 140
140
NVIDIA GeForce GF100 Architecture Review
Geometry Processing & Tessellation »The NVIDIA GF100 GPU
NVIDIA's first consumer graphics implementation of its Fermi architecture is the GF100 graphics processor (GPU). Based on this, NVIDIA along with its partners may release one or two graphics card SKUs. A dual-GPU graphics board cannot be written off, either but is certainly not expected for launch. The GF100 is expected to be a ≥100% leap over the previous-generation GT200, in terms of raw compute power, transistor count, and the quantity and capability of various components within the GPU. It will be manufactured on TSMC's 40 nanometer silicon fabrication node.The GPU has the following physical specifications compared to existing GPU architectures from the present and previous generations:
| AMD Cypress | AMD RV790 | NVIDIA G92 | NVIDIA GT200 | NVIDIA GF100 | |
| Shader units | 1600 | 800 | 128 | 240 | 512 |
| ROPs | 32 | 16 | 16 | 32 | 48 |
| Texture Units | 80 | 40 | 64 | 80 | 64 |
| DirectX | 11 | 10.1 | 10 | 10 | 11 |
| Transistors | 2154M | 959M | 754M | 1400M | 3200M |
| Memory Type | GDDR5 | GDDR5 | GDDR3 | GDDR3 | GDDR5 |
| Memory Bus Width | 256 bit | 256 bit | 256 bit | 512 bit | 384 bit |
As you can see, NVIDIA gave the GF100 numerically a 115% increase in shader processors (now called "CUDA Cores" due to the versatility they have achieved beyond shading), a 50% increase in memory bandwidth compared to the GT200 (keeping memory clock speeds constant).

The GPU is organized in a manner described in the block diagram above. The Gigathread Engine acts as a complex crossbar that distributes workload between the highly parallel GPU components. A 384-bit GDDR5 memory controller connects the GPU to 12 memory chips, with an estimated 1536 MB (1.5 GB) or 3072 MB (3.0 GB) of memory, depending on the density of the memory chips used. It is also expected that we will see lower-end configurations with reduced number of memory chips, for example resulting in 256-bit cards with 1 GB of VRAM or 320 bit / 1280 MB. The processing complex of the GPU is arranged into four Graphics Processing Clusters, or GPCs (helps in modularity, combines four Streaming Multiprocessors or SMs to a raster engine), each GPC has a raster engine and four SMs (a sub-unit, combines 32 CUDA cores to common instruction and L1 caches, and a Polymorph Engine), each SM further has four texture mapping units (TMUs).

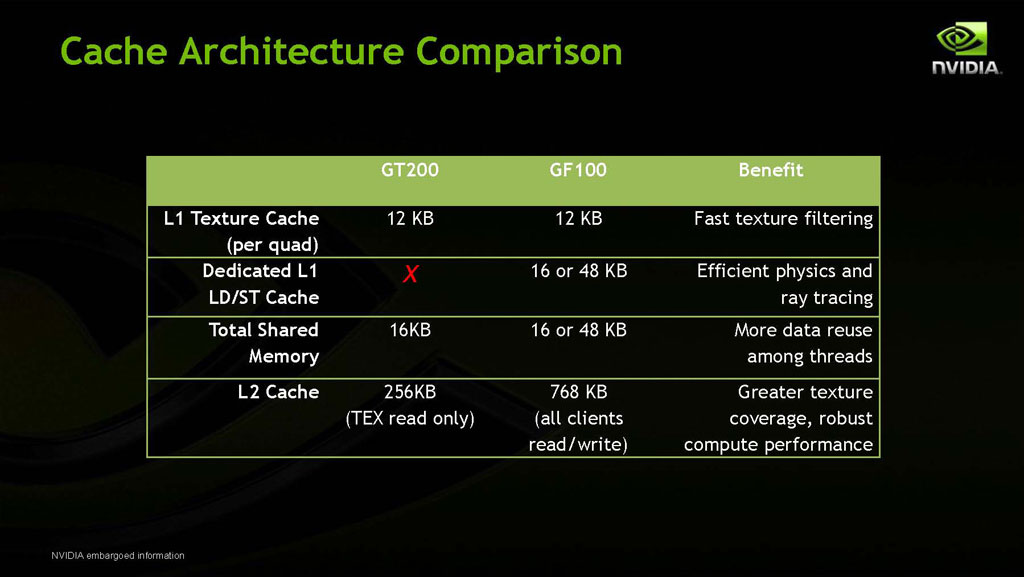
The level of parallelism is supported by caches at every level, which help manage data traffic, and let key instructions and data stay on the chip. There are shared 64 KB L1 caches on every SM, and a large 768 KB L2 cache for vertex, texture, and ROP data, among other general purpose functions. The 64 KB of L1 cache can be configured to be either 48 KB of shared memory and 16 KB of L1 cache or 48 KB of L1 cache with 16 KB shared memory - depending on the application.
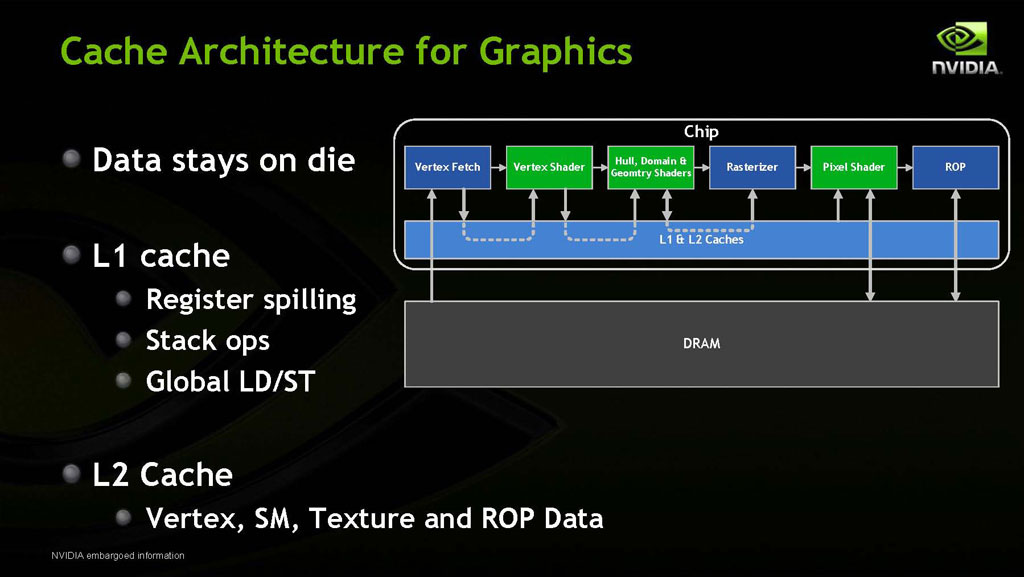
Unlike competing GPUs with unified tessellators, NVIDIA's approach to tessellation involves distributing it among the 16 SMs using PolyMorph Engines. Each PolyMorph Engine gives the SM its own tessellator. Every GPC has its own Raster Engine. This hierarchy gives the GF100 a theoretical 8-times increase in geometry performance compared to the GT200, by decentralizing these components with a parallel architecture.

Apr 11th, 2025 17:25 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Bios RX 570 (16)
- Post your cooling. (226)
- X79 and/or rampage IV OC'ing thread for those of us still left.... (2391)
- The TPU UK Clubhouse (26083)
- Show us your backside! (31)
- Deal or no Deal Threadripper WX? (4)
- TPU's Nostalgic Hardware Club (20231)
- What's your latest tech purchase? (23520)
- Is there potential for AMD to change the world with this x3D technology combined with gallium cooling techniques? (3)
- Soyo RX 580 8G 2048SP problem (1)
Popular Reviews
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- Thermaltake TR100 Review
- ASRock Z890 Taichi OCF Review
- Zotac GeForce RTX 5070 Ti Amp Extreme Review
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Acer Predator GM9000 2 TB Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- TerraMaster F8 SSD Plus Review - Compact and quiet
- PowerColor Radeon RX 9070 Hellhound Review
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (180)
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- Microsoft Introduces Copilot for Gaming (124)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (112)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (104)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)