- Joined
- Oct 9, 2007
- Messages
- 47,293 (7.53/day)
- Location
- Hyderabad, India
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | ASUS ROG Strix B450-E Gaming |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 8GB G.Skill Sniper X |
| Video Card(s) | Palit GeForce RTX 2080 SUPER GameRock |
| Storage | Western Digital Black NVMe 512GB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
With AMD and NVIDIA launching its next-generation HPC compute architectures, "Hopper" and CDNA2, it began seeming like Intel's ambitious "Ponte Vecchio" accelerator based on the Xe-HP architecture, has missed the time-to-market bus. Intel doesn't think so, and in its Hot Chips 34 presentation, disclosed some of the first detailed performance claims that—at least on paper—put the "Hopper" H100 accelerator's published compute performance numbers to shame. We already had some idea of how Ponte Vecchio would perform this spring, at Intel's ISC'22 presentation, but the company hadn't finalized the product's power and thermal characteristics, which are determined by its clock-speed and boosting behavior. Team blue claims to have gotten over the final development hurdles, and is ready with some big numbers.
Intel claims that in classic FP32 (single-precision) and FP64 (double-precision) floating-point tests, its silicon is highly competitive with the H100 "Hopper," with the company claiming 52 TFLOP/s FP32 for the "Ponte Vecchio," compared to 60 TFLOP/s for the H100; and a significantly higher 52 TFLOP/s FP64 for the "Ponte Vecchio," compared to 30 TFLOP/s for the H100. This has to do with the SIMD units of the Xe-HP architecture all being natively capable of double-precision floating-point operations; whereas NVIDIA's architecture typically relies on FP64-specialized streaming multiprocessors.
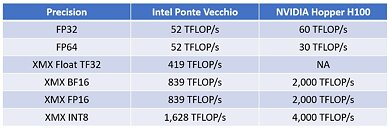
Where Intel claims dominance over NVIDIA is with the XMX-accelerated XMX-Float, an architecture-specific workload, where it scores 419 TFLOP/s. This test doesn't work on "Hopper," as it lacks specialized hardware. XMX-accelerated half-precision tests such as Bfloat16 (BF16) and FP16 performance is sub-par, with Intel claiming 839 TFLOP/s, compared to 2 PFLOP/s of the NVDIA chip. With 8-bit operations, such as INT8, even with XMX acceleration, "Ponte Vecchio" scores 1.678 PFLOP/s compared to 4 PFLOP/s of the NVIDIA chip.
Whether Intel has "missed the bus" for this generation in the HPC accelerator market will now boil down to pricing and availability. If Intel can manage good volumes, is able to leverage its oneAPI developer ecosystem, is able to score design wins with major HPC projects and cloud-compute providors; and most importantly, is able to beat "Hopper" in price-performance and energy-efficient, then Intel could remain relevant in this generation, and continue investments into the next.
View at TechPowerUp Main Site | Source
Intel claims that in classic FP32 (single-precision) and FP64 (double-precision) floating-point tests, its silicon is highly competitive with the H100 "Hopper," with the company claiming 52 TFLOP/s FP32 for the "Ponte Vecchio," compared to 60 TFLOP/s for the H100; and a significantly higher 52 TFLOP/s FP64 for the "Ponte Vecchio," compared to 30 TFLOP/s for the H100. This has to do with the SIMD units of the Xe-HP architecture all being natively capable of double-precision floating-point operations; whereas NVIDIA's architecture typically relies on FP64-specialized streaming multiprocessors.
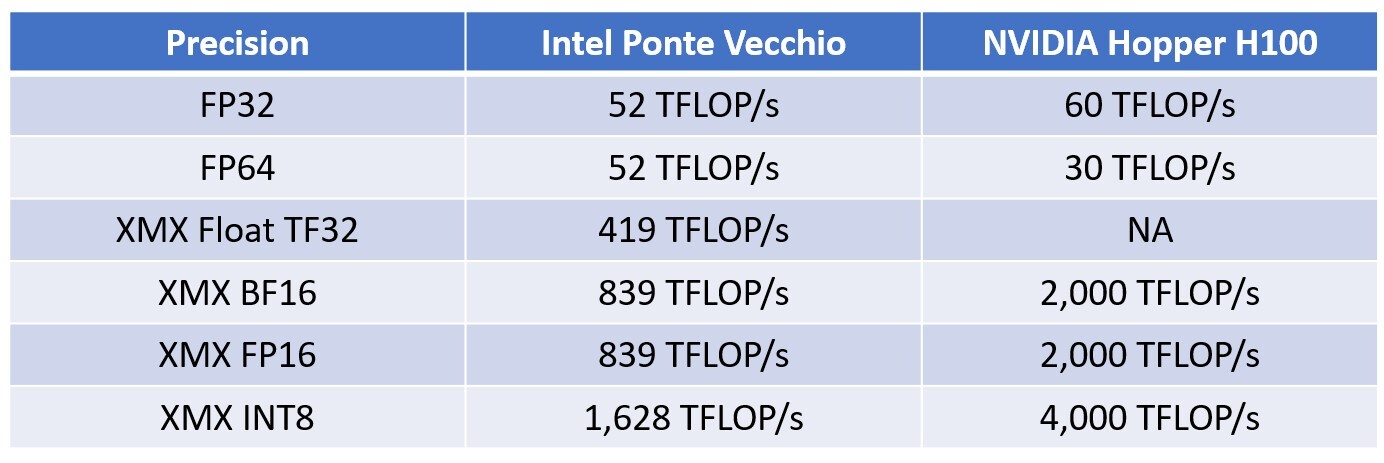
Where Intel claims dominance over NVIDIA is with the XMX-accelerated XMX-Float, an architecture-specific workload, where it scores 419 TFLOP/s. This test doesn't work on "Hopper," as it lacks specialized hardware. XMX-accelerated half-precision tests such as Bfloat16 (BF16) and FP16 performance is sub-par, with Intel claiming 839 TFLOP/s, compared to 2 PFLOP/s of the NVDIA chip. With 8-bit operations, such as INT8, even with XMX acceleration, "Ponte Vecchio" scores 1.678 PFLOP/s compared to 4 PFLOP/s of the NVIDIA chip.
Whether Intel has "missed the bus" for this generation in the HPC accelerator market will now boil down to pricing and availability. If Intel can manage good volumes, is able to leverage its oneAPI developer ecosystem, is able to score design wins with major HPC projects and cloud-compute providors; and most importantly, is able to beat "Hopper" in price-performance and energy-efficient, then Intel could remain relevant in this generation, and continue investments into the next.
View at TechPowerUp Main Site | Source


")
