- Joined
- Oct 9, 2007
- Messages
- 47,885 (7.38/day)
- Location
- Dublin, Ireland
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | Gigabyte B550 AORUS Elite V2 |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 16GB DDR4-3200 |
| Video Card(s) | Galax RTX 4070 Ti EX |
| Storage | Samsung 990 1TB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
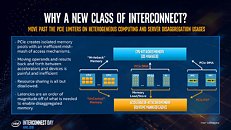
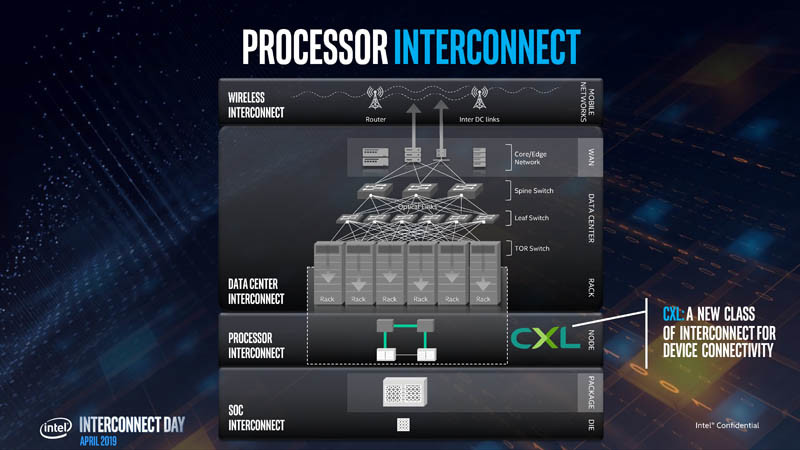
CXL, short for Compute Express Link, is an ambitious new interconnect technology for removable high-bandwidth devices, such as GPU-based compute accelerators, in a data-center environment. It is designed to overcome many of the technical limitations of PCI-Express, the least of which is bandwidth. Intel sensed that its upcoming family of scalable compute accelerators under the Xe band need a specialized interconnect, which Intel wants to push as the next industry standard. The development of CXL is also triggered by compute accelerator majors NVIDIA and AMD already having similar interconnects of their own, NVLink and InfinityFabric, respectively. At a dedicated event dubbed "Interconnect Day 2019," Intel put out a technical presentation that spelled out the nuts and bolts of CXL.
Intel began by describing why the industry needs CXL, and why PCI-Express (PCIe) doesn't suit its use-case. For a client-segment device, PCIe is perfect, since client-segment machines don't have too many devices, too large memory, and the applications don't have a very large memory footprint or scale across multiple machines. PCIe fails big in the data-center, when dealing with multiple bandwidth-hungry devices and vast shared memory pools. Its biggest shortcoming is isolated memory pools for each device, and inefficient access mechanisms. Resource-sharing is almost impossible. Sharing operands and data between multiple devices, such as two GPU accelerators working on a problem, is very inefficient. And lastly, there's latency, lots of it. Latency is the biggest enemy of shared memory pools that span across multiple physical machines. CXL is designed to overcome many of these problems without discarding the best part about PCIe - the simplicity and adaptability of its physical layer.



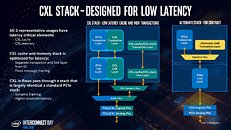
CXL uses the PCIe physical layer, and has raw on-paper bandwidth of 32 Gbps per lane, per direction, which aligns with PCIe gen 5.0 standard. The link layer is where all the secret-sauce is. Intel worked on new handshake, auto-negotiation, and transaction protocols replacing those of PCIe, designed to overcome its shortcomings listed above. With PCIe gen 5.0 already standardized by the PCI-SIG, Intel could share CXL IP back to the SIG with PCIe gen 6.0. In other words, Intel admits that CXL may not outlive PCIe, and until the PCI-SIG can standardize gen 6.0 (around 2021-22, if not later), CXL is the need of the hour.
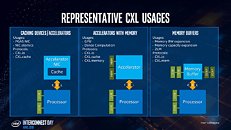

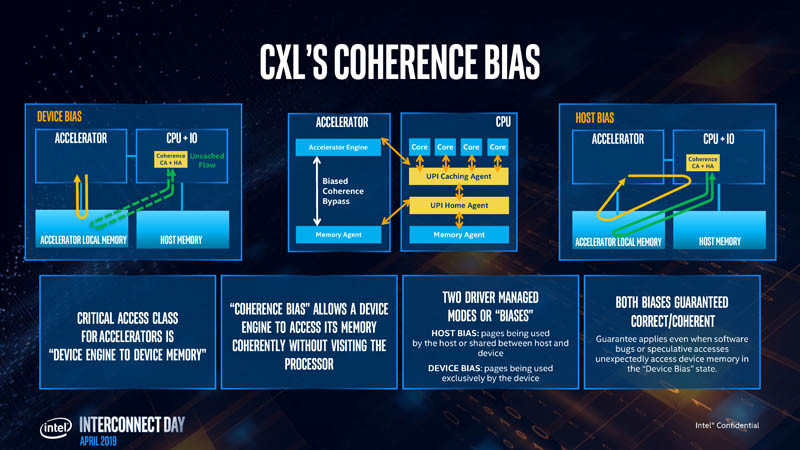
The CXL transaction layer consists of three multiplexed sub-protocols that run simultaneously on a single link. They are: CXL.io, CXL.cache, and CXL.memory. CXL.io deals with device discovery, link negotiation, interrupts, registry access, etc., which are basically tasks that get a machine to work with a device. CXL.cache deals with the device's access to a local processor's memory. CXL.memory deals with processor's access to non-local memory (memory controlled by another processor or another machine).



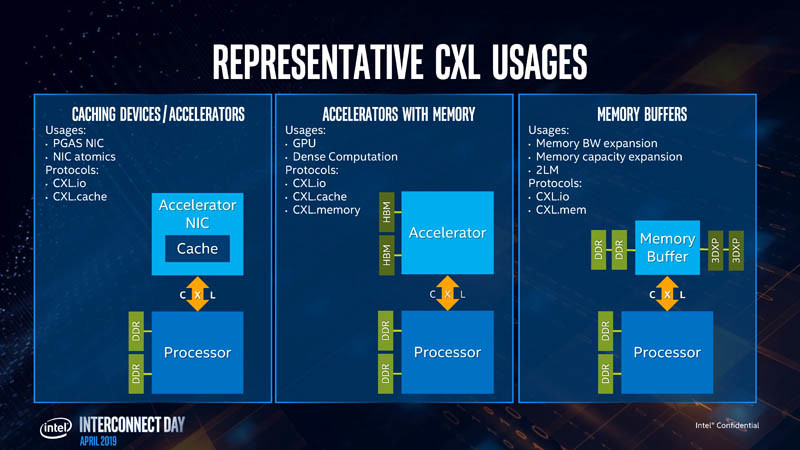
Intel listed out use-cases for CXL, which begins with accelerators with memory, such as graphics cards, GPU compute accelerators, and high-density compute cards. All three CXL transaction layer protocols are relevant to such devices. Next up, are FPGAs, and NICs. CXL.io and CXL.cache are relevant here, since network-stacks are processed by processors local to the NIC. Lastly, there are the all-important memory buffers. You can imagine these devices as "NAS, but with DRAM sticks." Future data-centers will consist of vast memory pools shared between thousands of physical machines and accelerators. CXL.memory and CXL.cache are relevant. Much of what makes the CXL link-layer faster than PCIe is its optimized stack (processing load for the CPU). The CXL stack is built from the ground up keeping low-latency as a design goal.
View at TechPowerUp Main Site
Intel began by describing why the industry needs CXL, and why PCI-Express (PCIe) doesn't suit its use-case. For a client-segment device, PCIe is perfect, since client-segment machines don't have too many devices, too large memory, and the applications don't have a very large memory footprint or scale across multiple machines. PCIe fails big in the data-center, when dealing with multiple bandwidth-hungry devices and vast shared memory pools. Its biggest shortcoming is isolated memory pools for each device, and inefficient access mechanisms. Resource-sharing is almost impossible. Sharing operands and data between multiple devices, such as two GPU accelerators working on a problem, is very inefficient. And lastly, there's latency, lots of it. Latency is the biggest enemy of shared memory pools that span across multiple physical machines. CXL is designed to overcome many of these problems without discarding the best part about PCIe - the simplicity and adaptability of its physical layer.



CXL uses the PCIe physical layer, and has raw on-paper bandwidth of 32 Gbps per lane, per direction, which aligns with PCIe gen 5.0 standard. The link layer is where all the secret-sauce is. Intel worked on new handshake, auto-negotiation, and transaction protocols replacing those of PCIe, designed to overcome its shortcomings listed above. With PCIe gen 5.0 already standardized by the PCI-SIG, Intel could share CXL IP back to the SIG with PCIe gen 6.0. In other words, Intel admits that CXL may not outlive PCIe, and until the PCI-SIG can standardize gen 6.0 (around 2021-22, if not later), CXL is the need of the hour.
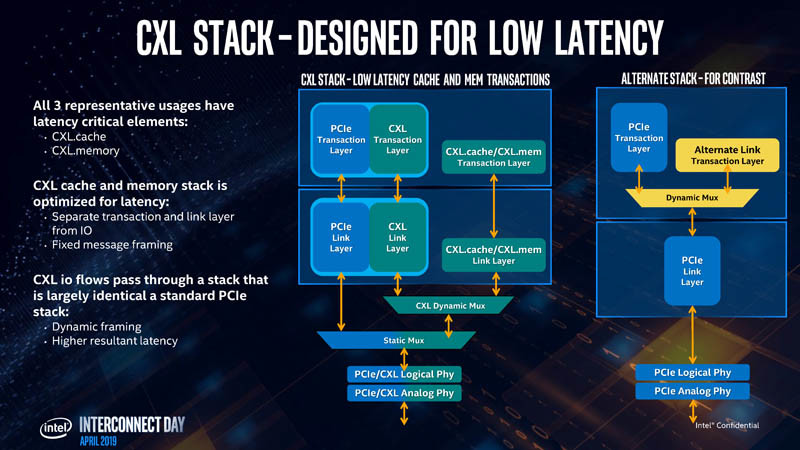
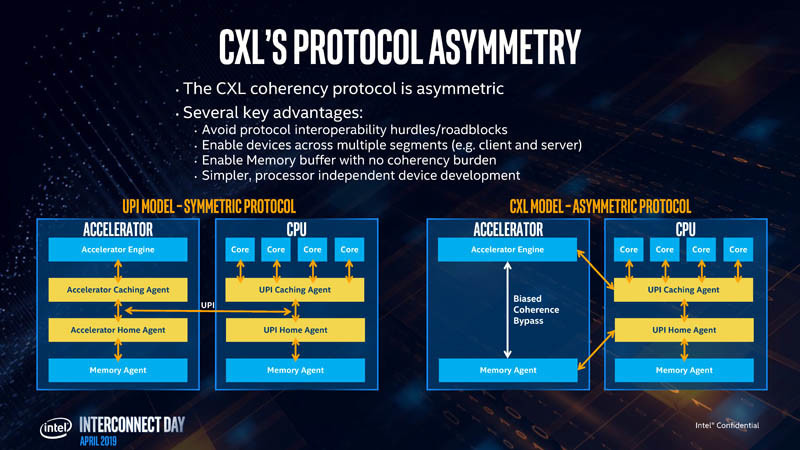
The CXL transaction layer consists of three multiplexed sub-protocols that run simultaneously on a single link. They are: CXL.io, CXL.cache, and CXL.memory. CXL.io deals with device discovery, link negotiation, interrupts, registry access, etc., which are basically tasks that get a machine to work with a device. CXL.cache deals with the device's access to a local processor's memory. CXL.memory deals with processor's access to non-local memory (memory controlled by another processor or another machine).


Intel listed out use-cases for CXL, which begins with accelerators with memory, such as graphics cards, GPU compute accelerators, and high-density compute cards. All three CXL transaction layer protocols are relevant to such devices. Next up, are FPGAs, and NICs. CXL.io and CXL.cache are relevant here, since network-stacks are processed by processors local to the NIC. Lastly, there are the all-important memory buffers. You can imagine these devices as "NAS, but with DRAM sticks." Future data-centers will consist of vast memory pools shared between thousands of physical machines and accelerators. CXL.memory and CXL.cache are relevant. Much of what makes the CXL link-layer faster than PCIe is its optimized stack (processing load for the CPU). The CXL stack is built from the ground up keeping low-latency as a design goal.
View at TechPowerUp Main Site



")
