Raevenlord
News Editor
- Joined
- Aug 12, 2016
- Messages
- 3,755 (1.20/day)
- Location
- Portugal
| System Name | The Ryzening |
|---|---|
| Processor | AMD Ryzen 9 5900X |
| Motherboard | MSI X570 MAG TOMAHAWK |
| Cooling | Lian Li Galahad 360mm AIO |
| Memory | 32 GB G.Skill Trident Z F4-3733 (4x 8 GB) |
| Video Card(s) | Gigabyte RTX 3070 Ti |
| Storage | Boot: Transcend MTE220S 2TB, Kintson A2000 1TB, Seagate Firewolf Pro 14 TB |
| Display(s) | Acer Nitro VG270UP (1440p 144 Hz IPS) |
| Case | Lian Li O11DX Dynamic White |
| Audio Device(s) | iFi Audio Zen DAC |
| Power Supply | Seasonic Focus+ 750 W |
| Mouse | Cooler Master Masterkeys Lite L |
| Keyboard | Cooler Master Masterkeys Lite L |
| Software | Windows 10 x64 |
An AMD patent may have just shown the company's hand when it comes to its interpretation of raytracing implementation on graphics cards. The patent, titled "Texture Processor Based Ray Tracing Acceleration Method and System", describes a hybrid, software-hardware approach to raytracing. AMD says this approach improves upon solely hardware-based solutions:

Essentially, AMD will be introducing what it calls a "fixed function ray intersection engine", which is specialized hardware that only handles BVH intersection (processing BVH calculations in a stream processor solely via a software solution isn't a pretty option, since execution divergence means that a number of error corrections are required, which makes the process time and resource-intensive). This fixed function hardware (which is nothing like NVIDIA's RT cores and is much simpler) is added in parallel to the texture filter pipeline in GPU's texture processor.

The idea is that the fixed-function raytracing hardware can now use the texture system's already existing memory buffers instead of having to store raytracing-specific data locally, which adds to die area and chip complexity. Additionally, since there is no software to allocate resources and schedule work for the fixed-function hardware, pure hardware solutions require an additional hardware scheduler only for RT-specific workloads, which AMD claims its implementation bypasses - the shader processor sends raytracing data down the texture processing path for the fixed-function hardware to process, saving even more die space that would be used in a "classical" hardware solution.
It's pretty well-known that both Sony and Microsoft's next-gen consoles will support raytracing, and will be AMD Navi-based in nature. It's likely these custom chips have some more of the special dust from AMD's RDNA architecture (which is only sprinkled on consumer, PC-level Navi), and these special components certainly pertain (even if not completely) to both consoles' raytracing capabilities. While the patent has been submitted a year and a half ago, this is the time to reap fruits from such a hybrid design; Some highlights on AMD's approach that have been taken from the paper can be seen below, but if you fancy a read of the whole patent, follow the source link.

View at TechPowerUp Main Site
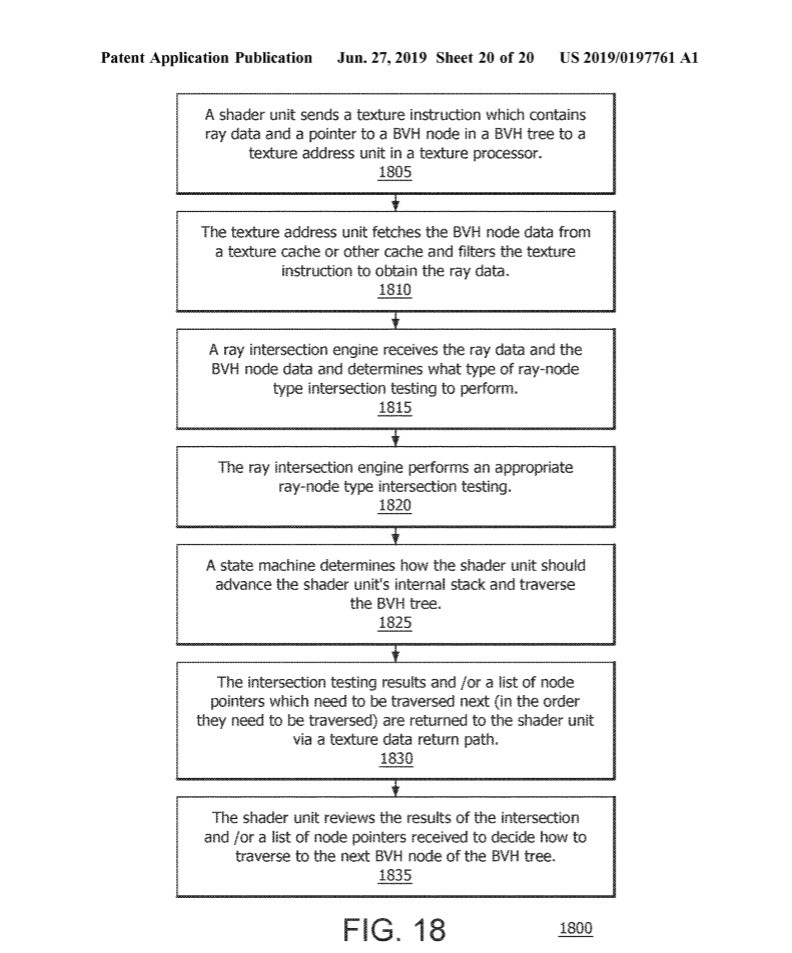
"The hybrid approach (doing fixed function acceleration for a single node of the bounded volume hierarchy (BVH) tree and using a shader unit to schedule the processing) addresses the issues with solely hardware based and/or solely software based solutions. Flexibility is preserved since the shader unit can still control the overall calculation and can bypass the fixed function hardware where needed and still get the performance advantage of the fixed function hardware. In addition, by utilizing the texture processor infrastructure, large buffers for ray storage and BVH caching are eliminated that are typically required in a hardware raytracing solution as the existing vector general purpose register (VGPRs) and texture cache can be used in its place, which substantially saves area and complexity of the hardware solution."

Essentially, AMD will be introducing what it calls a "fixed function ray intersection engine", which is specialized hardware that only handles BVH intersection (processing BVH calculations in a stream processor solely via a software solution isn't a pretty option, since execution divergence means that a number of error corrections are required, which makes the process time and resource-intensive). This fixed function hardware (which is nothing like NVIDIA's RT cores and is much simpler) is added in parallel to the texture filter pipeline in GPU's texture processor.
The idea is that the fixed-function raytracing hardware can now use the texture system's already existing memory buffers instead of having to store raytracing-specific data locally, which adds to die area and chip complexity. Additionally, since there is no software to allocate resources and schedule work for the fixed-function hardware, pure hardware solutions require an additional hardware scheduler only for RT-specific workloads, which AMD claims its implementation bypasses - the shader processor sends raytracing data down the texture processing path for the fixed-function hardware to process, saving even more die space that would be used in a "classical" hardware solution.
It's pretty well-known that both Sony and Microsoft's next-gen consoles will support raytracing, and will be AMD Navi-based in nature. It's likely these custom chips have some more of the special dust from AMD's RDNA architecture (which is only sprinkled on consumer, PC-level Navi), and these special components certainly pertain (even if not completely) to both consoles' raytracing capabilities. While the patent has been submitted a year and a half ago, this is the time to reap fruits from such a hybrid design; Some highlights on AMD's approach that have been taken from the paper can be seen below, but if you fancy a read of the whole patent, follow the source link.
The system includes a shader, texture processor (TP) and cache, which are interconnected. The TP includes a texture address unit (TA), a texture cache processor (TCP), a filter pipeline unit and a ray intersection engine. The shader sends a texture instruction which contains ray data and a pointer to a bounded volume hierarchy (BVH) node to the TA. The TCP uses an address provided by the TA to fetch BVH node data from the cache. The ray intersection engine performs ray-BVH node type intersection testing using the ray data and the BVH node data. The intersection testing results and indications for BVH traversal are returned to the shader via a texture data return path. The shader reviews the intersection results and the indications to decide how to traverse to the next BVH node.
(...)
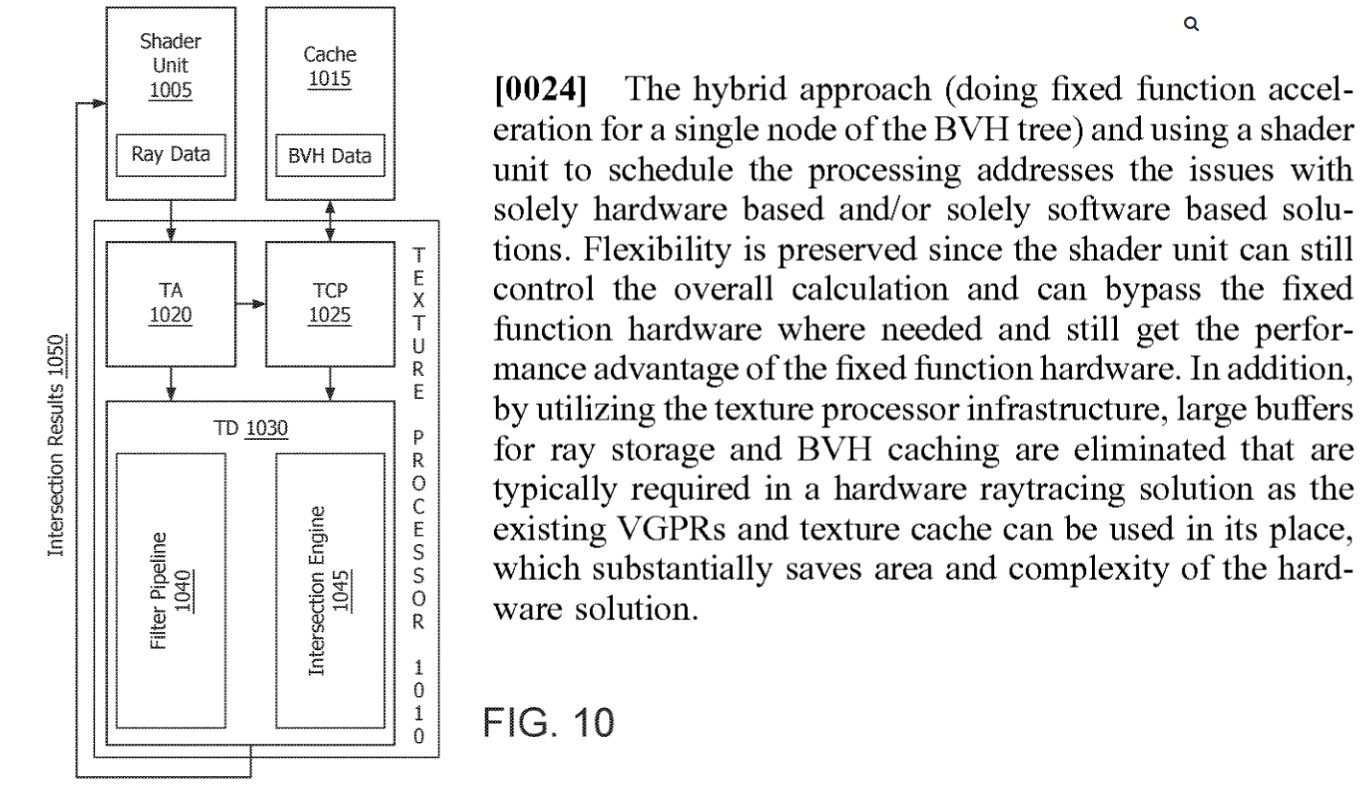
A texture processor based ray tracing acceleration method and system are described herein. A fixed function BVH intersection testing and traversal (a common and expensive operation in ray tracers) logic is implemented on texture processors. This enables the performance and power efficiency of the ray tracing to be substantially improved without expanding high area and effort costs. High bandwidth paths within the texture processor and shader units that are used for texture processing are reused for BVH intersection testing and traversal. In general, a texture processor receives an instruction from the shader unit that includes ray data and BVH node pointer information. The texture processor fetches the BVH node data from memory using, for example, 16 double word (DW) block loads. The texture processor performs four ray-box intersections and children sorting for box nodes and 1 ray-triangle intersection for triangle nodes. The intersection results are returned to the shader unit.
In particular, a fixed function ray intersection engine is added in parallel to a texture filter pipeline in a texture processor. This enables the shader unit to issue a texture instruction which contains the ray data (ray origin and ray direction) and a pointer to the BVH node in the BVH tree. The texture processor can fetch the BVH node data from memory and supply both the data from the BVH node and the ray data to the fixed function ray intersection engine. The ray intersection engine looks at the data for the BVH node and determines whether it needs to do ray-box intersection or ray-triangle intersection testing. The ray intersection engine configures its ALUs or compute units accordingly and passes the ray data and BVH node data through the configured internal ALUs or compute units to calculate the intersection results. Based on the results of the intersection testing, a state machine determines how the shader unit should advance its internal stack (traversal stack) and traverse the BVH tree. The state machine can be fixed function or programmable. The intersection testing results and/or a list of node pointers which need to be traversed next (in the order they need to be traversed) are returned to the shader unit using the texture data return path. The shader unit reviews the results of the intersection and the indications received to decide how to traverse to the next node in the BVH tree.
View at TechPowerUp Main Site






")