- Joined
- Oct 9, 2007
- Messages
- 47,229 (7.55/day)
- Location
- Hyderabad, India
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | ASUS ROG Strix B450-E Gaming |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 8GB G.Skill Sniper X |
| Video Card(s) | Palit GeForce RTX 2080 SUPER GameRock |
| Storage | Western Digital Black NVMe 512GB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
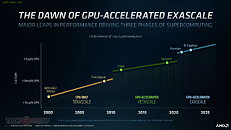
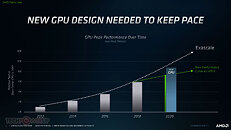
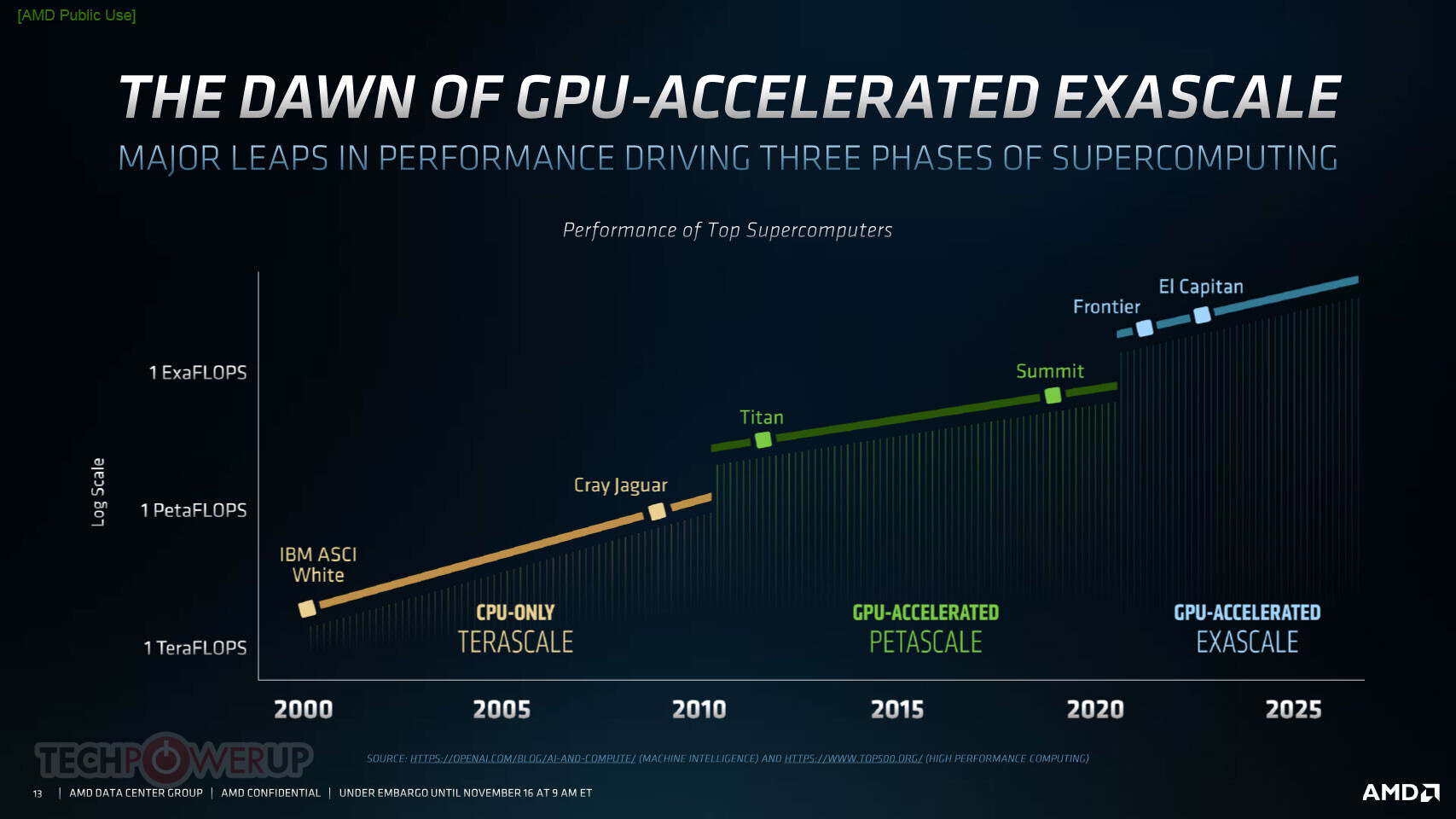
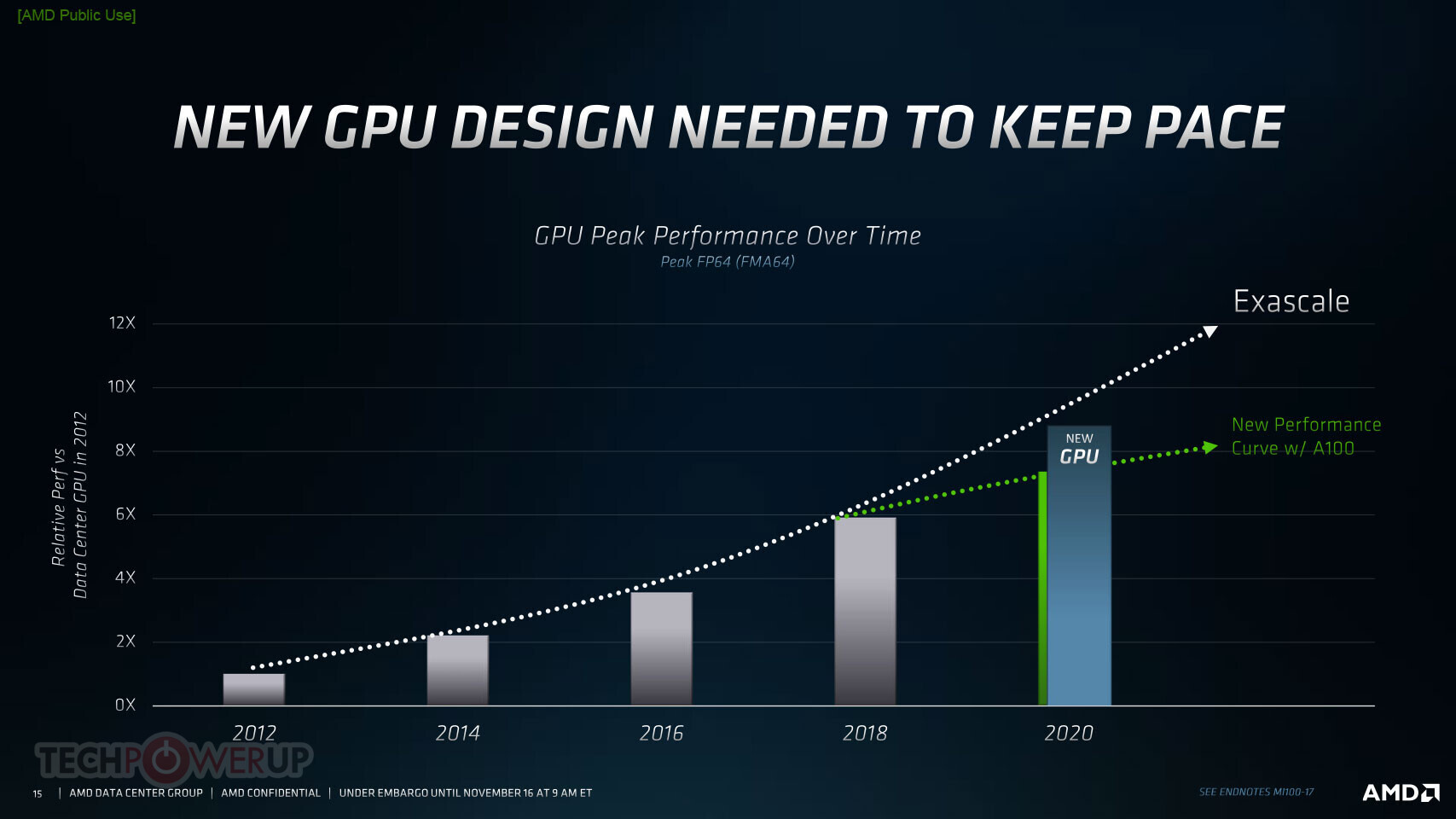
AMD today announced the new AMD Instinct MI100 accelerator - the world's fastest HPC GPU and the first x86 server GPU to surpass the 10 teraflops (FP64) performance barrier. Supported by new accelerated compute platforms from Dell, Gigabyte, HPE, and Supermicro, the MI100, combined with AMD EPYC CPUs and the ROCm 4.0 open software platform, is designed to propel new discoveries ahead of the exascale era.
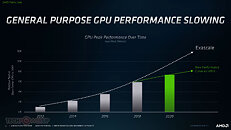
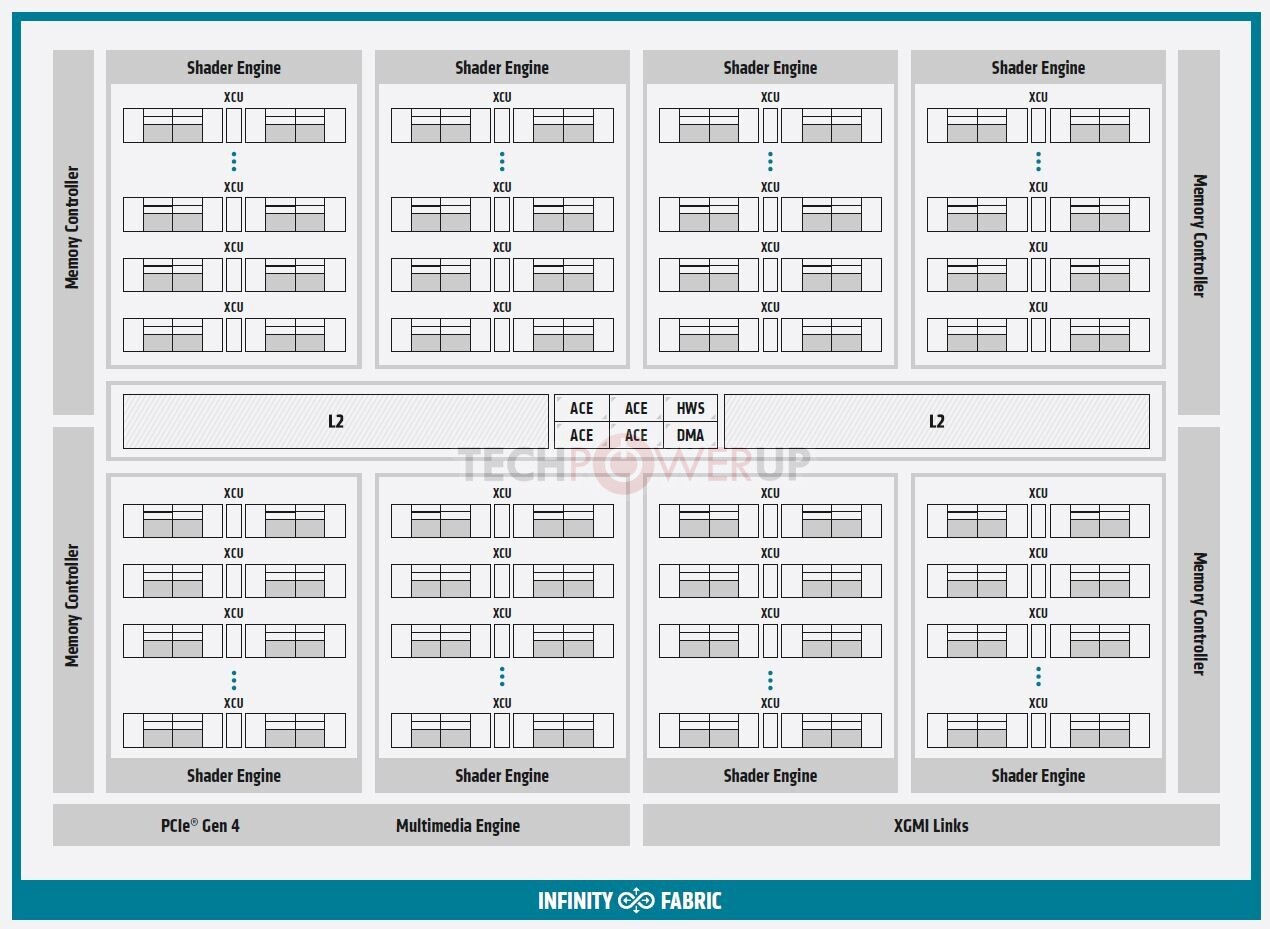
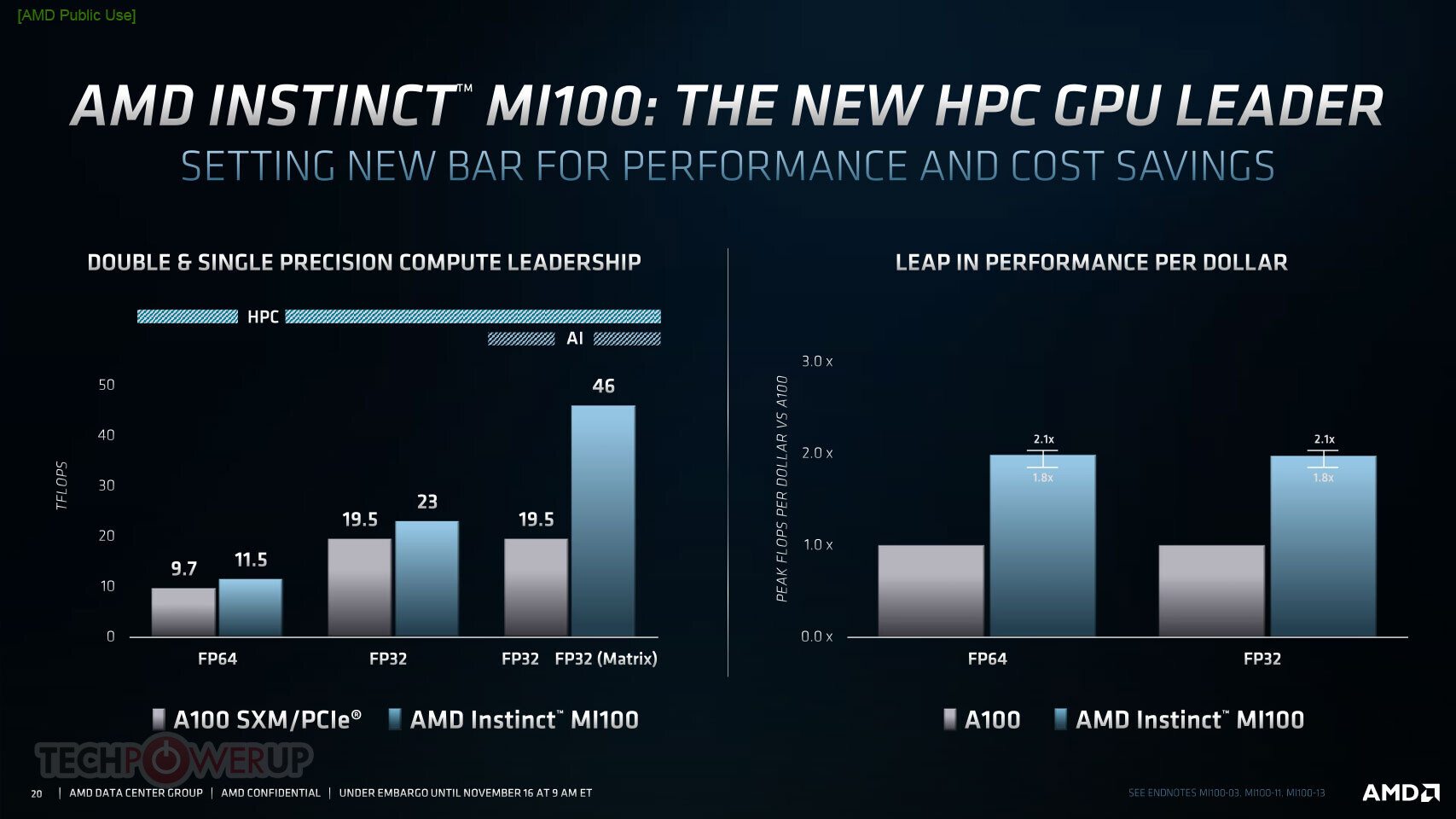
Built on the new AMD CDNA architecture, the AMD Instinct MI100 GPU enables a new class of accelerated systems for HPC and AI when paired with 2nd Gen AMD EPYC processors. The MI100 offers up to 11.5 TFLOPS of peak FP64 performance for HPC and up to 46.1 TFLOPS peak FP32 Matrix performance for AI and machine learning workloads. With new AMD Matrix Core technology, the MI100 also delivers a nearly 7x boost in FP16 theoretical peak floating point performance for AI training workloads compared to AMD's prior generation accelerators.





"Today AMD takes a major step forward in the journey toward exascale computing as we unveil the AMD Instinct MI100 - the world's fastest HPC GPU," said Brad McCredie, corporate vice president, Data Center GPU and Accelerated Processing, AMD. "Squarely targeted toward the workloads that matter in scientific computing, our latest accelerator, when combined with the AMD ROCm open software platform, is designed to provide scientists and researchers a superior foundation for their work in HPC."
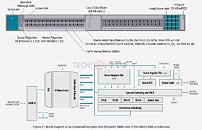
Open Software Platform for the Exascale Era
The AMD ROCm developer software provides the foundation for exascale computing. As an open source toolset consisting of compilers, programming APIs and libraries, ROCm is used by exascale software developers to create high performance applications. ROCm 4.0 has been optimized to deliver performance at scale for MI100-based systems. ROCm 4.0 has upgraded the compiler to be open source and unified to support both OpenMP 5.0 and HIP. PyTorch and Tensorflow frameworks, which have been optimized with ROCm 4.0, can now achieve higher performance with MI100. ROCm 4.0 is the latest offering for HPC, ML and AI application developers which allows them to create performance portable software.
"We've received early access to the MI100 accelerator, and the preliminary results are very encouraging. We've typically seen significant performance boosts, up to 2-3x compared to other GPUs," said Bronson Messer, director of science, Oak Ridge Leadership Computing Facility. "What's also important to recognize is the impact software has on performance. The fact that the ROCm open software platform and HIP developer tool are open source and work on a variety of platforms, it is something that we have been absolutely almost obsessed with since we fielded the very first hybrid CPU/GPU system."
Key capabilities and features of the AMD Instinct MI100 accelerator include:
The AMD Instinct MI100 accelerators are expected by end of the year in systems from major OEM and ODM partners in the enterprise markets, including:
Dell
"Dell EMC PowerEdge servers will support the new AMD Instinct MI100, which will enable faster insights from data. This would help our customers achieve more robust and efficient HPC and AI results rapidly," said Ravi Pendekanti, Senior Vice President, PowerEdge Servers, Dell Technologies. "AMD has been a valued partner in our support for advancing innovation in the data center. The high-performance capabilities of AMD Instinct accelerators are a natural fit for our PowerEdge server AI & HPC portfolio."
Gigabyte
"We're pleased to again work with AMD as a strategic partner offering customers server hardware for high performance computing," said Alan Chen, Assistant Vice President in NCBU, GIGABYTE. "AMD Instinct MI100 accelerators represent the next level of high-performance computing in the data center, bringing greater connectivity and data bandwidth for energy research, molecular dynamics, and deep learning training. As a new accelerator in the GIGABYTE portfolio, our customers can look to benefit from improved performance across a range of scientific and industrial HPC workloads."
Hewlett Packard Enterprise (HPE)
"Customers use HPE Apollo systems for purpose-built capabilities and performance to tackle a range of complex, data-intensive workloads across high-performance computing (HPC), deep learning and analytics," said Bill Mannel, vice president and general manager, HPC at HPE. "With the introduction of the new HPE Apollo 6500 Gen10 Plus system, we are further advancing our portfolio to improve workload performance by supporting the new AMD Instinct MI100 accelerator, which enables greater connectivity and data processing, alongside the 2nd Gen AMD EPYC processor and. We look forward to continuing our collaboration with AMD to expand our offerings with its latest CPUs and accelerators."
Supermicro
"We're excited that AMD has produced the world's fastest HPC GPU accelerator. The combination of the compute power gained with the new AMD CDNA architecture, along with the high memory and GPU peer-to-peer bandwidth the MI100 brings, our customers will get access to great solutions that will meet their accelerated compute requirements. Add the open AMD ROCm software stack, and they will get an open, flexible and portable environment to meet their demand for exceptional application support for critical enterprise workloads," said Vik Malyala, senior vice president, field application engineering and business development, Supermicro. "The AMD Instinct MI100 will be a great addition for our multi-GPU servers and our suite of high-performance systems."

The complete slide-deck follows.





























For more information, visit the product page.
View at TechPowerUp Main Site
Built on the new AMD CDNA architecture, the AMD Instinct MI100 GPU enables a new class of accelerated systems for HPC and AI when paired with 2nd Gen AMD EPYC processors. The MI100 offers up to 11.5 TFLOPS of peak FP64 performance for HPC and up to 46.1 TFLOPS peak FP32 Matrix performance for AI and machine learning workloads. With new AMD Matrix Core technology, the MI100 also delivers a nearly 7x boost in FP16 theoretical peak floating point performance for AI training workloads compared to AMD's prior generation accelerators.





"Today AMD takes a major step forward in the journey toward exascale computing as we unveil the AMD Instinct MI100 - the world's fastest HPC GPU," said Brad McCredie, corporate vice president, Data Center GPU and Accelerated Processing, AMD. "Squarely targeted toward the workloads that matter in scientific computing, our latest accelerator, when combined with the AMD ROCm open software platform, is designed to provide scientists and researchers a superior foundation for their work in HPC."

Open Software Platform for the Exascale Era
The AMD ROCm developer software provides the foundation for exascale computing. As an open source toolset consisting of compilers, programming APIs and libraries, ROCm is used by exascale software developers to create high performance applications. ROCm 4.0 has been optimized to deliver performance at scale for MI100-based systems. ROCm 4.0 has upgraded the compiler to be open source and unified to support both OpenMP 5.0 and HIP. PyTorch and Tensorflow frameworks, which have been optimized with ROCm 4.0, can now achieve higher performance with MI100. ROCm 4.0 is the latest offering for HPC, ML and AI application developers which allows them to create performance portable software.
"We've received early access to the MI100 accelerator, and the preliminary results are very encouraging. We've typically seen significant performance boosts, up to 2-3x compared to other GPUs," said Bronson Messer, director of science, Oak Ridge Leadership Computing Facility. "What's also important to recognize is the impact software has on performance. The fact that the ROCm open software platform and HIP developer tool are open source and work on a variety of platforms, it is something that we have been absolutely almost obsessed with since we fielded the very first hybrid CPU/GPU system."
Key capabilities and features of the AMD Instinct MI100 accelerator include:
- All-New AMD CDNA Architecture- Engineered to power AMD GPUs for the exascale era and at the heart of the MI100 accelerator, the AMD CDNA architecture offers exceptional performance and power efficiency
- Leading FP64 and FP32 Performance for HPC Workloads - Delivers industry leading 11.5 TFLOPS peak FP64 performance and 23.1 TFLOPS peak FP32 performance, enabling scientists and researchers across the globe to accelerate discoveries in industries including life sciences, energy, finance, academics, government, defense and more.
- All-New Matrix Core Technology for HPC and AI - Supercharged performance for a full range of single and mixed precision matrix operations, such as FP32, FP16, bFloat16, Int8 and Int4, engineered to boost the convergence of HPC and AI.
- 2nd Gen AMD Infinity Fabric Technology - Instinct MI100 provides ~2x the peer-to-peer (P2P) peak I/O bandwidth over PCIe 4.0 with up to 340 GB/s of aggregate bandwidth per card with three AMD Infinity Fabric Links.4 In a server, MI100 GPUs can be configured with up to two fully-connected quad GPU hives, each providing up to 552 GB/s of P2P I/O bandwidth for fast data sharing.
- Ultra-Fast HBM2 Memory- Features 32 GB High-bandwidth HBM2 memory at a clock rate of 1.2 GHz and delivers an ultra-high 1.23 TB/s of memory bandwidth to support large data sets and help eliminate bottlenecks in moving data in and out of memory.5
- Support for Industry's Latest PCIe Gen 4.0 - Designed with the latest PCIe Gen 4.0 technology support providing up to 64 GB/s peak theoretical transport data bandwidth from CPU to GPU.
The AMD Instinct MI100 accelerators are expected by end of the year in systems from major OEM and ODM partners in the enterprise markets, including:
Dell
"Dell EMC PowerEdge servers will support the new AMD Instinct MI100, which will enable faster insights from data. This would help our customers achieve more robust and efficient HPC and AI results rapidly," said Ravi Pendekanti, Senior Vice President, PowerEdge Servers, Dell Technologies. "AMD has been a valued partner in our support for advancing innovation in the data center. The high-performance capabilities of AMD Instinct accelerators are a natural fit for our PowerEdge server AI & HPC portfolio."
Gigabyte
"We're pleased to again work with AMD as a strategic partner offering customers server hardware for high performance computing," said Alan Chen, Assistant Vice President in NCBU, GIGABYTE. "AMD Instinct MI100 accelerators represent the next level of high-performance computing in the data center, bringing greater connectivity and data bandwidth for energy research, molecular dynamics, and deep learning training. As a new accelerator in the GIGABYTE portfolio, our customers can look to benefit from improved performance across a range of scientific and industrial HPC workloads."
Hewlett Packard Enterprise (HPE)
"Customers use HPE Apollo systems for purpose-built capabilities and performance to tackle a range of complex, data-intensive workloads across high-performance computing (HPC), deep learning and analytics," said Bill Mannel, vice president and general manager, HPC at HPE. "With the introduction of the new HPE Apollo 6500 Gen10 Plus system, we are further advancing our portfolio to improve workload performance by supporting the new AMD Instinct MI100 accelerator, which enables greater connectivity and data processing, alongside the 2nd Gen AMD EPYC processor and. We look forward to continuing our collaboration with AMD to expand our offerings with its latest CPUs and accelerators."
Supermicro
"We're excited that AMD has produced the world's fastest HPC GPU accelerator. The combination of the compute power gained with the new AMD CDNA architecture, along with the high memory and GPU peer-to-peer bandwidth the MI100 brings, our customers will get access to great solutions that will meet their accelerated compute requirements. Add the open AMD ROCm software stack, and they will get an open, flexible and portable environment to meet their demand for exceptional application support for critical enterprise workloads," said Vik Malyala, senior vice president, field application engineering and business development, Supermicro. "The AMD Instinct MI100 will be a great addition for our multi-GPU servers and our suite of high-performance systems."

The complete slide-deck follows.




























For more information, visit the product page.
View at TechPowerUp Main Site


