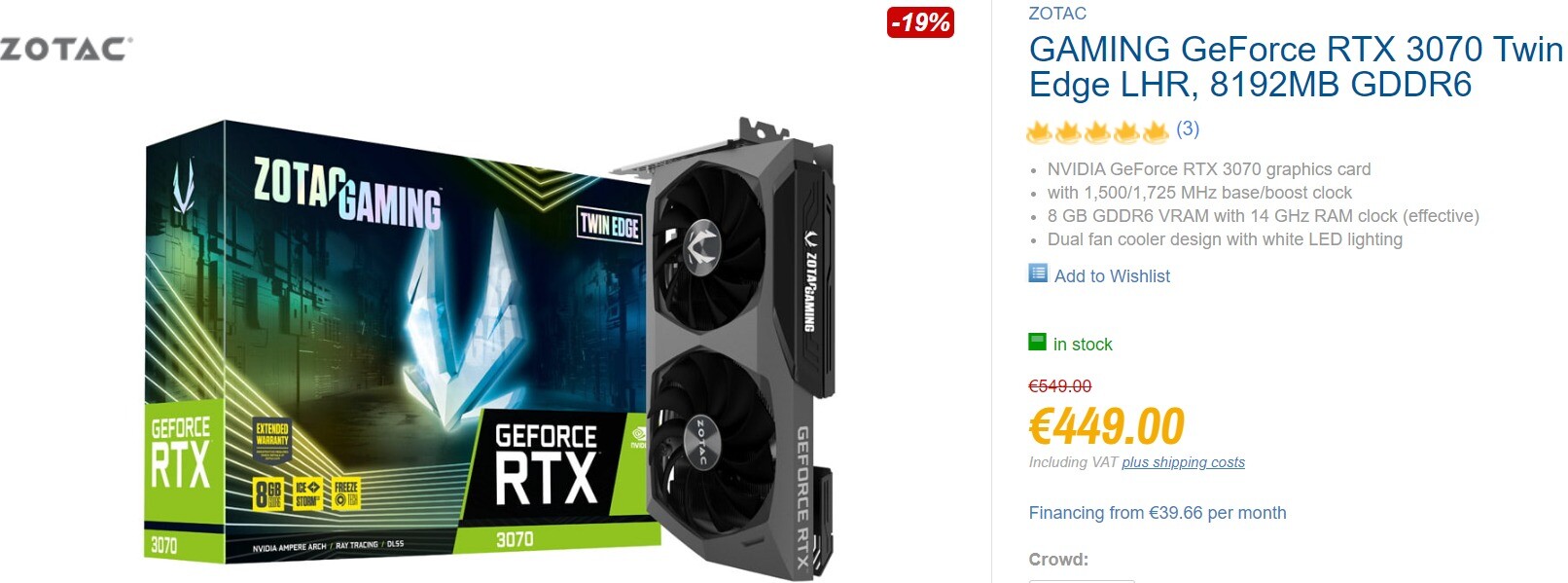
NVIDIA GeForce RTX 3070 GPU Available for Below MSRP in Germany
Two years and a half into its storied career, the NVIDIA GeForce RTX 3070 GPU has finally dropped below MSRP in one European territory. German customers will be stoked to jump on e-tailer CaseKing's new offer - ZOTAC's Gaming GeForce RTX 3070 Twin Edge LHR graphics card is currently available for 449 EUR (not counting additional fees), so a saving of 50 Euros from the recommended retail price (499 EUR/$499). 3DCenter seems to be the first hardware news outlet to report on an RTX 3070 GPU dropping under RRP. The RTX 3070 and 3060 Ti models have been best sellers for NVIDIA (and board partners) since late 2020, yet buyers have long complained about unreasonable asking prices, and semi-generous discounts have been very late in arriving - just in time for the succeeding model.
3DCenter has created an overview of the graphics card market in Germany and Austria, and its findings for May 2023 indicate a trend where: "GPU prices in Euros have consistently dropped by ~10% since the end of January, in single cases up to 20%." The overview places the RTX 3070 8 GB in a price bracket position between AMD's Radeon RX 6750XT 12 GB and RX 6800 16 GB (non-XT) SKUs, which brings recent marketing strategies to mind - Team Red thinks that their cards offer the buyer more VRAM for their money when cross examined with the competition.

3DCenter has created an overview of the graphics card market in Germany and Austria, and its findings for May 2023 indicate a trend where: "GPU prices in Euros have consistently dropped by ~10% since the end of January, in single cases up to 20%." The overview places the RTX 3070 8 GB in a price bracket position between AMD's Radeon RX 6750XT 12 GB and RX 6800 16 GB (non-XT) SKUs, which brings recent marketing strategies to mind - Team Red thinks that their cards offer the buyer more VRAM for their money when cross examined with the competition.