- Joined
- Aug 19, 2017
- Messages
- 2,579 (0.97/day)
When designing integrated circuits, engineers aim to produce an efficient design that is easier to manufacture. If they manage to keep the circuit size down, the economics of manufacturing that circuit is also going down. NVIDIA has posted on its technical blog a technique where the company uses an artificial intelligence model called PrefixRL. Using deep reinforcement learning, NVIDIA uses the PrefixRL model to outperform traditional EDA (Electronics Design Automation) tools from major vendors such as Cadence, Synopsys, or Siemens/Mentor. EDA vendors usually implement their in-house AI solution to silicon placement and routing (PnR); however, NVIDIA's PrefixRL solution seems to be doing wonders in the company's workflow.
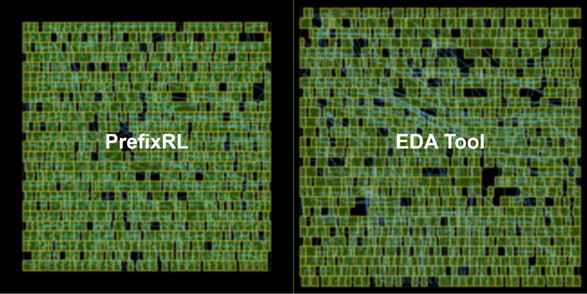
Creating a deep reinforcement learning model that aims to keep the latency the same as the EDA PnR attempt while achieving a smaller die area is the goal of PrefixRL. According to the technical blog, the latest Hopper H100 GPU architecture uses 13,000 instances of arithmetic circuits that the PrefixRL AI model designed. NVIDIA produced a model that outputs a 25% smaller circuit than comparable EDA output. This is all while achieving similar or better latency. Below, you can compare a 64-bit adder design made by PrefixRL and the same design made by an industry-leading EDA tool.


Training such a model is a compute-intensive task. NVIDIA reports that the training to design a 64-bit adder circuit took 256 CPU cores for each GPU and 32,000 GPU hours. The company developed Raptor, an in-house distributed reinforcement learning platform that takes unique advantage of NVIDIA hardware for this kind of industrial reinforcement learning, which you can see below and how it operates. Overall, the system is pretty complex and requires a lot of hardware and input; however, the results pay off with smaller and more efficient GPUs.

View at TechPowerUp Main Site | Source
Creating a deep reinforcement learning model that aims to keep the latency the same as the EDA PnR attempt while achieving a smaller die area is the goal of PrefixRL. According to the technical blog, the latest Hopper H100 GPU architecture uses 13,000 instances of arithmetic circuits that the PrefixRL AI model designed. NVIDIA produced a model that outputs a 25% smaller circuit than comparable EDA output. This is all while achieving similar or better latency. Below, you can compare a 64-bit adder design made by PrefixRL and the same design made by an industry-leading EDA tool.

Training such a model is a compute-intensive task. NVIDIA reports that the training to design a 64-bit adder circuit took 256 CPU cores for each GPU and 32,000 GPU hours. The company developed Raptor, an in-house distributed reinforcement learning platform that takes unique advantage of NVIDIA hardware for this kind of industrial reinforcement learning, which you can see below and how it operates. Overall, the system is pretty complex and requires a lot of hardware and input; however, the results pay off with smaller and more efficient GPUs.

View at TechPowerUp Main Site | Source





 )
)
