- Joined
- Oct 9, 2007
- Messages
- 47,949 (7.37/day)
- Location
- Dublin, Ireland
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | Gigabyte B550 AORUS Elite V2 |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 16GB DDR4-3200 |
| Video Card(s) | Galax RTX 4070 Ti EX |
| Storage | Samsung 990 1TB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
Even as CPU vendors are working to mainstream accelerated AI for client PCs, and Microsoft setting the pace for more AI in everyday applications with Windows 11 23H2 Update; NVIDIA is out there reminding you that every GeForce RTX GPU is an AI accelerator. This is thanks to its Tensor cores, and the SIMD muscle of the ubiquitous CUDA cores. NVIDIA has been making these for over 5 years now, and has an install base of over 100 million. The company is hence focusing on bring generative AI acceleration to more client- and enthusiast relevant use-cases, such as large language models.
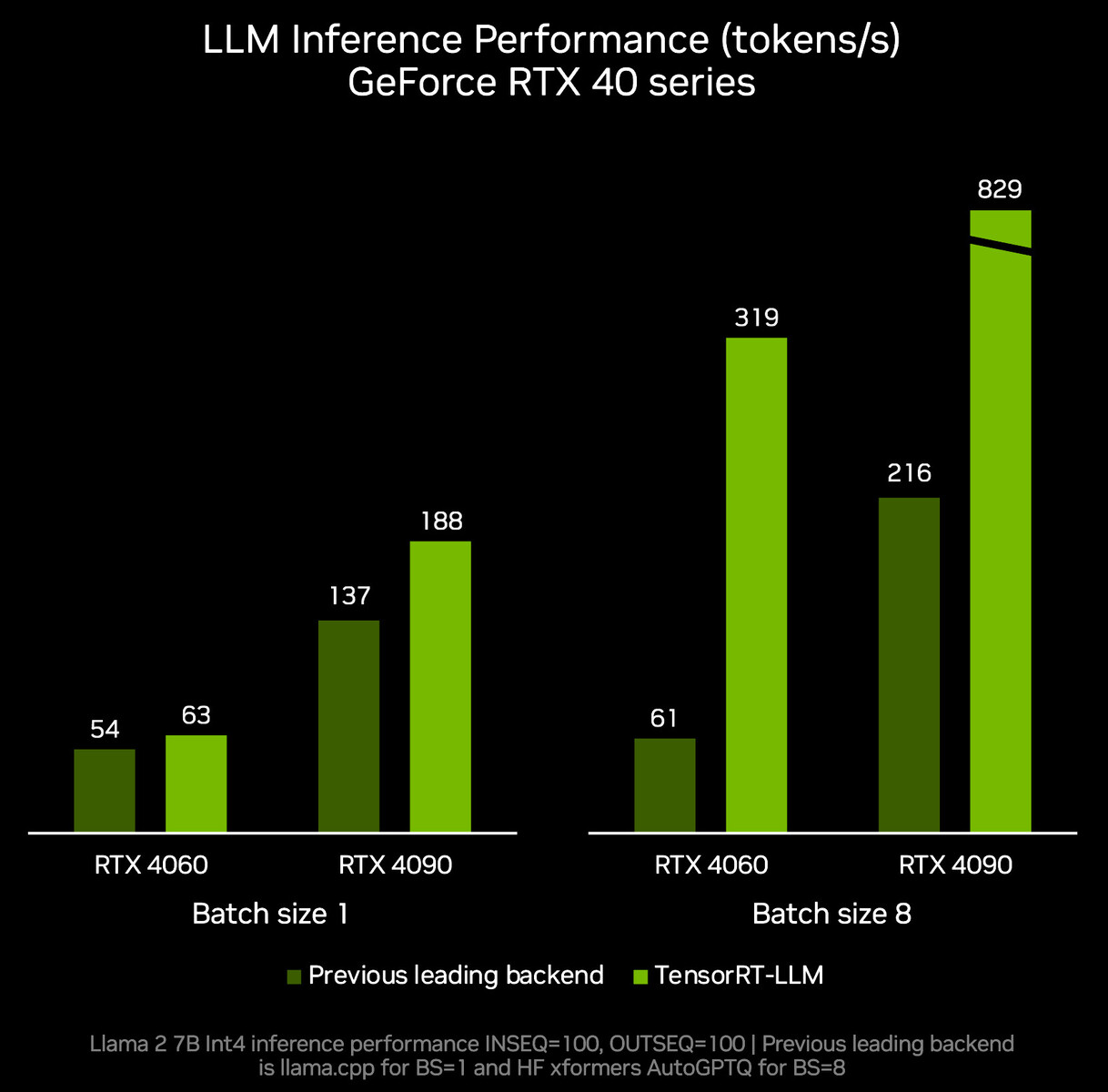
NVIDIA at the Microsoft Ignite event announced new optimizations, models, and resources to bring accelerated AI to everyone with an NVIDIA GPU that meets the hardware requirements. To begin with, the company introduced an update to TensorRT-LLM for Windows, a library that leverages NVIDIA RTX architecture for accelerating large language models (LLMs). The new TensorRT-LLM version 0.6.0 will release later this month, and improve LLM inference performance by up to 5 times in terms of tokens per second, when compared to the initial release of TensorRT-LLM from October 2023. In addition, TensorRT-LLM 0.6.0 will introduce support for popular LLMs, including Mistral 7B and Nemtron-3 8B. Accelerating these two will require a GeForce RTX 30-series "Ampere" or 40-series "Ada" GPU with at least 8 GB of main memory.


OpenAI's ChatGPT is the hottest consumer application since Google, but it is a cloud-based service, which entails transmitting information over the Internet, and is limited in the size of data-sets; making it impractical for enterprises or organizations that require foolproof data privacy and limitless scaling for data-sets, which only a localized AI can provide. NVIDIA will soon be enabling TensorRT-LLM for Windows to support a similar interface to ChatAPI through a new wrapper. NVIDIA says that for those developing applications around ChatAPI, it takes changing just 2 lines of code to benefit from local AI. The new wrapper will work with any LLM that's optimized for TensorRT-LLM, such as Llama 2, Mistral, and NV LLM. The company plans to release this as a reference project on GitHub.
NVIDIA is working with Microsoft to accelerate Llama 2 and Stable Diffusion on RTX via new optimizations the DirectML API. Developers can experience these by downloading the latest ONNX runtime along with a new upcoming version of NVIDIA GeForce drivers that the company will release on November 21, 2023.
View at TechPowerUp Main Site
NVIDIA at the Microsoft Ignite event announced new optimizations, models, and resources to bring accelerated AI to everyone with an NVIDIA GPU that meets the hardware requirements. To begin with, the company introduced an update to TensorRT-LLM for Windows, a library that leverages NVIDIA RTX architecture for accelerating large language models (LLMs). The new TensorRT-LLM version 0.6.0 will release later this month, and improve LLM inference performance by up to 5 times in terms of tokens per second, when compared to the initial release of TensorRT-LLM from October 2023. In addition, TensorRT-LLM 0.6.0 will introduce support for popular LLMs, including Mistral 7B and Nemtron-3 8B. Accelerating these two will require a GeForce RTX 30-series "Ampere" or 40-series "Ada" GPU with at least 8 GB of main memory.
OpenAI's ChatGPT is the hottest consumer application since Google, but it is a cloud-based service, which entails transmitting information over the Internet, and is limited in the size of data-sets; making it impractical for enterprises or organizations that require foolproof data privacy and limitless scaling for data-sets, which only a localized AI can provide. NVIDIA will soon be enabling TensorRT-LLM for Windows to support a similar interface to ChatAPI through a new wrapper. NVIDIA says that for those developing applications around ChatAPI, it takes changing just 2 lines of code to benefit from local AI. The new wrapper will work with any LLM that's optimized for TensorRT-LLM, such as Llama 2, Mistral, and NV LLM. The company plans to release this as a reference project on GitHub.
NVIDIA is working with Microsoft to accelerate Llama 2 and Stable Diffusion on RTX via new optimizations the DirectML API. Developers can experience these by downloading the latest ONNX runtime along with a new upcoming version of NVIDIA GeForce drivers that the company will release on November 21, 2023.
View at TechPowerUp Main Site

