Multi-Chip-Module accelerators are nothing new, really. Though there are earlier implementations, when it comes to recognizable hardware most of us has already heard of, these solutions harken back to Intel's Kentsfield and Yorkfield quad-core processors (built on the 65 nm process for the LGA 775 package.) However, a singular issue with this kind of approach is having a powerful, performant-enough interconnect that allows the different cores in each module to really "talk" to each other and work perfectly in tandem. More recently, AMD has demonstrated the advantages of a true MCM (Multi-Chip-Module) approach with its Ryzen CPUs. These result from the development of a modular CPU architecture with a powerful interconnect (Infinity Fabric), which has allowed AMD to keep die size to a minimum (as it relates to a true 8-core design, at least), while enabling the company to profitably scale up to 16-cores (2 MCMs) with
Threadripper, and 4 MCMs with
Epyc (32 cores.)
AMD has already given hints in that its still long-coming
Navi architecture (I mean, we're still waiting for Vega) will bring a true MCM design to GPUs. Vega already supports AMD's Infinity Fabric interconnect as well, paving the way for future APU designs from the company, but also MCM GPU ones, leveraging the same technology. And NVIDIA itself seems to be making strides towards an MCM-enabled future, looking to abandon the monolithic die design approach it has been taking for a long time now.



NVIDIA believes a modular approach is the best, currently technically and technologically feasible solution to a stagnating Moore's Law. CPU and GPU performance and complexity has been leaning heavily on increasing transistor counts and density, whose development and more importantly, production deployment, is slowing down (the curve that seemed to be exponential is actually sigmoidal, eh!). In fact, it is currently estimated that the biggest die-size achievable with today's technology is ~800 mm². The point is driven home when we consider that the company's Tesla V100 comes in at a staggering
815 mm², thus already straining the technical die-size limit. This fact, coupled with the industry's ever-increasing need of ever-increasing performance, leads us to believe that the GV100 GPU will be one of NVIDIA's last monolithic design GPUs (there is still a chance that 7 nm manufacturing will give the company a little more time in developing a true MCM solution, but I would say that odds are NVIDIA's next product will already manifest in such a design.


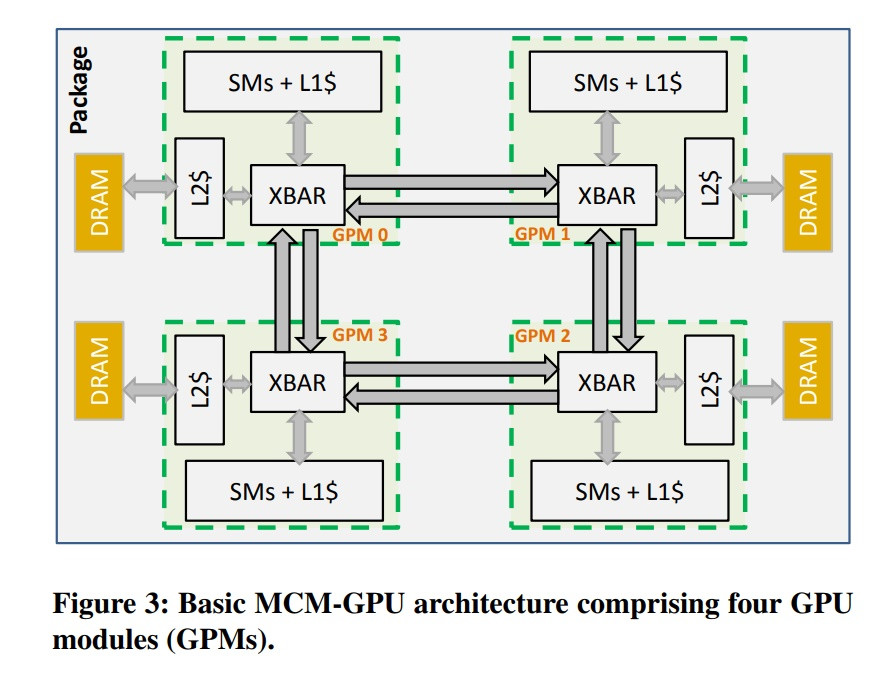
In a paper published by the company, NVIDIA itself says that the way ahead is towards integration of multiple GPU processing modules in a single package, thus allowing the GPU world to achieve what Ryzen and its Threadripper and EPYC older brothers are already achieving: scaling performance with
small dies, and therefore, higher yields... Specifically NVIDIA says that they "(...) propose partitioning GPUs into easily manufacturable basic GPU Modules (GPMs), and integrating them on package using high bandwidth and power efficient signaling technologies." In its white paper, NVIDIA says that "the optimized MCM-GPU design is 45.5% faster than the largest implementable monolithic GPU, and performs within 10% of a hypothetical (and unbuildable) monolithic GPU (...)", and that their "optimized MCM-GPU is 26.8% faster than an equally equipped Multi-GPU system with the same total number of SMs and DRAM bandwidth."

These developments go on to show engineering's ingenuity and drive to improve, and looks extremely promising for companies, since abandoning the monolithic design philosophy and scaling with a variable number of smaller dies should allow for greater yields and improved performance scaling, thus both keeping the high-performance market's needs sated, and the tech companies' bottom line a little better off than they (mostly) already are. Go on ahead and follow the source NVIDIA link for the white paper, it's a very interesting read.
Sources: NVIDIA MCM Paper, Radar.O'Reilly.com

")