- Joined
- Aug 19, 2017
- Messages
- 2,808 (1.02/day)
NVIDIA will soon launch its next-generation lineup of graphics cards based on a new and improved "Ampere" architecture. With the first Tesla server cards that are a part of the Ampere lineup going inside Indiana University Big Red 200 supercomputer, we now have some potential specifications and information about its compute performance. Thanks to the Twitter user dylan552p(@dylan522p), who did some math about the potential compute performance of the Ampere GPUs based on NextPlatform's report, we discovered that Ampere is potentially going to feature up to 18 TeraFLOPs of FP64 compute performance.
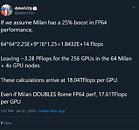
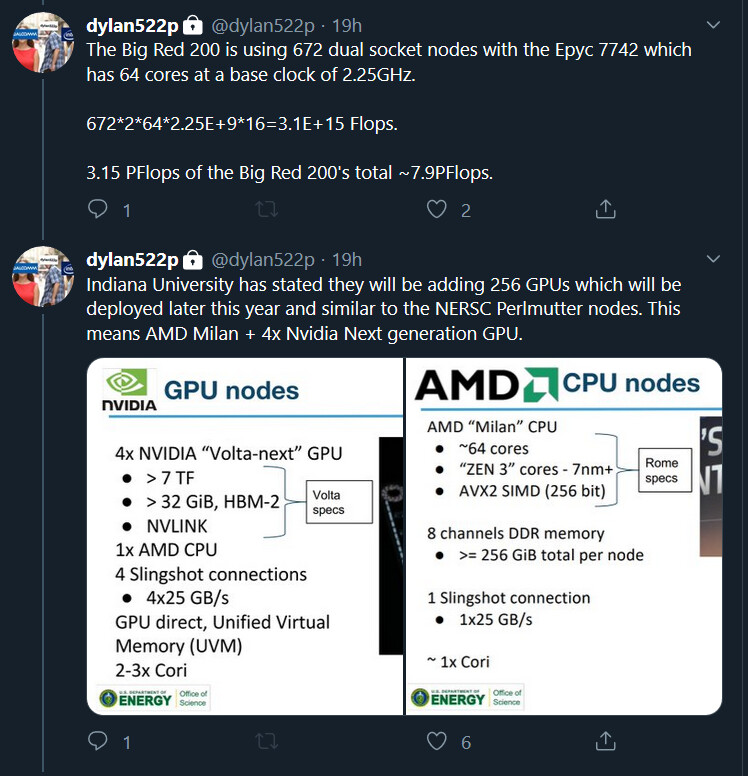
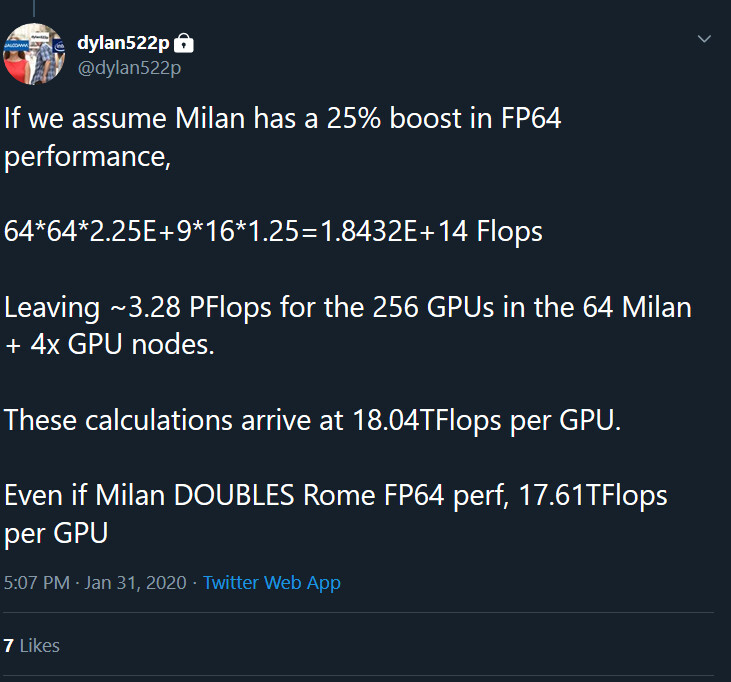
With Big Red 200 supercomputer being based on Cray's Shasta supercomputer building block, it is being deployed in two phases. The first phase is the deployment of 672 dual-socket nodes powered by AMD's EPYC 7742 "Rome" processors. These CPUs provide 3.15 PetaFLOPs of combined FP64 performance. With a total of 8 PetaFLOPs planned to be achieved by the Big Red 200, that leaves just a bit under 5 PetaFLOPs to be had using GPU+CPU enabled system. Considering the configuration of a node that contains one next-generation AMD "Milan" 64 core CPU, and four of NVIDIA's "Ampere" GPUs alongside it. If we take for a fact that Milan boosts FP64 performance by 25% compared to Rome, then the math shows that the 256 GPUs that will be delivered in the second phase of Big Red 200 deployment will feature up to 18 TeraFLOPs of FP64 compute performance. Even if "Milan" doubles the FP64 compute power of "Rome", there will be around 17.6 TeraFLOPs of FP64 performance for the GPU.

View at TechPowerUp Main Site
With Big Red 200 supercomputer being based on Cray's Shasta supercomputer building block, it is being deployed in two phases. The first phase is the deployment of 672 dual-socket nodes powered by AMD's EPYC 7742 "Rome" processors. These CPUs provide 3.15 PetaFLOPs of combined FP64 performance. With a total of 8 PetaFLOPs planned to be achieved by the Big Red 200, that leaves just a bit under 5 PetaFLOPs to be had using GPU+CPU enabled system. Considering the configuration of a node that contains one next-generation AMD "Milan" 64 core CPU, and four of NVIDIA's "Ampere" GPUs alongside it. If we take for a fact that Milan boosts FP64 performance by 25% compared to Rome, then the math shows that the 256 GPUs that will be delivered in the second phase of Big Red 200 deployment will feature up to 18 TeraFLOPs of FP64 compute performance. Even if "Milan" doubles the FP64 compute power of "Rome", there will be around 17.6 TeraFLOPs of FP64 performance for the GPU.

View at TechPowerUp Main Site





