- Joined
- Oct 9, 2007
- Messages
- 47,417 (7.51/day)
- Location
- Hyderabad, India
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | ASUS ROG Strix B450-E Gaming |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 8GB G.Skill Sniper X |
| Video Card(s) | Palit GeForce RTX 2080 SUPER GameRock |
| Storage | Western Digital Black NVMe 512GB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
According to an investigative report by "Chips and Cheese," the larger L2 caches in Intel's 13th Gen Core "Raptor Lake-S" doesn't come with a proportionate increase in cache latency, and Intel seems to have contained the latency increase well. "Raptor Lake-S" significantly increases L2 cache sizes over the previous generation. Each of its 8 "Raptor Cove" P-cores has 2 MB of dedicated L2 cache, compared to the 1.25 MB with the "Golden Cove" P-cores powering the current-gen "Alder Lake-S," which amounts to a 60 percent increase in size. The "Gracemont" E-core clusters (group of four E-cores), sees a doubling in the size of the L2 cache that's shared among the four cores in the cluster, from 2 MB in "Alder Lake," to 4 MB. The last-level L3 cache shared among all P-cores and E-core clusters, sees a less remarkable increase in size, from 30 MB to 36 MB.
Larger caches have a direct impact on performance, as more data is available close to the CPU cores, sparing them a lengthy fetch/store operation to the main memory (RAM). However, making caches larger doesn't just cost die-area, transistor-count, and power/heat, but also latency, even though L2 cache is an order of magnitude faster than the L3 cache, which in turn is significantly faster than DRAM. Chips and Cheese tracked and tabulated the L2 cache latencies of past Intel client microarchitectures, and found a generational increase in latencies with increasing L2 cache sizes, leading up to "Alder Lake." This increase has somehow tapered with "Raptor Lake."
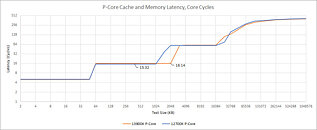

The report says that the 4-way associative 256 KB dedicated L2 cache with "Skylake" (thru "Comet Lake") CPU cores has an L2 cache latency of 12 cycles. "Sunny Cove" and "Cypress Cove" cores see this increase to 512 KB in size, as the latency is increased to 13 cycles. "Willow Cove" and "Golden Cove" (powering "Tiger Lake" and "Alder Lake," respectively), see a further increase. While "Willow Cove" uses a 20-way associative cache, "Golden Cove" uses 10-way. The latency goes up from 13 cycles to 14 cycles. The upcoming "Raptor Cove" P-core comes with 2 MB of 16-way L2 cache, but here, the latency is contained to 15 cycles. It indicates that "Raptor Lake" has undergone some serious rework with its power-management as well as cache design to reach its cache latency target. Bear in mind, that this chip is built on the same 10 nm Enhanced SuperFin (Intel 7) node as "Alder Lake."
View at TechPowerUp Main Site | Source
Larger caches have a direct impact on performance, as more data is available close to the CPU cores, sparing them a lengthy fetch/store operation to the main memory (RAM). However, making caches larger doesn't just cost die-area, transistor-count, and power/heat, but also latency, even though L2 cache is an order of magnitude faster than the L3 cache, which in turn is significantly faster than DRAM. Chips and Cheese tracked and tabulated the L2 cache latencies of past Intel client microarchitectures, and found a generational increase in latencies with increasing L2 cache sizes, leading up to "Alder Lake." This increase has somehow tapered with "Raptor Lake."
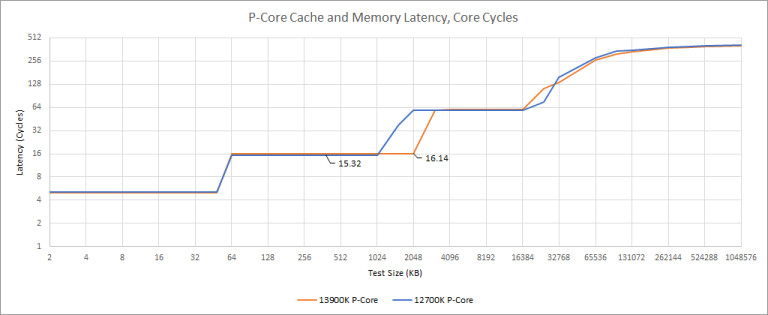

The report says that the 4-way associative 256 KB dedicated L2 cache with "Skylake" (thru "Comet Lake") CPU cores has an L2 cache latency of 12 cycles. "Sunny Cove" and "Cypress Cove" cores see this increase to 512 KB in size, as the latency is increased to 13 cycles. "Willow Cove" and "Golden Cove" (powering "Tiger Lake" and "Alder Lake," respectively), see a further increase. While "Willow Cove" uses a 20-way associative cache, "Golden Cove" uses 10-way. The latency goes up from 13 cycles to 14 cycles. The upcoming "Raptor Cove" P-core comes with 2 MB of 16-way L2 cache, but here, the latency is contained to 15 cycles. It indicates that "Raptor Lake" has undergone some serious rework with its power-management as well as cache design to reach its cache latency target. Bear in mind, that this chip is built on the same 10 nm Enhanced SuperFin (Intel 7) node as "Alder Lake."
View at TechPowerUp Main Site | Source



