- Joined
- May 21, 2024
- Messages
- 627 (3.60/day)
Today, Cerebras Systems, the pioneer in high performance AI compute, announced Cerebras Inference, the fastest AI inference solution in the world. Delivering 1,800 tokens per second for Llama3.1 8B and 450 tokens per second for Llama3.1 70B, Cerebras Inference is 20 times faster than NVIDIA GPU-based solutions in hyperscale clouds. Starting at just 10c per million tokens, Cerebras Inference is priced at a fraction of GPU solutions, providing 100x higher price-performance for AI workloads.
Unlike alternative approaches that compromise accuracy for performance, Cerebras offers the fastest performance while maintaining state of the art accuracy by staying in the 16-bit domain for the entire inference run. Cerebras Inference is priced at a fraction of GPU-based competitors, with pay-as-you-go pricing of 10 cents per million tokens for Llama 3.1 8B and 60 cents per million tokens for Llama 3.1 70B.

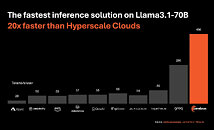
"Cerebras has taken the lead in Artificial Analysis' AI inference benchmarks. Cerebras is delivering speeds an order of magnitude faster than GPU-based solutions for Meta's Llama 3.1 8B and 70B AI models. We are measuring speeds above 1,800 output tokens per second on Llama 3.1 8B, and above 446 output tokens per second on Llama 3.1 70B - a new record in these benchmarks," said Micah Hill-Smith, Co-Founder and CEO of Artificial Analysis.
"Artificial Analysis has verified that Llama 3.1 8B and 70B on Cerebras Inference achieve quality evaluation results in line with native 16-bit precision per Meta's official versions. With speeds that push the performance frontier and competitive pricing, Cerebras Inference is particularly compelling for developers of AI applications with real-time or high volume requirements," Hill-Smith concluded.
Inference is the fastest growing segment of AI compute and constitutes approximately 40% of the total AI hardware market. The advent of high-speed AI inference, exceeding 1,000 tokens per second, is comparable to the introduction of broadband internet, unleashing vast new opportunities and heralding a new era for AI applications. Cerebras' 16-bit accuracy and 20x faster inference calls empowers developers to build next-generation AI applications that require complex, multi-step, real-time performance of tasks, such as AI agents.
"DeepLearning.AI has multiple agentic workflows that require prompting an LLM repeatedly to get a result. Cerebras has built an impressively fast inference capability which will be very helpful to such workloads," said Dr. Andrew Ng, Founder of DeepLearning.AI.
AI leaders in large companies and startups alike agree that faster is better:
Cerebras has made its inference service available across three competitively priced tiers: Free, Developer, and Enterprise.
Strategic Partnerships to Accelerate AI Development - Building AI applications requires a range of specialized tools at each stage, from open-source model giants to frameworks like LangChain and LlamaIndex that enable rapid development. Others like Docker, which ensures consistent containerization and deployment of AI-powered applications, and MLOps tools like Weights & Biases that maintain operational efficiency. At the forefront of innovation, companies like Meter are revolutionizing AI-powered network management, while learning platforms like DeepLearning.AI are equipping the next generation of developers with critical skills. Cerebras is proud to collaborate with these industry leaders, including Docker, Nasdaq, LangChain, LlamaIndex, Weights & Biases, Weaviate, AgentOps, and Log10 to drive the future of AI forward.
Cerebras Inference is powered by the Cerebras CS-3 system and its industry-leading AI processor — the Wafer Scale Engine 3 (WSE-3). Unlike graphic processing units that force customers to make trade-offs between speed and capacity, the CS-3 delivers best in class per-user performance while delivering high throughput. The massive size of the WSE-3 enables many concurrent users to benefit from blistering speed. With 7,000x more memory bandwidth than the Nvidia H100, the WSE-3 solves Generative AI's fundamental technical challenge: memory bandwidth.
Developers can easily access the Cerebras Inference API, which is fully compatible with the OpenAI Chat Completions API, making migration seamless with just a few lines of code.
View at TechPowerUp Main Site | Source
Unlike alternative approaches that compromise accuracy for performance, Cerebras offers the fastest performance while maintaining state of the art accuracy by staying in the 16-bit domain for the entire inference run. Cerebras Inference is priced at a fraction of GPU-based competitors, with pay-as-you-go pricing of 10 cents per million tokens for Llama 3.1 8B and 60 cents per million tokens for Llama 3.1 70B.


"Cerebras has taken the lead in Artificial Analysis' AI inference benchmarks. Cerebras is delivering speeds an order of magnitude faster than GPU-based solutions for Meta's Llama 3.1 8B and 70B AI models. We are measuring speeds above 1,800 output tokens per second on Llama 3.1 8B, and above 446 output tokens per second on Llama 3.1 70B - a new record in these benchmarks," said Micah Hill-Smith, Co-Founder and CEO of Artificial Analysis.
"Artificial Analysis has verified that Llama 3.1 8B and 70B on Cerebras Inference achieve quality evaluation results in line with native 16-bit precision per Meta's official versions. With speeds that push the performance frontier and competitive pricing, Cerebras Inference is particularly compelling for developers of AI applications with real-time or high volume requirements," Hill-Smith concluded.
Inference is the fastest growing segment of AI compute and constitutes approximately 40% of the total AI hardware market. The advent of high-speed AI inference, exceeding 1,000 tokens per second, is comparable to the introduction of broadband internet, unleashing vast new opportunities and heralding a new era for AI applications. Cerebras' 16-bit accuracy and 20x faster inference calls empowers developers to build next-generation AI applications that require complex, multi-step, real-time performance of tasks, such as AI agents.
"DeepLearning.AI has multiple agentic workflows that require prompting an LLM repeatedly to get a result. Cerebras has built an impressively fast inference capability which will be very helpful to such workloads," said Dr. Andrew Ng, Founder of DeepLearning.AI.
AI leaders in large companies and startups alike agree that faster is better:
- "Speed and scale change everything," said Kim Branson, SVP of AI/ML at GlaxoSmithKline, an early Cerebras customer.
- "LiveKit is excited to partner with Cerebras to help developers build the next generation of multimodal AI applications. Combining Cerebras' best-in-class compute and SoTA models with LiveKit's global edge network, developers can now create voice and video-based AI experiences with ultra-low latency and more human-like characteristics," said Russell D'sa, CEO and Co-Founder of LiveKit.
- "For traditional search engines, we know that lower latencies drive higher user engagement and that instant results have changed the way people interact with search and with the internet. At Perplexity, we believe ultra-fast inference speeds like what Cerebras is demonstrating can have a similar unlock for user interaction with the future of search - intelligent answer engines," said Denis Yarats, CTO and co-founder, Perplexity.
- "With infrastructure, speed is paramount. The performance of Cerebras Inference supercharges Meter Command to generate custom software and take action, all at the speed and ease of searching on the web. This level of responsiveness helps our customers get the information they need, exactly when they need it in order to keep their teams online and productive," said Anil Varanasi, CEO of Meter.
Cerebras has made its inference service available across three competitively priced tiers: Free, Developer, and Enterprise.
- The Free Tier offers free API access and generous usage limits to anyone who logs in.
- The Developer Tier, designed for flexible, serverless deployment, provides users with an API endpoint at a fraction of the cost of alternatives in the market, with Llama 3.1 8B and 70B models priced at 10 cents and 60 cents per million tokens, respectively. Looking ahead, Cerebras will be continuously rolling out support for many more models.
- The Enterprise Tier offers fine-tuned models, custom service level agreements, and dedicated support. Ideal for sustained workloads, enterprises can access Cerebras Inference via a Cerebras-managed private cloud or on customer premise. Pricing for enterprises is available upon request.
Strategic Partnerships to Accelerate AI Development - Building AI applications requires a range of specialized tools at each stage, from open-source model giants to frameworks like LangChain and LlamaIndex that enable rapid development. Others like Docker, which ensures consistent containerization and deployment of AI-powered applications, and MLOps tools like Weights & Biases that maintain operational efficiency. At the forefront of innovation, companies like Meter are revolutionizing AI-powered network management, while learning platforms like DeepLearning.AI are equipping the next generation of developers with critical skills. Cerebras is proud to collaborate with these industry leaders, including Docker, Nasdaq, LangChain, LlamaIndex, Weights & Biases, Weaviate, AgentOps, and Log10 to drive the future of AI forward.
Cerebras Inference is powered by the Cerebras CS-3 system and its industry-leading AI processor — the Wafer Scale Engine 3 (WSE-3). Unlike graphic processing units that force customers to make trade-offs between speed and capacity, the CS-3 delivers best in class per-user performance while delivering high throughput. The massive size of the WSE-3 enables many concurrent users to benefit from blistering speed. With 7,000x more memory bandwidth than the Nvidia H100, the WSE-3 solves Generative AI's fundamental technical challenge: memory bandwidth.
Developers can easily access the Cerebras Inference API, which is fully compatible with the OpenAI Chat Completions API, making migration seamless with just a few lines of code.
View at TechPowerUp Main Site | Source


