- Joined
- Oct 9, 2007
- Messages
- 47,417 (7.51/day)
- Location
- Hyderabad, India
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | ASUS ROG Strix B450-E Gaming |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 8GB G.Skill Sniper X |
| Video Card(s) | Palit GeForce RTX 2080 SUPER GameRock |
| Storage | Western Digital Black NVMe 512GB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
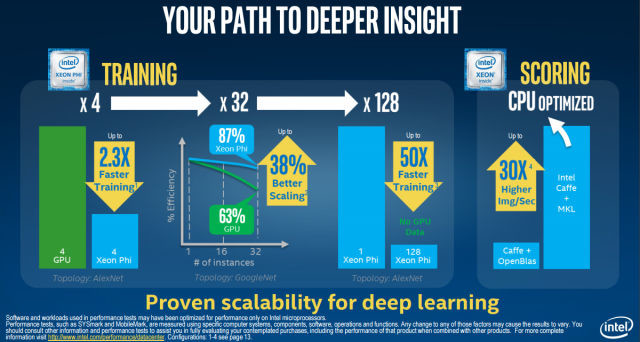
NVIDIA accused Intel of cheating in its ISC 2016 presentation, particularly in a performance-related slide, in which it claimed that its "Knights Landing" Xeon Phi HPC processor provides faster training of neural nets than NVIDIA "Maxwell" GPUs. In a slide, Intel claimed that a Xeon Phi HPC processor card is 2.3 times faster at training deep-learning neural nets, and 38 percent better scaling across nodes, than NVIDIA "Maxwell" GPUs, which triggered a swift response from the GPU maker, which made significant investments in deep-learning technologies over the past three years.
NVIDIA argued that Intel is using the classic technique of running outdated benchmarks to test its neural net training speeds. The company says that if Intel used the latest version of the same benchmark (Caffe AlexNet), the "Maxwell" GPU will be found to be 30 percent faster than the Xeon Phi at training neural nets. NVIDIA also notes that "Maxwell" is only its previous-generation part, and a "Pascal" based HPC processor would easily be 90 percent faster than the Xeon Phi. More importantly, NVIDIA notes that Intel compared 32 of its new Xeon Phi servers against four-year-old Nvidia Kepler K20 servers being used in ORNL's Titan supercomputer. The latest "Pascal" GPUs leverate NVLink to scale up to 128 GPUs, providing the fastest deep-learning solutions money can buy.

View at TechPowerUp Main Site
NVIDIA argued that Intel is using the classic technique of running outdated benchmarks to test its neural net training speeds. The company says that if Intel used the latest version of the same benchmark (Caffe AlexNet), the "Maxwell" GPU will be found to be 30 percent faster than the Xeon Phi at training neural nets. NVIDIA also notes that "Maxwell" is only its previous-generation part, and a "Pascal" based HPC processor would easily be 90 percent faster than the Xeon Phi. More importantly, NVIDIA notes that Intel compared 32 of its new Xeon Phi servers against four-year-old Nvidia Kepler K20 servers being used in ORNL's Titan supercomputer. The latest "Pascal" GPUs leverate NVLink to scale up to 128 GPUs, providing the fastest deep-learning solutions money can buy.
View at TechPowerUp Main Site



")
