Raevenlord
News Editor
- Joined
- Aug 12, 2016
- Messages
- 3,755 (1.20/day)
- Location
- Portugal
| System Name | The Ryzening |
|---|---|
| Processor | AMD Ryzen 9 5900X |
| Motherboard | MSI X570 MAG TOMAHAWK |
| Cooling | Lian Li Galahad 360mm AIO |
| Memory | 32 GB G.Skill Trident Z F4-3733 (4x 8 GB) |
| Video Card(s) | Gigabyte RTX 3070 Ti |
| Storage | Boot: Transcend MTE220S 2TB, Kintson A2000 1TB, Seagate Firewolf Pro 14 TB |
| Display(s) | Acer Nitro VG270UP (1440p 144 Hz IPS) |
| Case | Lian Li O11DX Dynamic White |
| Audio Device(s) | iFi Audio Zen DAC |
| Power Supply | Seasonic Focus+ 750 W |
| Mouse | Cooler Master Masterkeys Lite L |
| Keyboard | Cooler Master Masterkeys Lite L |
| Software | Windows 10 x64 |
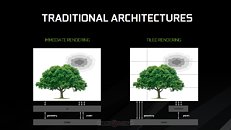
Looking back on NVIDIA's GDC presentation, perhaps one of the most interesting aspects approached was the implementation of tile-based rendering on NVIDIA's post-Maxwell architectures. This has been an adaptation of typically mobile approaches to graphics rendering which keeps their specific needs for power efficiency in mind - and if you'll "member", "Maxwell" was NVIDIA's first graphics architecture publicly touted for its "mobile first" design.
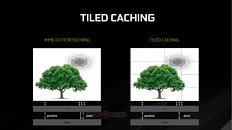
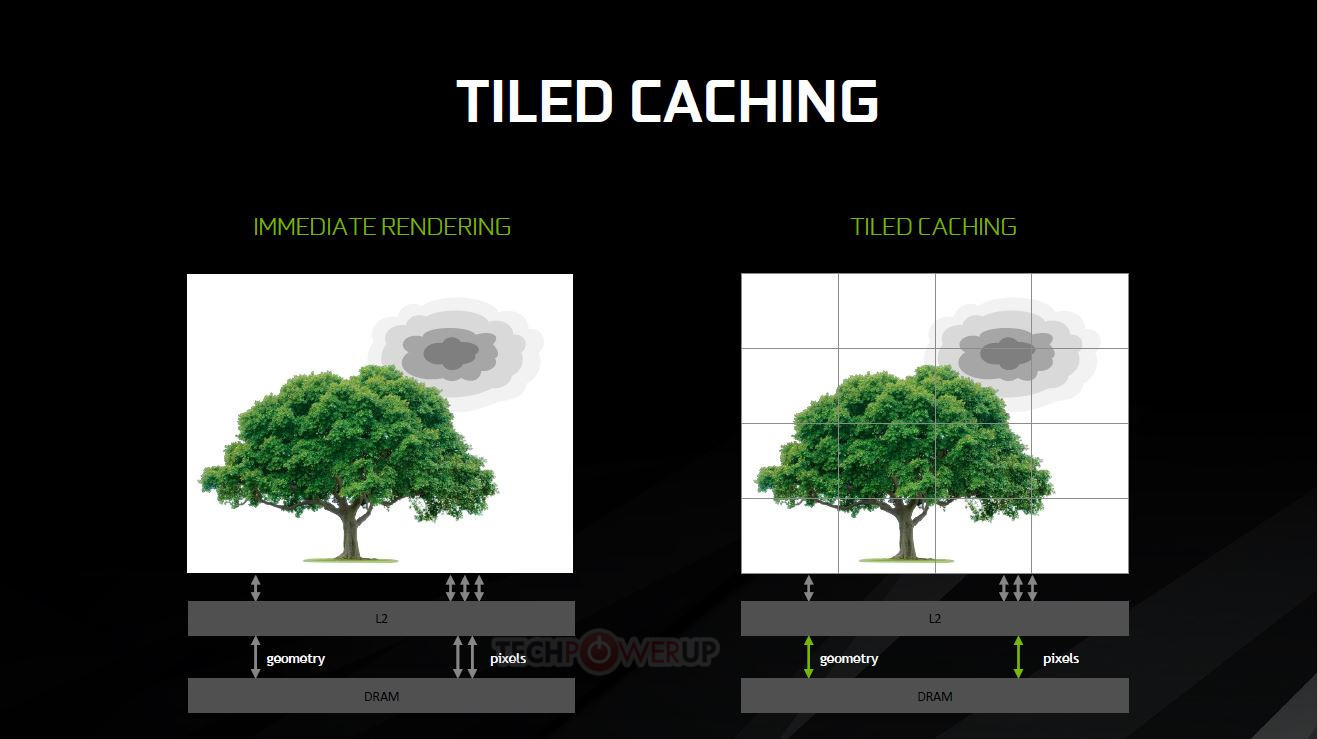
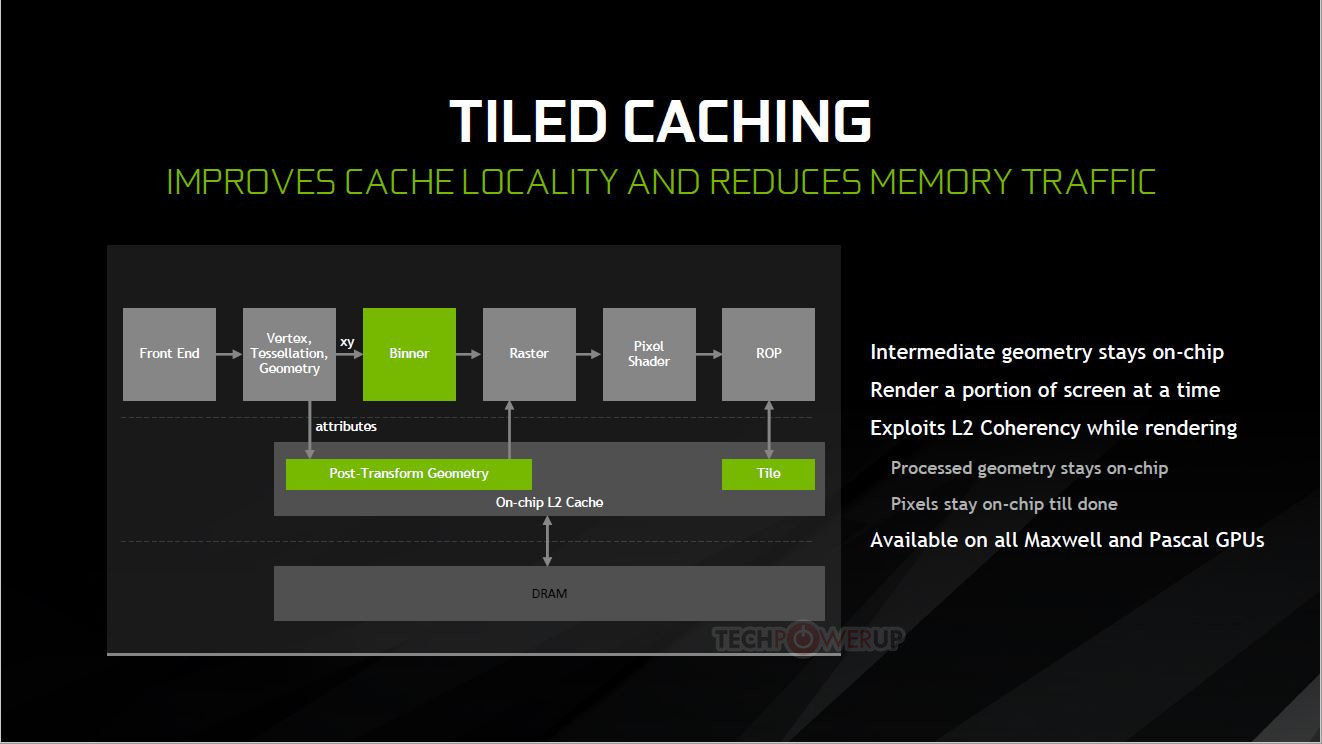
This approach essentially divides the screen into tiles, and then rasterizes the entire frame in a per-tile basis. 16×16 and 32×32 pixels are the usual tile sizes, but both Maxwell and Pascal can dynamically assess the required tile size for each frame, changing it on-the-fly as needed and according to the complexity of the scene. This looks to ensure that the processed data has a much smaller footprint than that of the full image rendering - small enough that it makes it possible for NVIDIA to keep the data in a much smaller amount of memory (essentially, the L2 memory), dynamically filling and flushing the available cache as possible until the full frame has been rendered. This means that the GPU doesn't have to access larger, slower memory pools as much, which primarily reduces the load on the VRAM subsystem (increasing available VRAM for other tasks), whilst simultaneously accelerating rendering speed. At the same time, a tile-based approach also lends itself pretty well to the nature of GPUs - these are easily parallelized operations, with the GPU being able to tackle many independent tiles simultaneously, depending on the available resources.


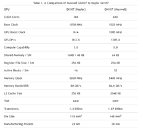
Thanks to NVIDIA's public acknowledgement on the usage of tile-based rendering strating with its Maxwell architectures, some design decisions on the Maxwell architecture now make much more sense. Below, is a screenshot taken from NVIDIA's "5 Things You Should Know About the New Maxwell GPU Architecture". Take a look at the L2 cache size. From Kepler to Maxwell, the cache size increased 8x, from 256 KB on Kepler to the 2048 KB on Maxwell. Now, we can attribute this gigantic leap in cache size to the need for a higher-size L2 cache so as to fit the required tile-based resources for the rasterizing process, which allowed NVIDIA the leap in memory performance and power efficiency they achieved with the Maxwell architecture compared to its Kepler predecessor. Incidentally, NVIDIA's GP102 chip (which powers the GTX Titan X and the upcoming, recently announced GTX 1080 Ti, doubles that amount of L2 cache again, to a staggering 4096 KB. Whether or not Volta will continue with the scaling of L2 cache remains to be seen, but I've seen worse bets.

An interesting tangent: the Xbox 360 and Xbox One ESRAM chips (running on AMD-architectured GPUs, no less) can make for a substitute for the tile-based rasterization process that post-Maxwell NVIDIA GPUs employ.
Tile-based rendering seems to have been a key part on NVIDIA's secret-sauce towards achieving the impressive performance-per-watt ratings of their last two architectures, and it's expected that their approach to this rendering mode will only improve with time. Some differences can be seen in the tile-based rendering between Maxwell and Pascal already, with the former dividing the scene into triangles, and the later breaking a scene up into squares or vertical rectangles as needed, so this means that NVIDIA has in fact put in some measure of work into the rendering system between both these architectures.
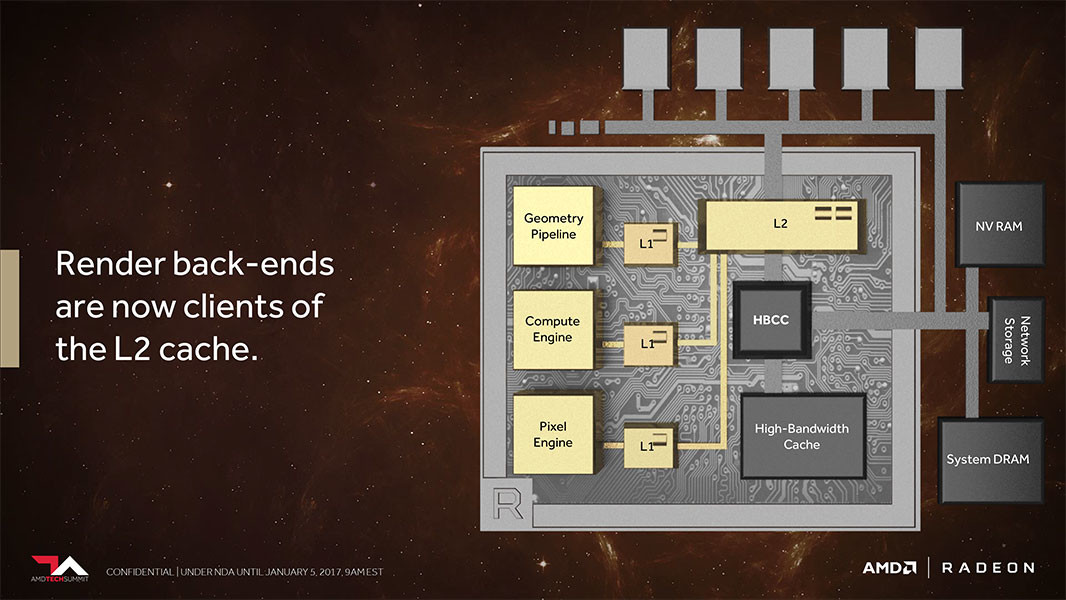
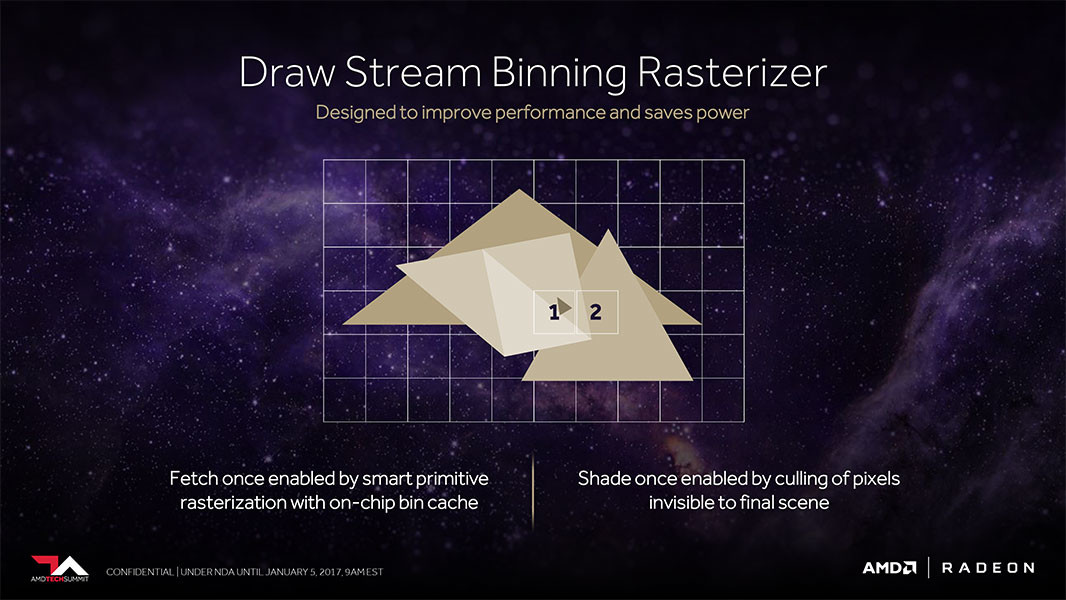
Perhaps we have already seen some seeds of this tile-based rendering on AMD's Vega architecture sneak peek, particularly in regards to its next-generation Pixel Engine: the render back-ends now being clients of the L2 cache substitute their previous architectures' non-coherent memory access, in which the pixel engine wrote to the memory controller. This could be AMD's way of tackling the same problem, with AMD's improvements to the pixel-engine with a new-generation draw-stream binning rasterizer supposedly helping to conserve clock cycles, whilst simultaneously improving on-die cache locality and memory footprint.


David Kanter, of Real World Tech, has a pretty interesting YouTube video where he goes in some depth on NVIDIA's tile-based approach, which you can check if you're interested.
View at TechPowerUp Main Site
This approach essentially divides the screen into tiles, and then rasterizes the entire frame in a per-tile basis. 16×16 and 32×32 pixels are the usual tile sizes, but both Maxwell and Pascal can dynamically assess the required tile size for each frame, changing it on-the-fly as needed and according to the complexity of the scene. This looks to ensure that the processed data has a much smaller footprint than that of the full image rendering - small enough that it makes it possible for NVIDIA to keep the data in a much smaller amount of memory (essentially, the L2 memory), dynamically filling and flushing the available cache as possible until the full frame has been rendered. This means that the GPU doesn't have to access larger, slower memory pools as much, which primarily reduces the load on the VRAM subsystem (increasing available VRAM for other tasks), whilst simultaneously accelerating rendering speed. At the same time, a tile-based approach also lends itself pretty well to the nature of GPUs - these are easily parallelized operations, with the GPU being able to tackle many independent tiles simultaneously, depending on the available resources.
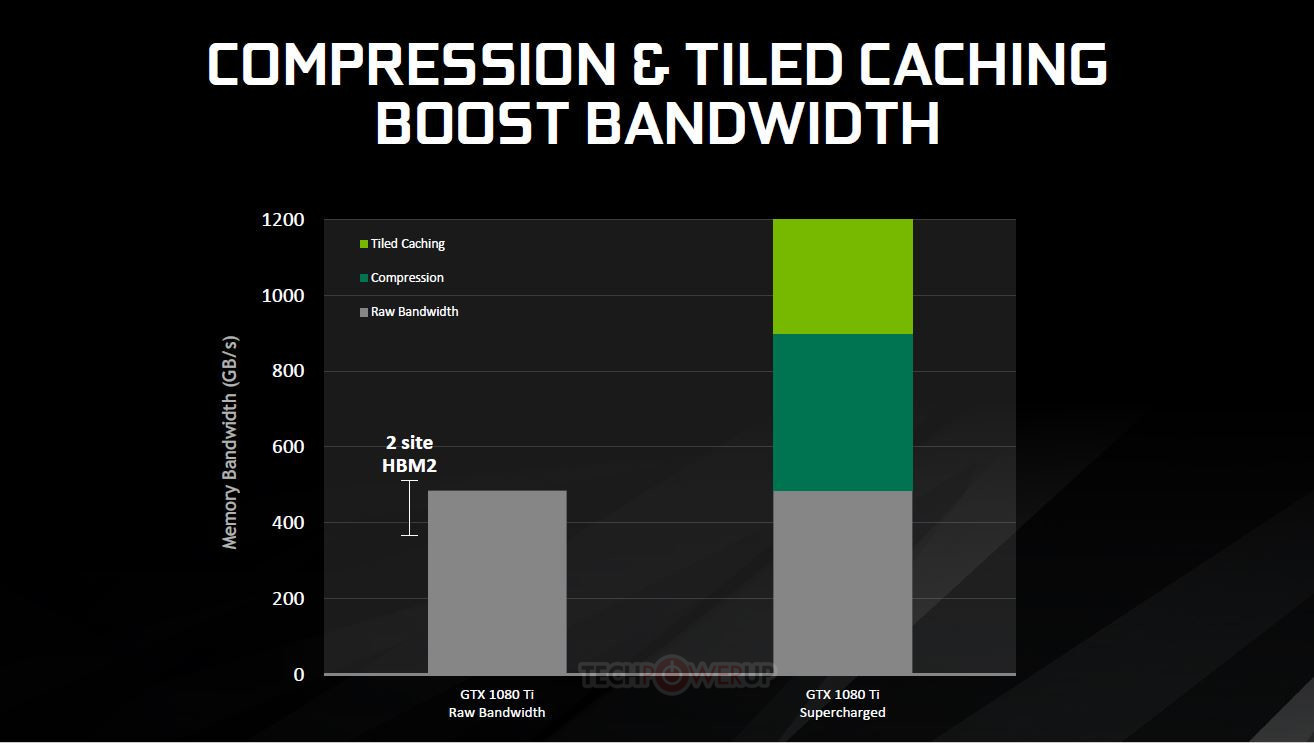
Thanks to NVIDIA's public acknowledgement on the usage of tile-based rendering strating with its Maxwell architectures, some design decisions on the Maxwell architecture now make much more sense. Below, is a screenshot taken from NVIDIA's "5 Things You Should Know About the New Maxwell GPU Architecture". Take a look at the L2 cache size. From Kepler to Maxwell, the cache size increased 8x, from 256 KB on Kepler to the 2048 KB on Maxwell. Now, we can attribute this gigantic leap in cache size to the need for a higher-size L2 cache so as to fit the required tile-based resources for the rasterizing process, which allowed NVIDIA the leap in memory performance and power efficiency they achieved with the Maxwell architecture compared to its Kepler predecessor. Incidentally, NVIDIA's GP102 chip (which powers the GTX Titan X and the upcoming, recently announced GTX 1080 Ti, doubles that amount of L2 cache again, to a staggering 4096 KB. Whether or not Volta will continue with the scaling of L2 cache remains to be seen, but I've seen worse bets.


An interesting tangent: the Xbox 360 and Xbox One ESRAM chips (running on AMD-architectured GPUs, no less) can make for a substitute for the tile-based rasterization process that post-Maxwell NVIDIA GPUs employ.
Tile-based rendering seems to have been a key part on NVIDIA's secret-sauce towards achieving the impressive performance-per-watt ratings of their last two architectures, and it's expected that their approach to this rendering mode will only improve with time. Some differences can be seen in the tile-based rendering between Maxwell and Pascal already, with the former dividing the scene into triangles, and the later breaking a scene up into squares or vertical rectangles as needed, so this means that NVIDIA has in fact put in some measure of work into the rendering system between both these architectures.
Perhaps we have already seen some seeds of this tile-based rendering on AMD's Vega architecture sneak peek, particularly in regards to its next-generation Pixel Engine: the render back-ends now being clients of the L2 cache substitute their previous architectures' non-coherent memory access, in which the pixel engine wrote to the memory controller. This could be AMD's way of tackling the same problem, with AMD's improvements to the pixel-engine with a new-generation draw-stream binning rasterizer supposedly helping to conserve clock cycles, whilst simultaneously improving on-die cache locality and memory footprint.
David Kanter, of Real World Tech, has a pretty interesting YouTube video where he goes in some depth on NVIDIA's tile-based approach, which you can check if you're interested.
View at TechPowerUp Main Site
Last edited:



