TheLostSwede
News Editor
- Joined
- Nov 11, 2004
- Messages
- 18,111 (2.45/day)
- Location
- Sweden
| System Name | Overlord Mk MLI |
|---|---|
| Processor | AMD Ryzen 7 7800X3D |
| Motherboard | Gigabyte X670E Aorus Master |
| Cooling | Noctua NH-D15 SE with offsets |
| Memory | 32GB Team T-Create Expert DDR5 6000 MHz @ CL30-34-34-68 |
| Video Card(s) | Gainward GeForce RTX 4080 Phantom GS |
| Storage | 1TB Solidigm P44 Pro, 2 TB Corsair MP600 Pro, 2TB Kingston KC3000 |
| Display(s) | Acer XV272K LVbmiipruzx 4K@160Hz |
| Case | Fractal Design Torrent Compact |
| Audio Device(s) | Corsair Virtuoso SE |
| Power Supply | be quiet! Pure Power 12 M 850 W |
| Mouse | Logitech G502 Lightspeed |
| Keyboard | Corsair K70 Max |
| Software | Windows 10 Pro |
| Benchmark Scores | https://valid.x86.fr/yfsd9w |
Today, MLCommons published results of its industry AI performance benchmark in which both the 4th Generation Intel Xeon Scalable processor (code-named Sapphire Rapids) and Habana Gaudi 2 dedicated deep learning accelerator logged impressive training results.
"I'm proud of our team's continued progress since we last submitted leadership results on MLPerf in June. Intel's 4th gen Xeon Scalable processor and Gaudi 2 AI accelerator support a wide array of AI functions and deliver leadership performance for customers who require deep learning training and large-scale workloads." Sandra Rivera, Intel executive vice president and general manager of the Datacenter and AI Group


Why It Matters
In many data center use cases, deep learning (DL) is part of a complex pipeline of machine learning (ML) and data analytics running on Xeon-based servers that are also used to run other applications and are adaptable to workload demands changing over time. It is in these use cases that Xeon Scalable delivers the best total cost of ownership (TCO) and year-round utilization.
The 4th Generation Intel Xeon Scalable processor with Intel Advanced Matrix Extensions (AMX), a new built-in AI accelerator, allows customers to extend the general-purpose Xeon server platform to cover even more DL use cases, including DL training and fine tuning. AMX is a dedicated matrix multiplication engine built into every core of 4th Gen Intel Xeon Scalable processors. This dedicated AI engine is optimized to deliver up to 6x higher gen-to-gen DL training model performance using industry standard frameworks.
In cases where the server or a cluster of servers are predominantly used for DL training and inference compute, the Habana Gaudi2 accelerator is the optimal accelerator. It is purpose-designed to deliver the best DL performance and TCO for these dedicated use cases.
About the Results for Xeon
Intel submitted MLPerf Training v2.1 results on the 4th Gen Intel Xeon Scalable processor product line across a range of workloads. Intel Xeon Scalable Processor was the only CPU submitted for MLPerf v2.1, once again demonstrating it is the best server CPU for AI training, which enables customers to use their shared infrastructure to train anywhere, anytime. The 4th Gen Intel Xeon Scalable processors with Intel AMX deliver this performance out of the box across multiple industry standard frameworks and integrated with end-to-end data science tools and a broad ecosystem of smart solutions from partners. Developers only need to use the latest framework releases of TensorFlow and PyTorch to unleash this performance. Intel Xeon Scalable can now run any AI workload.
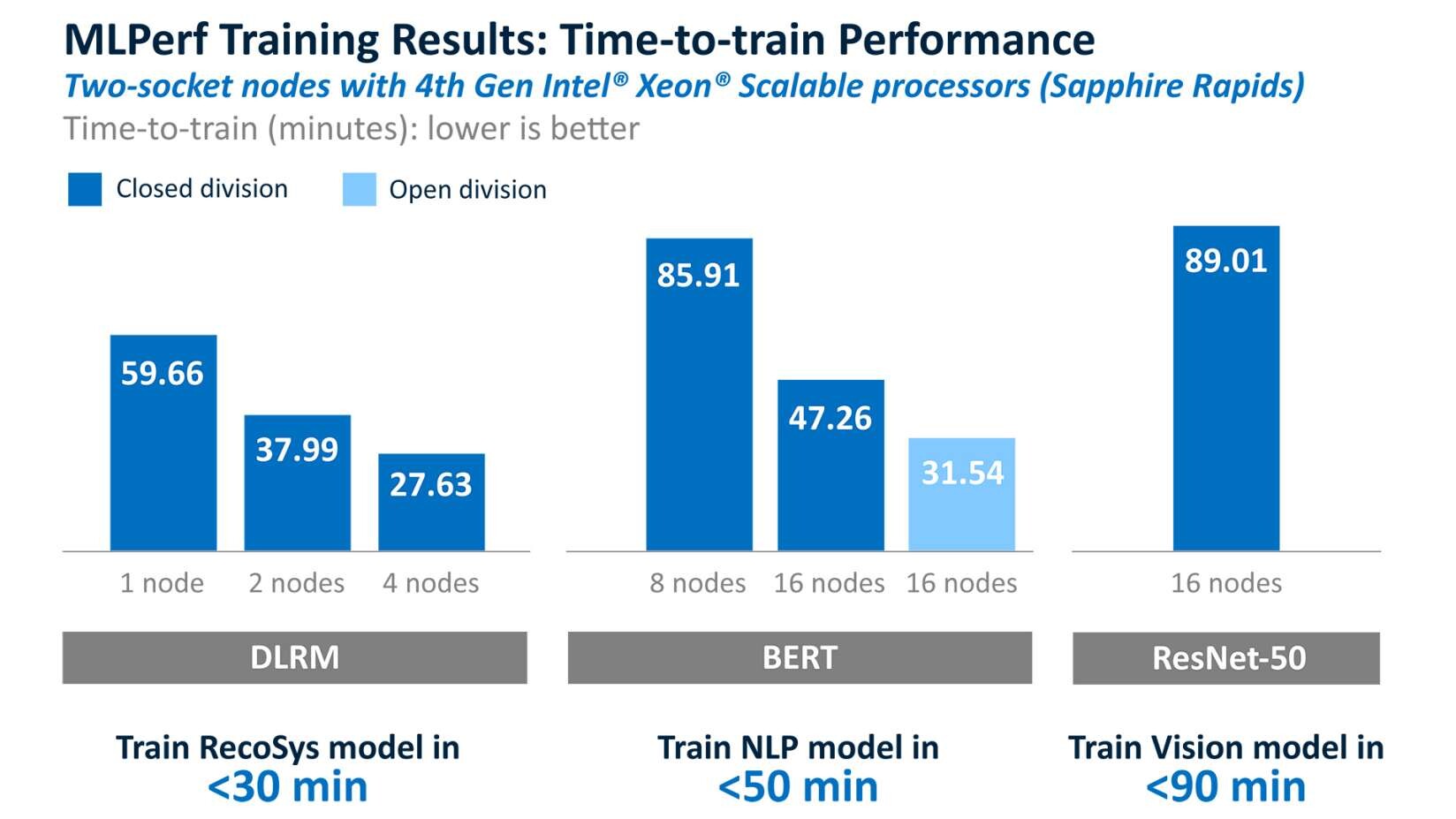
Intel's results show that 4th Gen Intel Xeon Scalable processors are expanding the reach of general-purpose CPUs for AI training, so customers can do more with Xeons that are already running their businesses.This is especially true for training medium to small models or transfer learning (aka fine tuning). The DLRM results are great examples of where we were able to train the model in less than 30 minutes (26.73) with only four server nodes. Even for mid-sized and larger models, 4th Gen Xeon processors could train BERT and ResNet-50 models in less than 50 minutes (47.26) and less than 90 minutes (89.01), respectively. Developers can now train small DL models over a coffee break, mid-sized models over lunch and use those same servers connected to data storage systems to utilize other analytics techniques like classical machine learning in the afternoon. This allows the enterprise to conserve deep learning processors, like Gaudi2, for the largest, most demanding models.
About the Results for Habana Gaudi2
Gaudi2, Habana's second-generation DL processor, launched in May and submitted leadership results on MLPerf v2.0 training 10 days later. Gaudi2, produced in 7 nanometer process and featuring 24 tensor processor cores, 96 GB on-board HBM2e memory and 24 100 integrated gigabit Ethernet ports, has again shown leading eight-card server performance on the benchmark compared to Nvidia's A100.
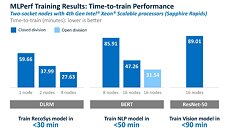
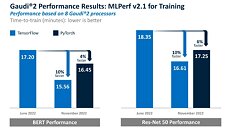
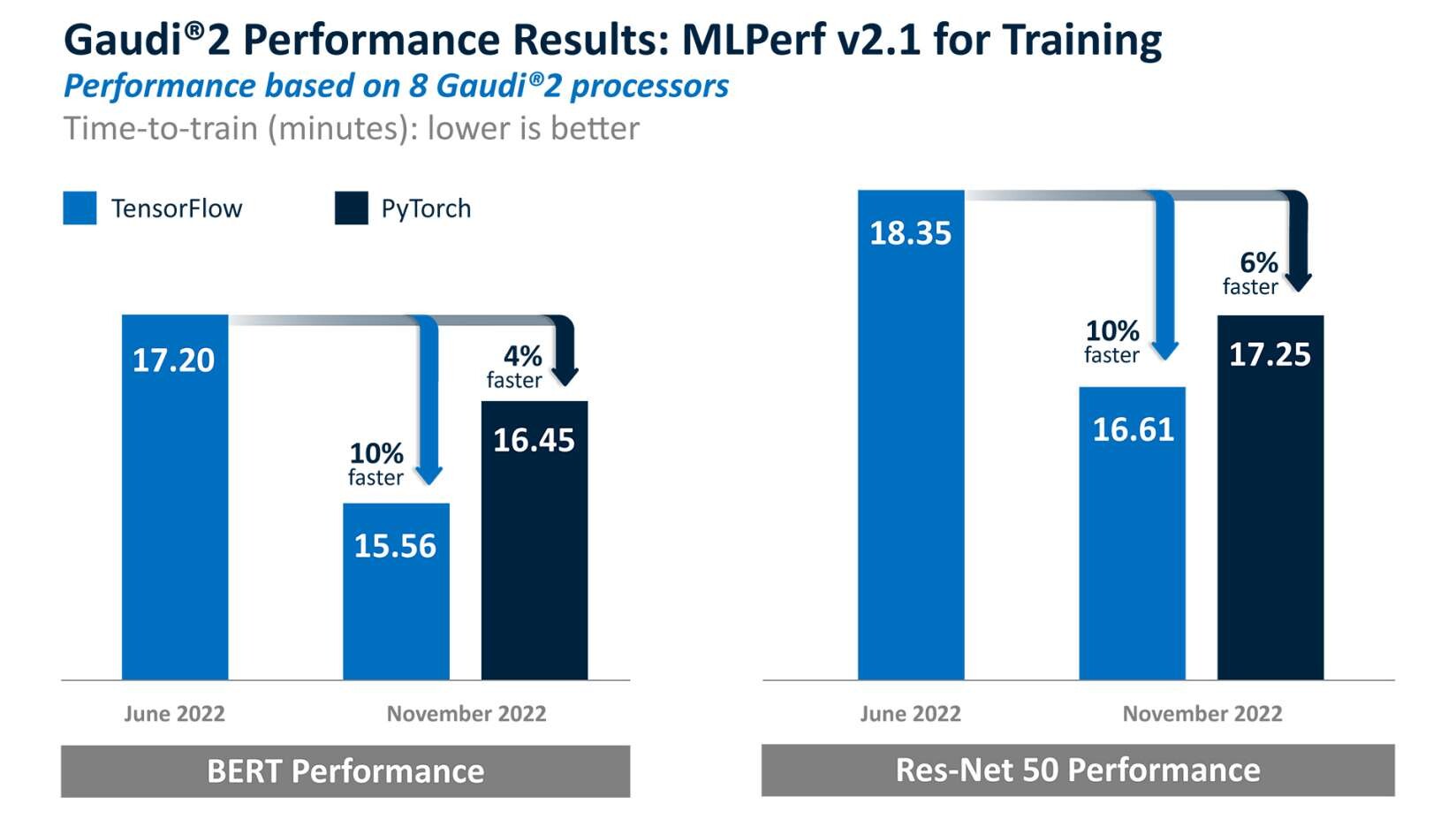
As shown here, Gaudi2 improved by 10% for time-to-train in TensorFlow for both BERT and ResNet-50, and reported results on PyTorch, which achieved 4% and 6% TTT advantage for BERT and ResNet-50, respectively, over the May Gaudi2 submission. Both sets of results were submitted in the closed and available categories.
These rapid advances underscore the uniqueness of the Gaudi2 purpose-built DL architecture, the increasing maturity of Gaudi2 software and expansion of the Habana SynapseAI software stack, optimized for deep learning model development and deployment.
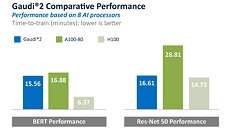
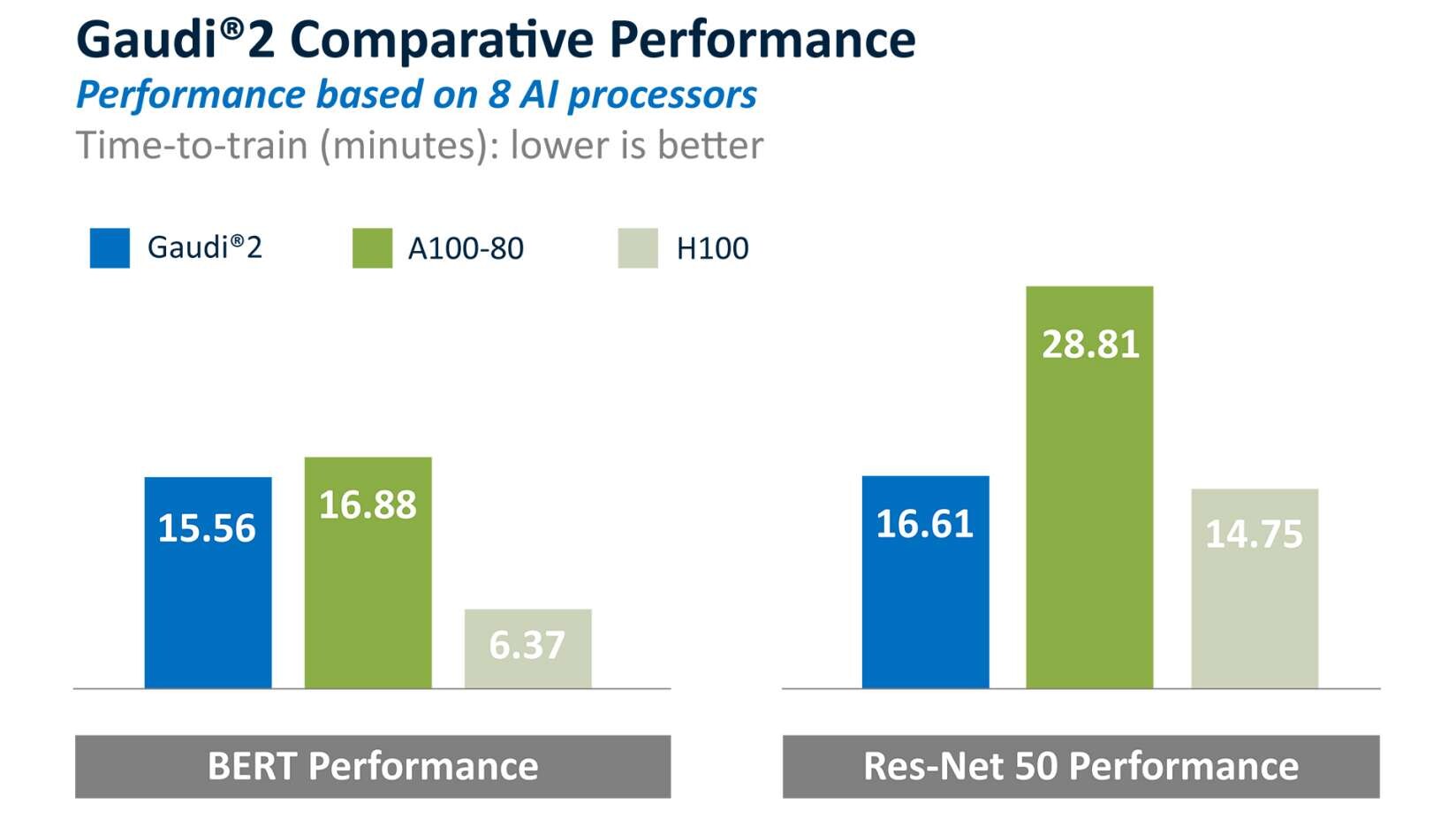
As further evidence of the strength of the results, Gaudi2 continued to outperform the Nvidia A100 for both BERT and ResNet-50, as it did in the May submission and shown here. In addition, it's notable that Nvidia's H100 ResNet-50 TTT is only 11% faster than the Gaudi2 performance. And though the H100 is 59% faster than Gaudi2 on BERT, it is worth noting that Nvidia reported BERT TTT in the FP8 data type, while Gaudi2 TTT is on standard, verified BF16 data type (with FP8 enablement in the software plans for Gaudi2). Gaudi2 offers meaningful price-performance improvement versus both A100 and H100.
The Intel and Habana team look forward to its next MLPerf submissions for Intel AI portfolio solutions.
View at TechPowerUp Main Site | Source
"I'm proud of our team's continued progress since we last submitted leadership results on MLPerf in June. Intel's 4th gen Xeon Scalable processor and Gaudi 2 AI accelerator support a wide array of AI functions and deliver leadership performance for customers who require deep learning training and large-scale workloads." Sandra Rivera, Intel executive vice president and general manager of the Datacenter and AI Group


Why It Matters
In many data center use cases, deep learning (DL) is part of a complex pipeline of machine learning (ML) and data analytics running on Xeon-based servers that are also used to run other applications and are adaptable to workload demands changing over time. It is in these use cases that Xeon Scalable delivers the best total cost of ownership (TCO) and year-round utilization.
The 4th Generation Intel Xeon Scalable processor with Intel Advanced Matrix Extensions (AMX), a new built-in AI accelerator, allows customers to extend the general-purpose Xeon server platform to cover even more DL use cases, including DL training and fine tuning. AMX is a dedicated matrix multiplication engine built into every core of 4th Gen Intel Xeon Scalable processors. This dedicated AI engine is optimized to deliver up to 6x higher gen-to-gen DL training model performance using industry standard frameworks.
In cases where the server or a cluster of servers are predominantly used for DL training and inference compute, the Habana Gaudi2 accelerator is the optimal accelerator. It is purpose-designed to deliver the best DL performance and TCO for these dedicated use cases.
About the Results for Xeon
Intel submitted MLPerf Training v2.1 results on the 4th Gen Intel Xeon Scalable processor product line across a range of workloads. Intel Xeon Scalable Processor was the only CPU submitted for MLPerf v2.1, once again demonstrating it is the best server CPU for AI training, which enables customers to use their shared infrastructure to train anywhere, anytime. The 4th Gen Intel Xeon Scalable processors with Intel AMX deliver this performance out of the box across multiple industry standard frameworks and integrated with end-to-end data science tools and a broad ecosystem of smart solutions from partners. Developers only need to use the latest framework releases of TensorFlow and PyTorch to unleash this performance. Intel Xeon Scalable can now run any AI workload.
Intel's results show that 4th Gen Intel Xeon Scalable processors are expanding the reach of general-purpose CPUs for AI training, so customers can do more with Xeons that are already running their businesses.This is especially true for training medium to small models or transfer learning (aka fine tuning). The DLRM results are great examples of where we were able to train the model in less than 30 minutes (26.73) with only four server nodes. Even for mid-sized and larger models, 4th Gen Xeon processors could train BERT and ResNet-50 models in less than 50 minutes (47.26) and less than 90 minutes (89.01), respectively. Developers can now train small DL models over a coffee break, mid-sized models over lunch and use those same servers connected to data storage systems to utilize other analytics techniques like classical machine learning in the afternoon. This allows the enterprise to conserve deep learning processors, like Gaudi2, for the largest, most demanding models.
About the Results for Habana Gaudi2
Gaudi2, Habana's second-generation DL processor, launched in May and submitted leadership results on MLPerf v2.0 training 10 days later. Gaudi2, produced in 7 nanometer process and featuring 24 tensor processor cores, 96 GB on-board HBM2e memory and 24 100 integrated gigabit Ethernet ports, has again shown leading eight-card server performance on the benchmark compared to Nvidia's A100.
As shown here, Gaudi2 improved by 10% for time-to-train in TensorFlow for both BERT and ResNet-50, and reported results on PyTorch, which achieved 4% and 6% TTT advantage for BERT and ResNet-50, respectively, over the May Gaudi2 submission. Both sets of results were submitted in the closed and available categories.
These rapid advances underscore the uniqueness of the Gaudi2 purpose-built DL architecture, the increasing maturity of Gaudi2 software and expansion of the Habana SynapseAI software stack, optimized for deep learning model development and deployment.
As further evidence of the strength of the results, Gaudi2 continued to outperform the Nvidia A100 for both BERT and ResNet-50, as it did in the May submission and shown here. In addition, it's notable that Nvidia's H100 ResNet-50 TTT is only 11% faster than the Gaudi2 performance. And though the H100 is 59% faster than Gaudi2 on BERT, it is worth noting that Nvidia reported BERT TTT in the FP8 data type, while Gaudi2 TTT is on standard, verified BF16 data type (with FP8 enablement in the software plans for Gaudi2). Gaudi2 offers meaningful price-performance improvement versus both A100 and H100.
The Intel and Habana team look forward to its next MLPerf submissions for Intel AI portfolio solutions.
View at TechPowerUp Main Site | Source


