there is an custom AI accelerator capable of 300 8-bit INT8 TOPS and 67 16-bit FP16 TeraFLOPS, in addition to ACV audio codec running up to 35% faster.

Additionally, the console will employ a more powerful ray tracing architecture, backed by PlayStation Spectral Super Resolution (PSSR), allowing developers to leverage graphics features like ray tracing more extensively. To support this endeavor, Sony is providing developers with test kits, and all games submitted for certification from August onward must be compatible with the PS5 Pro. Insider Gaming, the first to report the full PS5 Pro specs, suggests a potential release during the 2024 holiday period. The PS5 Pro will also feature modifications for developers regarding system memory, with Sony increasing the memory bandwidth from 448 GB/s to 576 GB/s, enhancing efficiency for an even more immersive gaming experience. To do AI processing, there is an custom AI accelerator capable of 300 8-bit INT8 TOPS and 67 16-bit FP16 TeraFLOPS, in addition to ACV audio codec running up to 35% faster.