- Joined
- Oct 9, 2007
- Messages
- 47,244 (7.55/day)
- Location
- Hyderabad, India
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | ASUS ROG Strix B450-E Gaming |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 8GB G.Skill Sniper X |
| Video Card(s) | Palit GeForce RTX 2080 SUPER GameRock |
| Storage | Western Digital Black NVMe 512GB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
It looks like NVIDIA's first response to the GeForce GTX 970 memory allocation controversy clearly came from engineers who were pulled out of their weekend plans, and hence was too ambiguously technical (even for us). It's only on Monday that NVIDIA PR swung into action, offering a more user-friendly explanation on what the GTX 970 issue is, and how exactly did they carve the GM204 up, when creating the card.
According to an Anandtech report, which cites that easy explanation from NVIDIA, the company was not truthful about specs of GTX 970, at launch. For example, the non-public document NVIDIA gave out to reviewers (which gives them detailed tech-specs), had clearly mentioned ROP count of the GTX 970 to be 64. Reviewers used that count in their reviews. TechPowerUp GPU-Z shows ROP count as reported by the driver, but it has no way of telling just how many of those "enabled" ROPs are "active." The media reviewing the card were hence led to believe that the GTX 970 was carved out by simply disabling three out of sixteen streaming multiprocessors (SMMs), the basic indivisible subunits of the GM204 chip, with no mention of other components like the ROP count, and L2 cache amount being changed from the GTX 980 (a full-fledged implementation of this silicon).
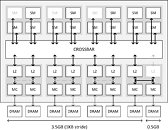
NVIDIA explained to Anandtech that there was a communication-gap between the engineers (the people who designed the GTX 970 ASIC), and the technical marketing team (the people who write the Reviewer's Guide document, and draw the block-diagram). This team was unaware that with "Maxwell," you could segment components previously thought indivisible, or that you could "partial disable" components.
It turns out that in addition to three SMX units being disabled (resulting in 1,664 CUDA cores), NVIDIA reduced the L2 cache (last-level cache) on this chip to 1.75 MB, down from 2 MB, and also disabled a few ROPs. The ROP count is effectively 56, and not 64. The last 8 ROPs aren't "disabled." They're active, but not used, because their connection to the crossbar is too slow (we'll get to that in a bit). The L2 cache is a key component of the "crossbar." Think of the crossbar as a town-square for the GPU, where the various components of the GPU talk to each other by leaving and picking-up data labeled with "from" and "to" addresses. The crossbar routes data between the four Graphics Processing Clusters (GPCs), and the eight memory controllers of 64-bit bus width each (which together make up its 256-bit wide memory interface), and is cushioned by the L2 cache.
The L2 cache itself is segmented, and isn't a monolithic slab of SRAM. Each of the eight memory controllers on the GM204 is ideally tied to its segment of the L2 cache. Also tied to these segments are segments of ROPs. With NVIDIA reducing the L2 cache amount by disabling one such segment. Its component memory controller is instead rerouted to the cache segment of a neighbouring memory controller. Access to the crossbar for that memory controller is hence slower. To make sure there are no issues caused to the interleaving of these memory controllers, adding up to the big memory amount figure that the driver can address, NVIDIA partitioned the 4 GB of memory to two segments. The first is 3.5 GB large, and is made up of memory controllers with access to their own segments of the L2; the second segment is 512 MB in size, and is tied to that memory controller which is rerouted.
The way this partitioning works, is that the 3.5 GB partition can't be read while the 512 MB one is being read. Only to an app that's actively using the entire 4 GB of memory, there will be a drop in performance, because the two segments aren't being read at the same time. The GPU is either addressing the 3.5 GB segment, or the 512 MB one. Hence, there's a drop in performance to be expected, again, for apps that use up the entire 4 GB of memory.
While it's technically correct that the GTX 970 has a 256-bit wide memory interface, and given its 7.00 GHz (GDDR5-effective) memory clock, that translates to 224 GB/s of bandwidth on paper, not all of that memory is uniformly fast. You have 3.5 GB of it having normal access to the crossbar (the town-square of the GPU), and 512 MB of it having slower access. Therefore, the 3.5 GB segment really just has 196 GB/s of memory bandwidth (7.00 GHz x 7 ways to reach the crossbar x 32-bit width per chip), which can be said with certainty. Nor can we say how this segment affects the performance of the memory controller whose crossbar port it's using, if the card is using its full 4 GB. We can't tell how fast the 512 MB second segment really is. But it's impossible for the second segment to make up 28 GB/s (of the 224 GB/s), since NVIDIA itself claims this segment is running slower. Therefore NVIDIA's claims of GTX 970 memory bandwidth being 224 GB/s at reference clocks is inaccurate.
Why NVIDIA chose to reduce cache size and ROP count will remain a mystery. We can't imagine that the people designing the chip will not have sufficiently communicated this to the driver and technical marketing teams. To claim that technical marketing didn't get this the first time around, seems like a hard-sell. We're pretty sure that NVIDIA engineers read reviews, and if they saw "64 ROPs" on a first-page table, they would have reported it up the food-chain at NVIDIA. An explanation about this hardware change should have taken up an entire page in the technical documents the first time around, and NVIDIA could have saved itself a lot of explanation, much of it through the press.
View at TechPowerUp Main Site
According to an Anandtech report, which cites that easy explanation from NVIDIA, the company was not truthful about specs of GTX 970, at launch. For example, the non-public document NVIDIA gave out to reviewers (which gives them detailed tech-specs), had clearly mentioned ROP count of the GTX 970 to be 64. Reviewers used that count in their reviews. TechPowerUp GPU-Z shows ROP count as reported by the driver, but it has no way of telling just how many of those "enabled" ROPs are "active." The media reviewing the card were hence led to believe that the GTX 970 was carved out by simply disabling three out of sixteen streaming multiprocessors (SMMs), the basic indivisible subunits of the GM204 chip, with no mention of other components like the ROP count, and L2 cache amount being changed from the GTX 980 (a full-fledged implementation of this silicon).
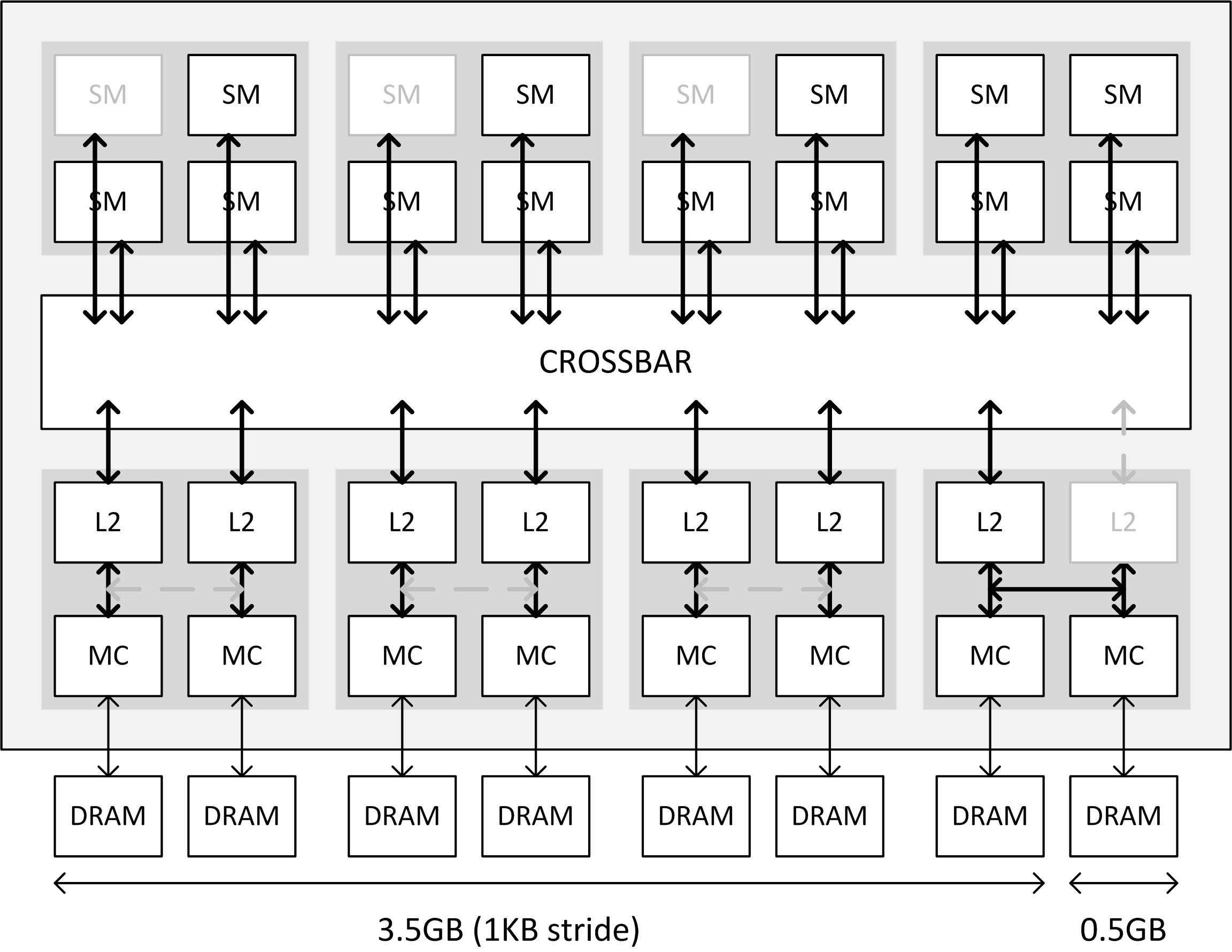

NVIDIA explained to Anandtech that there was a communication-gap between the engineers (the people who designed the GTX 970 ASIC), and the technical marketing team (the people who write the Reviewer's Guide document, and draw the block-diagram). This team was unaware that with "Maxwell," you could segment components previously thought indivisible, or that you could "partial disable" components.
It turns out that in addition to three SMX units being disabled (resulting in 1,664 CUDA cores), NVIDIA reduced the L2 cache (last-level cache) on this chip to 1.75 MB, down from 2 MB, and also disabled a few ROPs. The ROP count is effectively 56, and not 64. The last 8 ROPs aren't "disabled." They're active, but not used, because their connection to the crossbar is too slow (we'll get to that in a bit). The L2 cache is a key component of the "crossbar." Think of the crossbar as a town-square for the GPU, where the various components of the GPU talk to each other by leaving and picking-up data labeled with "from" and "to" addresses. The crossbar routes data between the four Graphics Processing Clusters (GPCs), and the eight memory controllers of 64-bit bus width each (which together make up its 256-bit wide memory interface), and is cushioned by the L2 cache.
The L2 cache itself is segmented, and isn't a monolithic slab of SRAM. Each of the eight memory controllers on the GM204 is ideally tied to its segment of the L2 cache. Also tied to these segments are segments of ROPs. With NVIDIA reducing the L2 cache amount by disabling one such segment. Its component memory controller is instead rerouted to the cache segment of a neighbouring memory controller. Access to the crossbar for that memory controller is hence slower. To make sure there are no issues caused to the interleaving of these memory controllers, adding up to the big memory amount figure that the driver can address, NVIDIA partitioned the 4 GB of memory to two segments. The first is 3.5 GB large, and is made up of memory controllers with access to their own segments of the L2; the second segment is 512 MB in size, and is tied to that memory controller which is rerouted.
The way this partitioning works, is that the 3.5 GB partition can't be read while the 512 MB one is being read. Only to an app that's actively using the entire 4 GB of memory, there will be a drop in performance, because the two segments aren't being read at the same time. The GPU is either addressing the 3.5 GB segment, or the 512 MB one. Hence, there's a drop in performance to be expected, again, for apps that use up the entire 4 GB of memory.
While it's technically correct that the GTX 970 has a 256-bit wide memory interface, and given its 7.00 GHz (GDDR5-effective) memory clock, that translates to 224 GB/s of bandwidth on paper, not all of that memory is uniformly fast. You have 3.5 GB of it having normal access to the crossbar (the town-square of the GPU), and 512 MB of it having slower access. Therefore, the 3.5 GB segment really just has 196 GB/s of memory bandwidth (7.00 GHz x 7 ways to reach the crossbar x 32-bit width per chip), which can be said with certainty. Nor can we say how this segment affects the performance of the memory controller whose crossbar port it's using, if the card is using its full 4 GB. We can't tell how fast the 512 MB second segment really is. But it's impossible for the second segment to make up 28 GB/s (of the 224 GB/s), since NVIDIA itself claims this segment is running slower. Therefore NVIDIA's claims of GTX 970 memory bandwidth being 224 GB/s at reference clocks is inaccurate.
Why NVIDIA chose to reduce cache size and ROP count will remain a mystery. We can't imagine that the people designing the chip will not have sufficiently communicated this to the driver and technical marketing teams. To claim that technical marketing didn't get this the first time around, seems like a hard-sell. We're pretty sure that NVIDIA engineers read reviews, and if they saw "64 ROPs" on a first-page table, they would have reported it up the food-chain at NVIDIA. An explanation about this hardware change should have taken up an entire page in the technical documents the first time around, and NVIDIA could have saved itself a lot of explanation, much of it through the press.
View at TechPowerUp Main Site






 .5GB and >3.5GB were almost identical in the performance hit on both the 980 and the 970. If that is true, then someone is still lying.
.5GB and >3.5GB were almost identical in the performance hit on both the 980 and the 970. If that is true, then someone is still lying.")
