- Joined
- Oct 9, 2007
- Messages
- 47,447 (7.50/day)
- Location
- Hyderabad, India
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | ASUS ROG Strix B450-E Gaming |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 8GB G.Skill Sniper X |
| Video Card(s) | Palit GeForce RTX 2080 SUPER GameRock |
| Storage | Western Digital Black NVMe 512GB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
Finding itself embattled with AMD's EPYC "Genoa" processors, Intel is giving its 4th Gen Xeon Scalable "Sapphire Rapids" processor a rather quick succession in the form of the Xeon Scalable "Emerald Rapids," bound for Q4-2023 (about 8-10 months in). The new processor shares the same LGA4677 platform and infrastructure, and much of the same I/O, but brings about two key design changes that should help Intel shore up per-core performance, making it competitive to EPYC "Zen 4" processors with higher core-counts. SemiAnalysis compiled a nice overview of the changes, the two broadest points of it being—1. Intel is peddling back on the chiplet approach to high core-count CPUs, and 2., that it wants to give the memory sub-system and inter-core performance a massive performance boost using larger on-die caches.
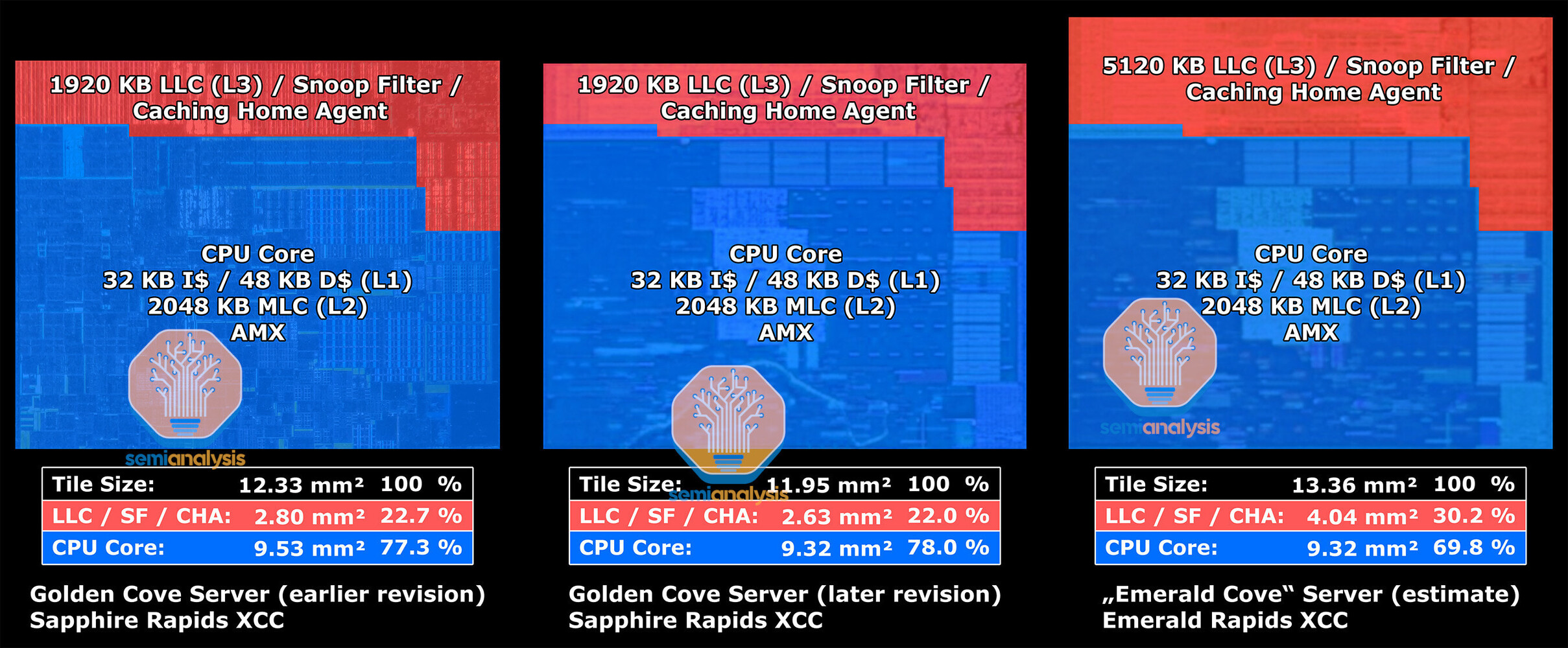
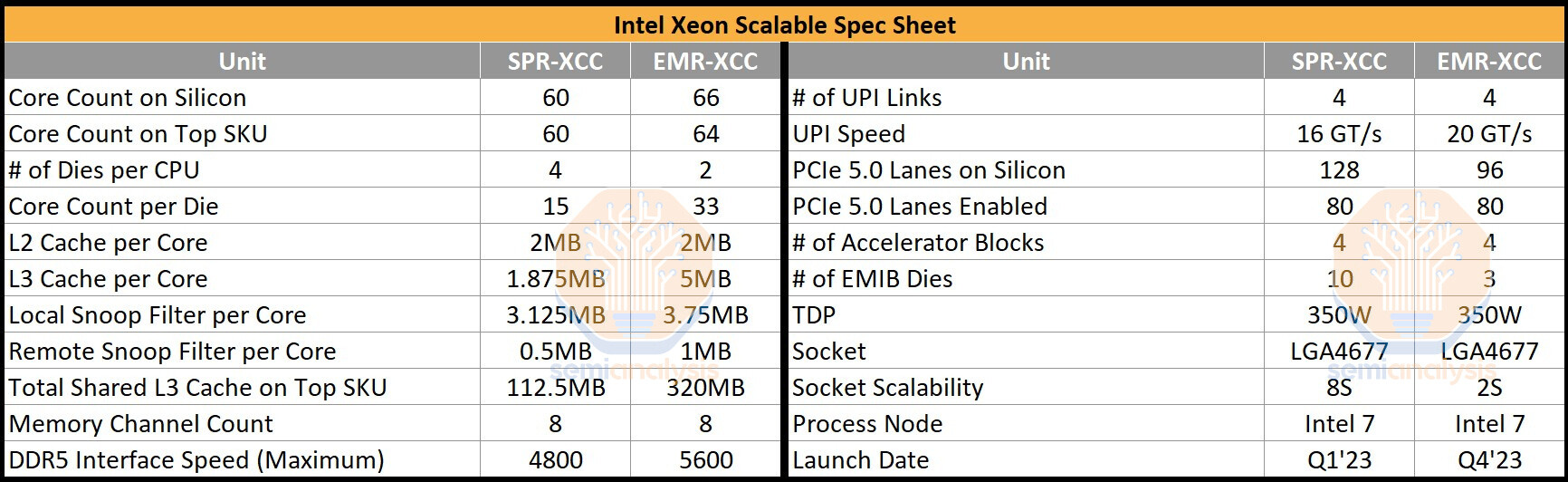
The "Emerald Rapids" processor has just two large dies in its extreme core-count (XCC) avatar, compared to "Sapphire Rapids," which can have up to four of these. There are just three EMIB dies interconnecting these two, compared to "Sapphire Rapids," which needs as many as 10 of these to ensure direct paths among the four dies. The CPU core count itself doesn't see a notable increase. Each of the two dies on "Emerald Rapids" physically features 33 CPU cores, so a total of 66 are physically present, although one core per die is left unused for harvesting, the SemiAnalysis article notes. So the maximum core-count possible commercially is 32 cores per die, or 64 cores per socket. "Emerald Rapids" continues to be based on the Intel 7 process (10 nm Enhanced SuperFin), probably with a few architectural improvements for higher clock-speeds.



As SemiAnalysis notes, the I/O is nearly identical between "Sapphire Rapids" and "Emerald Rapids." The processor puts out four 20 GT/s UPI links for inter-socket communication. Each of the two dies has a PCI-Express Gen 5 root-complex with 48 lanes, however only 40 of these are wired out. So the processor puts out a total of 80 PCIe Gen 5 lanes. This is an identical count to that of "Sapphire Rapids," which put out 32 lanes per chiplet, 128 in total, but only 20 lanes per die would be wired out. The memory interface is the same, with the processor featuring an 8-channel DDR5 interface, but the native memory speed sees an upgrade to DDR5-5600, up from the present DDR5-4800.
While "Sapphire Rapids" uses enterprise variants of the "Golden Cove" CPU cores that have 2 MB of dedicated L2 caches, "Emerald Rapids" use the more modern "Raptor Cove" cores that also power Intel's 13th Gen Core client processors. Each of the 66 cores has 2 MB of dedicated L2 cache. What's new, according to SemiAnalysis, is that each core has a large 5 MB segment of L3 cache, compared to "Golden Cove" enterprise, which only has a 1.875 MB segment, a massive 166% increase. The maximum amount of L3 cache possible on a 60-core "Sapphire Rapids" processor is 112.5 MB, whereas for the top 64-core "Emerald Rapids" SKU, this number is 320 MB, a 184% increase. Intel has also increased the cache snoop filter sizes per core.


SemiAnalysis also calculated that despite being based on the same Intel 7 process as "Sapphire Rapids," it would cost Intel less to make an "Emerald Rapids" processor with slightly higher core-count and much larger caches. Without scribe lines, the four dies making up "Sapphire Rapids" add up to 1,510 mm² of die-area, whereas the two dies making up "Emerald Rapids" only add up to 1,493 mm². Intel calculates that it can carve out all the relevant CPU core-count based SKUs by either giving the processor 1 or 2 dies, and doesn't need 4 of them for finer-grained SKU segmentation. AMD uses up to twelve 8-core "Zen 4" CCDs to achieve its 96-core count.
View at TechPowerUp Main Site | Source
The "Emerald Rapids" processor has just two large dies in its extreme core-count (XCC) avatar, compared to "Sapphire Rapids," which can have up to four of these. There are just three EMIB dies interconnecting these two, compared to "Sapphire Rapids," which needs as many as 10 of these to ensure direct paths among the four dies. The CPU core count itself doesn't see a notable increase. Each of the two dies on "Emerald Rapids" physically features 33 CPU cores, so a total of 66 are physically present, although one core per die is left unused for harvesting, the SemiAnalysis article notes. So the maximum core-count possible commercially is 32 cores per die, or 64 cores per socket. "Emerald Rapids" continues to be based on the Intel 7 process (10 nm Enhanced SuperFin), probably with a few architectural improvements for higher clock-speeds.


As SemiAnalysis notes, the I/O is nearly identical between "Sapphire Rapids" and "Emerald Rapids." The processor puts out four 20 GT/s UPI links for inter-socket communication. Each of the two dies has a PCI-Express Gen 5 root-complex with 48 lanes, however only 40 of these are wired out. So the processor puts out a total of 80 PCIe Gen 5 lanes. This is an identical count to that of "Sapphire Rapids," which put out 32 lanes per chiplet, 128 in total, but only 20 lanes per die would be wired out. The memory interface is the same, with the processor featuring an 8-channel DDR5 interface, but the native memory speed sees an upgrade to DDR5-5600, up from the present DDR5-4800.
While "Sapphire Rapids" uses enterprise variants of the "Golden Cove" CPU cores that have 2 MB of dedicated L2 caches, "Emerald Rapids" use the more modern "Raptor Cove" cores that also power Intel's 13th Gen Core client processors. Each of the 66 cores has 2 MB of dedicated L2 cache. What's new, according to SemiAnalysis, is that each core has a large 5 MB segment of L3 cache, compared to "Golden Cove" enterprise, which only has a 1.875 MB segment, a massive 166% increase. The maximum amount of L3 cache possible on a 60-core "Sapphire Rapids" processor is 112.5 MB, whereas for the top 64-core "Emerald Rapids" SKU, this number is 320 MB, a 184% increase. Intel has also increased the cache snoop filter sizes per core.

SemiAnalysis also calculated that despite being based on the same Intel 7 process as "Sapphire Rapids," it would cost Intel less to make an "Emerald Rapids" processor with slightly higher core-count and much larger caches. Without scribe lines, the four dies making up "Sapphire Rapids" add up to 1,510 mm² of die-area, whereas the two dies making up "Emerald Rapids" only add up to 1,493 mm². Intel calculates that it can carve out all the relevant CPU core-count based SKUs by either giving the processor 1 or 2 dies, and doesn't need 4 of them for finer-grained SKU segmentation. AMD uses up to twelve 8-core "Zen 4" CCDs to achieve its 96-core count.
View at TechPowerUp Main Site | Source






