 223
223
AMD Radeon Vega GPU Architecture
Conclusion »Next Generation Geometry, Compute, and Pixel Engine
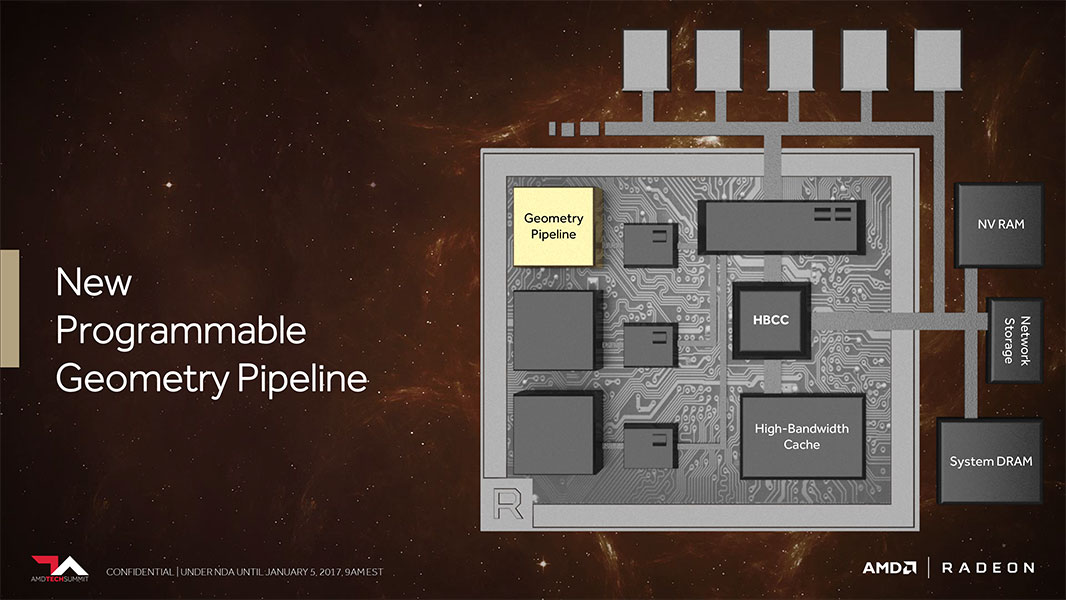



AMD improved the geometry processing machinery available to previous generations with "Vega." The new generation programmable geometry pipeline has over two times the peak throughput per clock. Vega now supports primitive shaders, besides the contemporary vertex and geometry shaders. AMD has also improved the way it distributes workloads between the geometry, compute, and pixel engines. A primitive shader is a new type of low-level shader that gives the developer more freedom to specify all the shading stages they want to use, and run those at a higher rate because they are now decoupled from the traditional DirectX shader pipeline model. While ideally the developer would perform that optimization, AMD also has the ability to use their graphics driver to predefine cases for a game, in which a number of DirectX shaders can be replaced by a single primitive shader for improved performance.
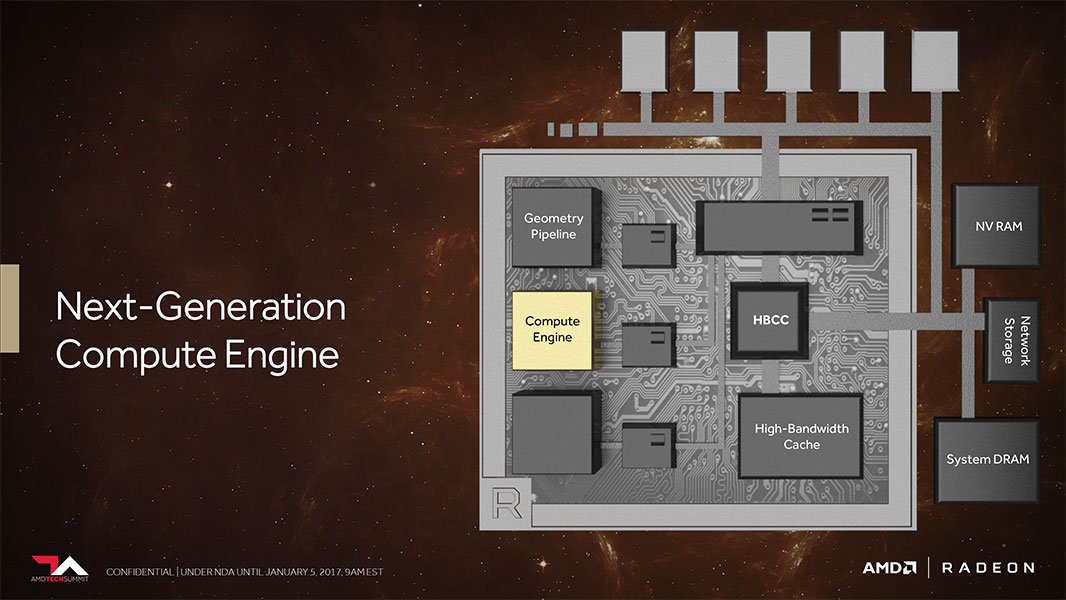

The compute unit (CU) is the basic, heavily parallelized number-crunching machinery of the GPU. With "Vega," AMD improved the functionality of the CUs, which it now calls NCUs (next-generation compute units), by adding support for super-simple 8-bit ops, in addition to the 16-bit ops (FP16) introduced with "Polaris" and the conventional single- and double-precision floating point ops support on older generations. Support for 8-bit ops lets game developers simplify their code, so if it falls within the memory footprint of the 8-bit address space, 512 of them can be crunched per clock cycle.


AMD also introduced a new feature called "Rapid Packed Math" in which it clumps multiple 16-bit operations between 32-bit registers for more simple work done per clock. Thanks to these improvements, the Vega NCU is able to crunch four times the operations per clock cycle as the previous generation, as well as run at double the clock speed. AMD has carried over its memory bandwidth-saving lossless compression algorithms. Lastly, AMD improved the pixel-engine with a new-generation draw-stream binning rasterizer. This conserves clock cycles, which helps with on-die cache locality and memory footprint.
AMD changed the hierarchy of the GPU in a way that improves performance of apps that use deferred shading. The geometry pipeline, the compute engine, and and the pixel engine, which output to the ROPs (L1 caches), are now tied to the L2 cache. Earlier, the pixel and texture engines had non-coherent memory access in which the pixel engine wrote to the memory controller.
Mar 13th, 2025 17:02 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Free Games Thread (4560)
- And so... I bought Arrow Lake (13700k to 265k), my thoughts. (39)
- Attempting to enable Resizable BAR with RTX 3070 (26)
- What are you playing? (23138)
- intel 1700 with high speed ram,memory (53)
- I'm looking for a good tool to make the 3D scanning of my mini-pc using the photogrammetry and my Kinect 2. (100)
- Problem flashing VBIOS to RX 5700 - Failed to erase SPIROM (0)
- my GTX 960 msi Gaming 4GB is stuck at 135mhz (0)
- What motherboard with spdif should I get? PC to 5.1 blu-ray player via optical (18)
- Chilled water + Full-cover GPU Blocks? (3)
Popular Reviews
- AMD Ryzen 9 9950X3D Review - Great for Gaming and Productivity
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- XFX Radeon RX 9070 XT Mercury OC Magnetic Air Review
- FSP MP7 Black Review
- Dough Spectrum Black 32 Review
- ASUS Radeon RX 9070 TUF OC Review
- ASUS GeForce RTX 5090 TUF Review
- Gigabyte X870E Aorus Pro Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- NVIDIA GeForce RTX 5070 Founders Edition Review
Controversial News Posts
- NVIDIA GeForce RTX 50 Cards Spotted with Missing ROPs, NVIDIA Confirms the Issue, Multiple Vendors Affected (513)
- AMD Radeon RX 9070 and 9070 XT Listed On Amazon - One Buyer Snags a Unit (261)
- AMD RDNA 4 and Radeon RX 9070 Series Unveiled: $549 & $599 (260)
- AMD Mentions Sub-$700 Pricing for Radeon RX 9070 GPU Series, Looks Like NV Minus $50 Again (249)
- NVIDIA Investigates GeForce RTX 50 Series "Blackwell" Black Screen and BSOD Issues (244)
- AMD Radeon RX 9070 and 9070 XT Official Performance Metrics Leaked, +42% 4K Performance Over Radeon RX 7900 GRE (195)
- AMD Radeon RX 9070-series Pricing Leaks Courtesy of MicroCenter (158)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (104)