Apr 16th, 2025 09:08 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Windows 11 fresh install to do list (22)
- 5070ti overclock...what are your settings? (4)
- Last game you purchased? (771)
- GPU Memory Temprature is always high (16)
- Help For XFX RX 590 GME Chinese - Vbios (4)
- PCGH: "hidden site" to see total money spend on steam (3)
- Share your AIDA 64 cache and memory benchmark here (3053)
- NVFlash for RTX 50 Series (Blackwell) (0)
- intel 1700 with high speed ram,memory (63)
- The TPU UK Clubhouse (26115)
Popular Reviews
- G.SKILL Trident Z5 NEO RGB DDR5-6000 32 GB CL26 Review - AMD EXPO
- ASUS GeForce RTX 5080 TUF OC Review
- DAREU A950 Wing Review
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Thermaltake TR100 Review
- Zotac GeForce RTX 5070 Ti Amp Extreme Review
- TerraMaster F8 SSD Plus Review - Compact and quiet
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (124)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (85)
- NVIDIA PhysX and Flow Made Fully Open-Source (77)
- NVIDIA Pushes GeForce RTX 5060 Ti Launch to Mid-April, RTX 5060 to May (77)
News Posts matching #CSS
Return to Keyword Browsing
Qualcomm Accuses Arm of Anticompetitive Practices in Global Regulatory Complaints
Qualcomm has filed confidential complaints with antitrust regulators in the US, Europe, and South Korea, accusing Arm Holdings of leveraging its dominance to suppress competition in chip design. The filings, submitted to the US FTC European Commission and Korea Fair Trade Commission, alleged that Arm is restricting access to critical technologies and altering licensing terms to favor its own chip ventures, Bloomberg reported. Arm swiftly denied the claims, claimining that this is a distraction from a broader commercial dispute. "Arm remains focused on enhancing innovation, promoting competition, and respecting contractual rights and obligations," a company spokesperson told Tom's Hardware. "Any allegation of anti-competitive conduct is nothing more than a desperate attempt by Qualcomm to detract from the merits and expand the parties' ongoing commercial dispute for its own competitive benefit. Arm is confident that it will ultimately prevail in this dispute."
Qualcomm's filings argue that Arm is abandoning its longstanding open licensing model, which enabled a global ecosystem of chipmakers and software developers. Instead, the company claims Arm is prioritizing its compute subsystems (CSS)—pre-packaged chip designs for client devices and data centers—by limiting rivals' ability to license core technologies. Qualcomm also alleges Arm is withholding IP and violating agreements, particularly for clients developing custom silicon based on CSS designs. The complaints follow a recent legal victory for Qualcomm in a Delaware court, where a judge ruled the company did not breach licensing deals by acquiring chip startup Nuvia and using its IP in Snapdragon X processors for PCs. Arm, which plans to appeal the decision, insists Qualcomm's regulatory push is an escalation of the same dispute. According to Bloomberg's sources, Qualcomm's EU complaint—filed before the December court ruling—warned that Arm's post-2024 licensing changes would force chipmakers to obtain direct architecture licenses to use CSS designs, which could marginalize competitors. Arm confirmed it is preparing a formal response to the EU filing, while Qualcomm has reportedly engaged regulators in Washington and Seoul on similar concerns.
Qualcomm's filings argue that Arm is abandoning its longstanding open licensing model, which enabled a global ecosystem of chipmakers and software developers. Instead, the company claims Arm is prioritizing its compute subsystems (CSS)—pre-packaged chip designs for client devices and data centers—by limiting rivals' ability to license core technologies. Qualcomm also alleges Arm is withholding IP and violating agreements, particularly for clients developing custom silicon based on CSS designs. The complaints follow a recent legal victory for Qualcomm in a Delaware court, where a judge ruled the company did not breach licensing deals by acquiring chip startup Nuvia and using its IP in Snapdragon X processors for PCs. Arm, which plans to appeal the decision, insists Qualcomm's regulatory push is an escalation of the same dispute. According to Bloomberg's sources, Qualcomm's EU complaint—filed before the December court ruling—warned that Arm's post-2024 licensing changes would force chipmakers to obtain direct architecture licenses to use CSS designs, which could marginalize competitors. Arm confirmed it is preparing a formal response to the EU filing, while Qualcomm has reportedly engaged regulators in Washington and Seoul on similar concerns.


Arm and Partners Develop AI CPU: Neoverse V3 CSS Made on 2 nm Samsung GAA FET
Yesterday, Arm has announced significant progress in its Total Design initiative. The program, launched a year ago, aims to accelerate the development of custom silicon for data centers by fostering collaboration among industry partners. The ecosystem has now grown to include nearly 30 participating companies, with recent additions such as Alcor Micro, Egis, PUF Security, and SEMIFIVE. A notable development is a partnership between Arm, Samsung Foundry, ADTechnology, and Rebellions to create an AI CPU chiplet platform. This collaboration aims to deliver a solution for cloud, HPC, and AI/ML workloads, combining Rebellions' AI accelerator with ADTechnology's compute chiplet, implemented using Samsung Foundry's 2 nm Gate-All-Around (GAA) FET technology. The platform is expected to offer significant efficiency gains for generative AI workloads, with estimates suggesting a 2-3x improvement over the standard CPU design for LLMs like Llama3.1 with 405 billion parameters.
Arm's approach emphasizes the importance of CPU compute in supporting the complete AI stack, including data pre-processing, orchestration, and advanced techniques like Retrieval-augmented Generation (RAG). The company's Compute Subsystems (CSS) are designed to address these requirements, providing a foundation for partners to build diverse chiplet solutions. Several companies, including Alcor Micro and Alphawave, have already announced plans to develop CSS-powered chiplets for various AI and high-performance computing applications. The initiative also focuses on software readiness, ensuring that major frameworks and operating systems are compatible with Arm-based systems. Recent efforts include the introduction of Arm Kleidi technology, which optimizes CPU-based inference for open-source projects like PyTorch and Llama.cpp. Notably, as Google claims, most AI workloads are being inferenced on CPUs, so creating the most efficient and most performant CPUs for AI makes a lot of sense.
Arm's approach emphasizes the importance of CPU compute in supporting the complete AI stack, including data pre-processing, orchestration, and advanced techniques like Retrieval-augmented Generation (RAG). The company's Compute Subsystems (CSS) are designed to address these requirements, providing a foundation for partners to build diverse chiplet solutions. Several companies, including Alcor Micro and Alphawave, have already announced plans to develop CSS-powered chiplets for various AI and high-performance computing applications. The initiative also focuses on software readiness, ensuring that major frameworks and operating systems are compatible with Arm-based systems. Recent efforts include the introduction of Arm Kleidi technology, which optimizes CPU-based inference for open-source projects like PyTorch and Llama.cpp. Notably, as Google claims, most AI workloads are being inferenced on CPUs, so creating the most efficient and most performant CPUs for AI makes a lot of sense.

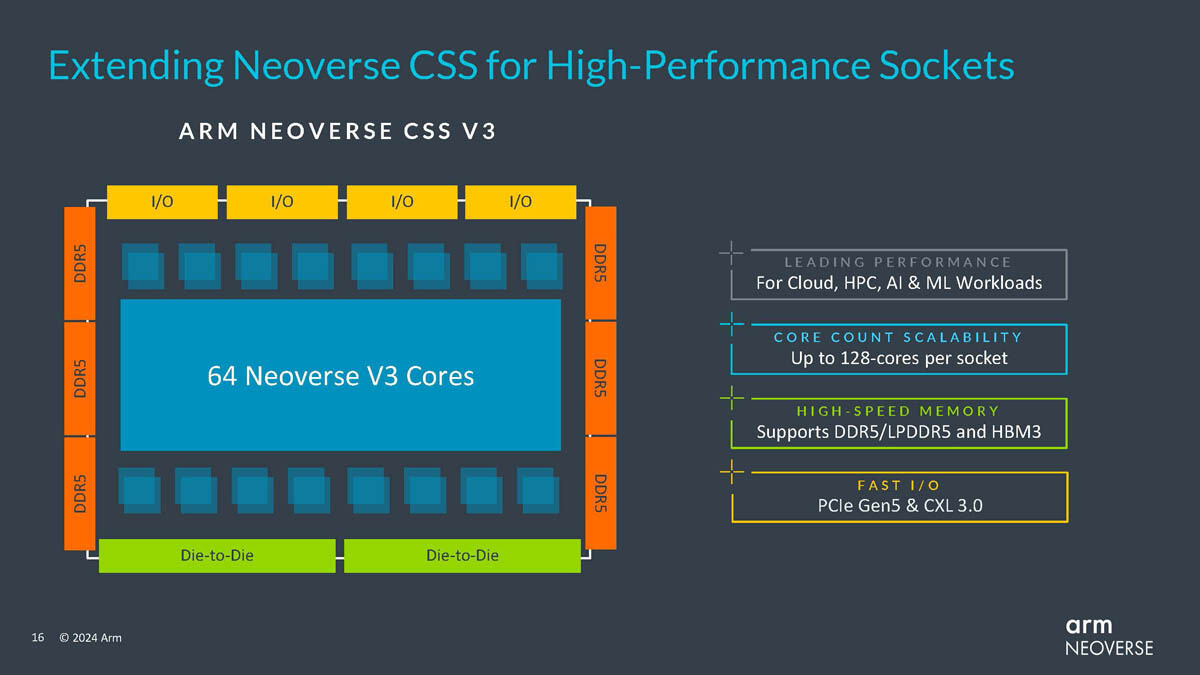
Arm Launches Next-Generation Neoverse CSS V3 and N3 Designs for Cloud, HPC, and AI Acceleration
Last year, Arm introduced its Neoverse Compute Subsystem (CSS) for the N2 and V2 series of data center processors, providing a reference platform for the development of efficient Arm-based chips. Major cloud service providers like AWS with Graviton 4 and Trainuium 2, Microsoft with Cobalt 100 and Maia 100, and even NVIDIA with Grace CPU and Bluefield DPUs are already utilizing custom Arm server CPU and accelerator designs based on the CSS foundation in their data centers. The CSS allows hyperscalers to optimize Arm processor designs specifically for their workloads, focusing on efficiency rather than outright performance. Today, Arm has unveiled the next generation CSS N3 and V3 for even greater efficiency and AI inferencing capabilities. The N3 design provides up to 32 high-efficiency cores per die with improved branch prediction and larger caches to boost AI performance by 196%, while the V3 design scales up to 64 cores and is 50% faster overall than previous generations.
Both the N3 and V3 leverage advanced features like DDR5, PCIe 5.0, CXL 3.0, and chiplet architecture, continuing Arm's push to make chiplets the standard for data center and cloud architectures. The chiplet approach enables customers to connect their own accelerators and other chiplets to the Arm cores via UCIe interfaces, reducing costs and time-to-market. Looking ahead, Arm has a clear roadmap for its Neoverse platform. The upcoming CSS V4 "Adonis" and N4 "Dionysus" designs will build on the improvements in the N3 and V3, advancing Arm's goal of greater efficiency and performance using optimized chiplet architectures. As more major data center operators introduce custom Arm-based designs, the Neoverse CSS aims to provide a flexible, efficient foundation to power the next generation of cloud computing.


Both the N3 and V3 leverage advanced features like DDR5, PCIe 5.0, CXL 3.0, and chiplet architecture, continuing Arm's push to make chiplets the standard for data center and cloud architectures. The chiplet approach enables customers to connect their own accelerators and other chiplets to the Arm cores via UCIe interfaces, reducing costs and time-to-market. Looking ahead, Arm has a clear roadmap for its Neoverse platform. The upcoming CSS V4 "Adonis" and N4 "Dionysus" designs will build on the improvements in the N3 and V3, advancing Arm's goal of greater efficiency and performance using optimized chiplet architectures. As more major data center operators introduce custom Arm-based designs, the Neoverse CSS aims to provide a flexible, efficient foundation to power the next generation of cloud computing.



Intel Foundry Services Get 18A Order: Arm-based 64-Core Neoverse SoC
Faraday Technology Corporation, a Taiwanese silicon IP designer, has announced plans to develop a new 64-core system-on-chip (SoC) utilizing Intel's most advanced 18A process technology. The Arm-based SoC will integrate Arm Neoverse compute subsystems (CSS) to deliver high performance and efficiency for data centers, infrastructure edge, and 5G networks. This collaboration brings together Faraday, Arm, and Intel Foundry Services. Faraday will leverage its ASIC design and IP solutions expertise to build the SoC. Arm will provide the Neoverse compute subsystem IP to enable scalable computing. Intel Foundry Services will manufacture the chip using its cutting-edge 18A process, which delivers one of the best-in-class transistor performance.
The new 64-core SoC will be a key component of Faraday's upcoming SoC evaluation platform. This platform aims to accelerate customer development of data center servers, high-performance computing ASICs, and custom SoCs. The platform will also incorporate interface IPs from the Arm Total Design ecosystem for complete implementation and verification. Both Arm and Intel Foundry Services expressed excitement about working with Faraday on this advanced Arm-based custom silicon project. "We're thrilled to see industry leaders like Faraday and Intel on the cutting edge of Arm-based custom silicon development," said an Arm spokesperson. Intel SVP Stuart Pann said, "We are pleased to work with Faraday in the development of the SoC based on Arm Neoverse CSS utilizing our most competitive Intel 18A process technology." The collaboration represents Faraday's strategic focus on leading-edge technologies to meet evolving application requirements. With its extensive silicon IP portfolio and design capabilities, Faraday wants to deliver innovative solutions and break into next-generation computing design.
The new 64-core SoC will be a key component of Faraday's upcoming SoC evaluation platform. This platform aims to accelerate customer development of data center servers, high-performance computing ASICs, and custom SoCs. The platform will also incorporate interface IPs from the Arm Total Design ecosystem for complete implementation and verification. Both Arm and Intel Foundry Services expressed excitement about working with Faraday on this advanced Arm-based custom silicon project. "We're thrilled to see industry leaders like Faraday and Intel on the cutting edge of Arm-based custom silicon development," said an Arm spokesperson. Intel SVP Stuart Pann said, "We are pleased to work with Faraday in the development of the SoC based on Arm Neoverse CSS utilizing our most competitive Intel 18A process technology." The collaboration represents Faraday's strategic focus on leading-edge technologies to meet evolving application requirements. With its extensive silicon IP portfolio and design capabilities, Faraday wants to deliver innovative solutions and break into next-generation computing design.


Microsoft Introduces 128-Core Arm CPU for Cloud and Custom AI Accelerator
During its Ignite conference, Microsoft introduced a duo of custom-designed silicon made to accelerate AI and excel in cloud workloads. First of the two is Microsoft's Azure Cobalt 100 CPU, a 128-core design that features a 64-bit Armv9 instruction set, implemented in a cloud-native design that is set to become a part of Microsoft's offerings. While there aren't many details regarding the configuration, the company claims that the performance target is up to 40% when compared to the current generation of Arm servers running on Azure cloud. The SoC has used Arm's Neoverse CSS platform customized for Microsoft, with presumably Arm Neoverse N2 cores.
The next and hottest topic in the server space is AI acceleration, which is needed for running today's large language models. Microsoft hosts OpenAI's ChatGPT, Microsoft's Copilot, and many other AI services. To help make them run as fast as possible, Microsoft's project Athena now has the name of Maia 100 AI accelerator, which is manufactured on TSMC's 5 nm process. It features 105 billion transistors and supports various MX data formats, even those smaller than 8-bit bit, for maximum performance. Currently tested on GPT 3.5 Turbo, we have yet to see performance figures and comparisons with competing hardware from NVIDIA, like H100/H200 and AMD, with MI300X. The Maia 100 has an aggregate bandwidth of 4.8 Terabits per accelerator, which uses a custom Ethernet-based networking protocol for scaling. These chips are expected to appear in Microsoft data centers early next year, and we hope to get some performance numbers soon.



The next and hottest topic in the server space is AI acceleration, which is needed for running today's large language models. Microsoft hosts OpenAI's ChatGPT, Microsoft's Copilot, and many other AI services. To help make them run as fast as possible, Microsoft's project Athena now has the name of Maia 100 AI accelerator, which is manufactured on TSMC's 5 nm process. It features 105 billion transistors and supports various MX data formats, even those smaller than 8-bit bit, for maximum performance. Currently tested on GPT 3.5 Turbo, we have yet to see performance figures and comparisons with competing hardware from NVIDIA, like H100/H200 and AMD, with MI300X. The Maia 100 has an aggregate bandwidth of 4.8 Terabits per accelerator, which uses a custom Ethernet-based networking protocol for scaling. These chips are expected to appear in Microsoft data centers early next year, and we hope to get some performance numbers soon.





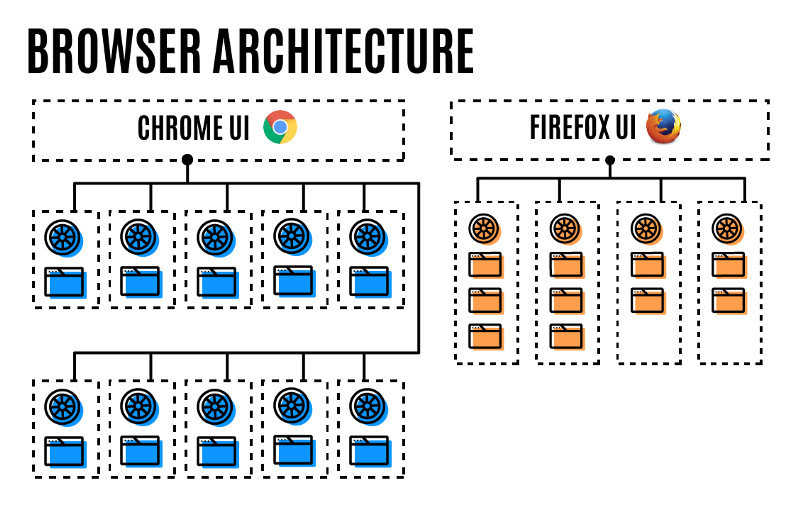
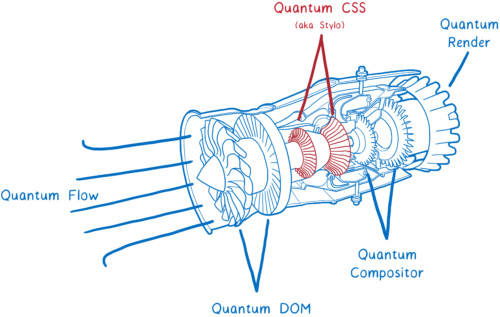
Mozilla Looks to Supercharge the Browsing Experience With Firefox Quantum
Mozilla is announcing that the latest version of its Firefox browser, Firefox 57, is just too good for just another numbered release. The improvements under the hood are so great, they say, and the performance improvements over previous Firefox releases are so grand, that only one name would have been enough to convey this message. That's why the latest Firefox release has been christened "Firefox Quantum".
Mozilla are saying their new Firefox Quantum browser delivers 2x the score in Speedometer as their previous Firefox 56. The new, refined browser didn't appear overnight, though; it's seen numerous improvements under the hood through the application of the Goldilocks principle to browser design, straddling an approach between increased performance and acceptable memory usage. Multi-process and optimized memory footprint are part of the secret sauce, but a new, super-charged CSS engine written in Rust goes a long way. Prioritization of the open tab also helps this increased speed, while (Mozilla says) reducing memory utilization by 30% when compared to Chrome.
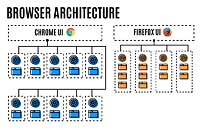
Mozilla are saying their new Firefox Quantum browser delivers 2x the score in Speedometer as their previous Firefox 56. The new, refined browser didn't appear overnight, though; it's seen numerous improvements under the hood through the application of the Goldilocks principle to browser design, straddling an approach between increased performance and acceptable memory usage. Multi-process and optimized memory footprint are part of the secret sauce, but a new, super-charged CSS engine written in Rust goes a long way. Prioritization of the open tab also helps this increased speed, while (Mozilla says) reducing memory utilization by 30% when compared to Chrome.


Apr 16th, 2025 09:08 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Windows 11 fresh install to do list (22)
- 5070ti overclock...what are your settings? (4)
- Last game you purchased? (771)
- GPU Memory Temprature is always high (16)
- Help For XFX RX 590 GME Chinese - Vbios (4)
- PCGH: "hidden site" to see total money spend on steam (3)
- Share your AIDA 64 cache and memory benchmark here (3053)
- NVFlash for RTX 50 Series (Blackwell) (0)
- intel 1700 with high speed ram,memory (63)
- The TPU UK Clubhouse (26115)
Popular Reviews
- G.SKILL Trident Z5 NEO RGB DDR5-6000 32 GB CL26 Review - AMD EXPO
- ASUS GeForce RTX 5080 TUF OC Review
- DAREU A950 Wing Review
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Thermaltake TR100 Review
- Zotac GeForce RTX 5070 Ti Amp Extreme Review
- TerraMaster F8 SSD Plus Review - Compact and quiet
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (124)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (85)
- NVIDIA PhysX and Flow Made Fully Open-Source (77)
- NVIDIA Pushes GeForce RTX 5060 Ti Launch to Mid-April, RTX 5060 to May (77)