Thursday, August 30th 2012

Intel Reveals Architecture Details of Intel Xeon Phi Co-Processor
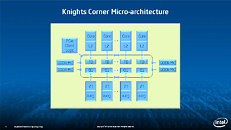
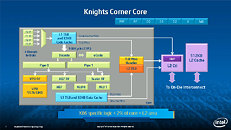
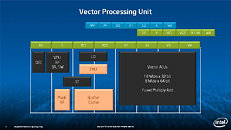
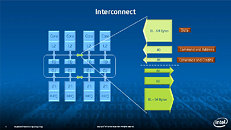
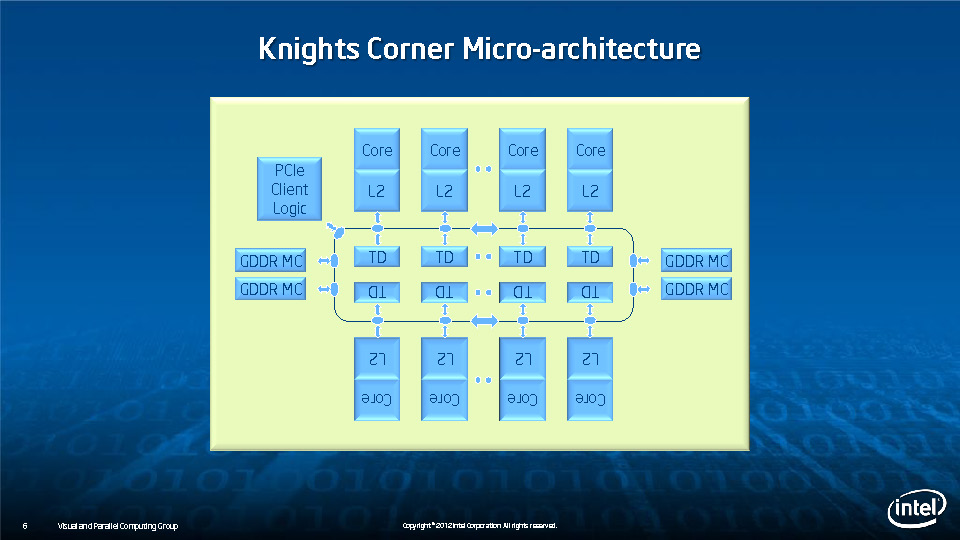
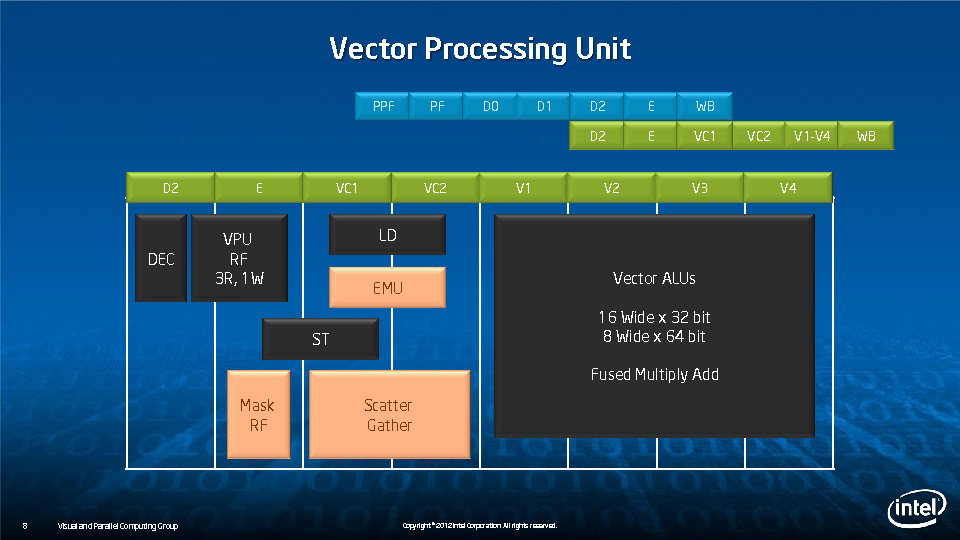
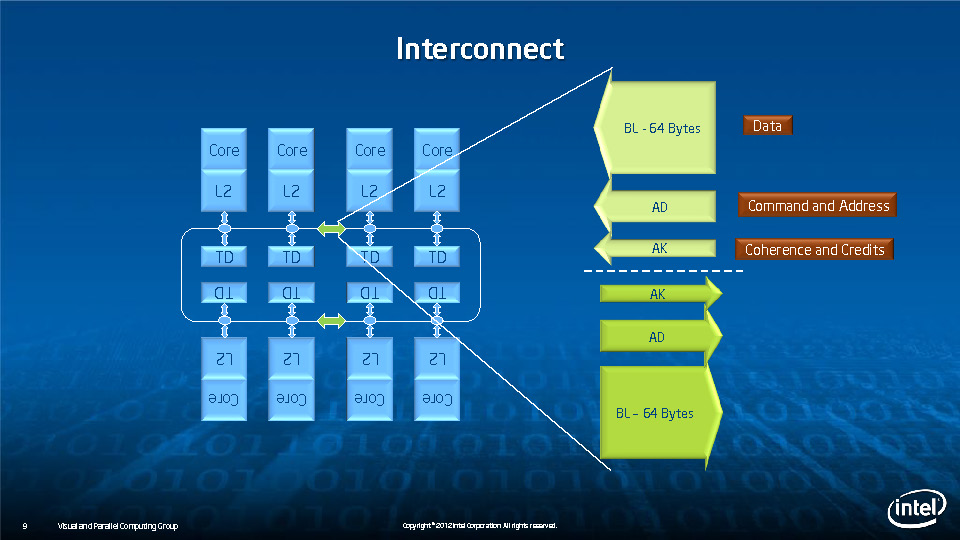
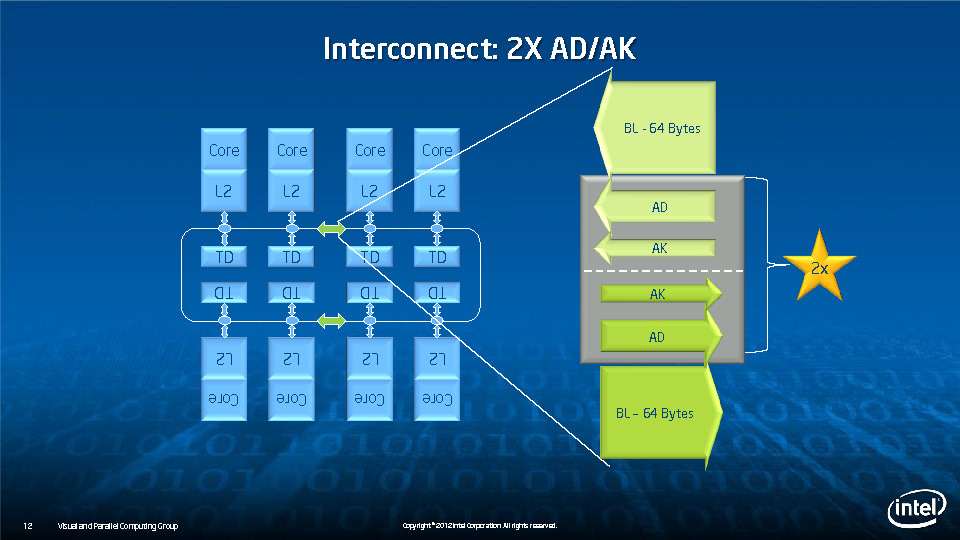
During HotChips symposium, George Chrysos, the leading architect of Intel Xeon Phi co-processor shared the new architecture details of upcoming Intel's HPC powerhouse. Designed for highly-parallel applications, Intel Xeon Phi co-processor based on Intel Mani Integrated Core architecture will deliver the combination of industry leading performance per watt with the ability to re-use the existing code and applications without necessity of re-writing them.
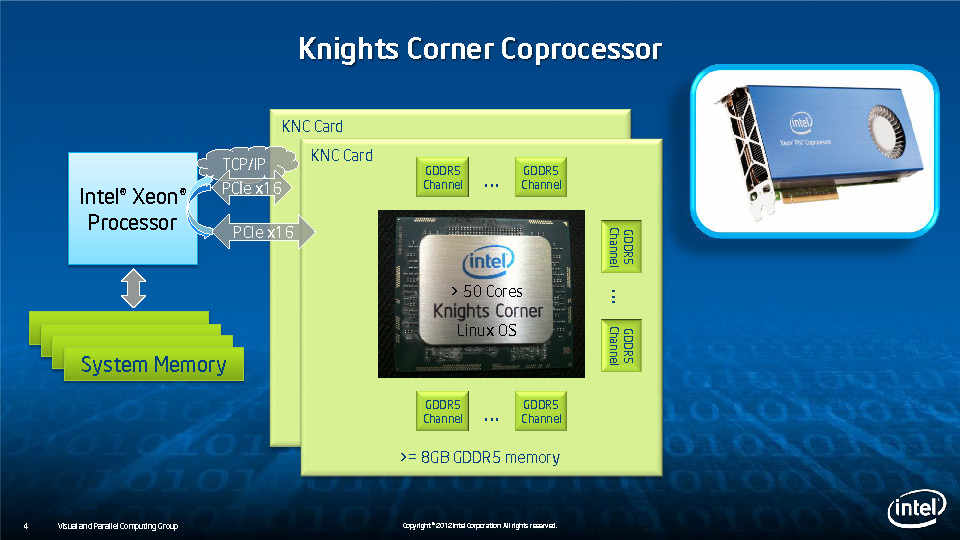
Equipped with more than 50 cores and built using Intel's latest 22nm 3D Tri-gate transistor technology, new co-processors will be in production this year with first supercomputers from top500 list already taking advantage of this technology. In his blog here, George shares his aspirations and goals during designing the co-processor and summarizes all new disclosed information. The HotChips presentation is also available below.





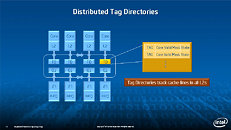
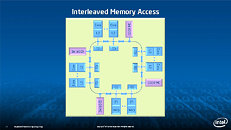
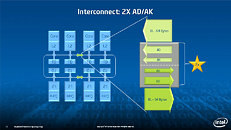
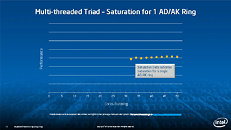
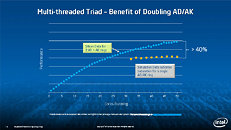

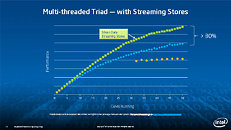

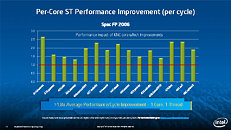
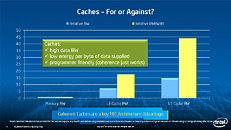

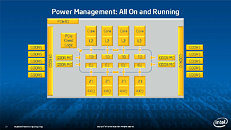
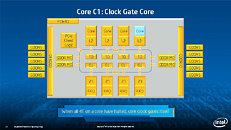
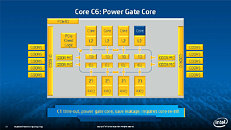
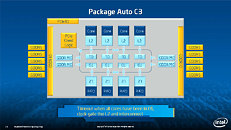
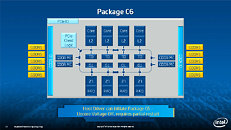



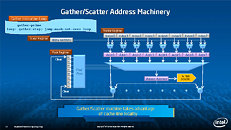
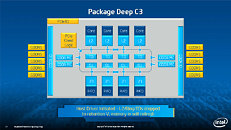
Equipped with more than 50 cores and built using Intel's latest 22nm 3D Tri-gate transistor technology, new co-processors will be in production this year with first supercomputers from top500 list already taking advantage of this technology. In his blog here, George shares his aspirations and goals during designing the co-processor and summarizes all new disclosed information. The HotChips presentation is also available below.






















24 Comments on Intel Reveals Architecture Details of Intel Xeon Phi Co-Processor
In fact, they are probably behind. That chart (slide 5) with 1381 vs. 1380 was finagled for the boss so that the team didn't lose their jobs!
.
.
.
Nobody has (yet) complained about PCB color (slide 4).Well, he is encoding it. Perhaps he's a home cinematics aficionado?
In scientific applications, double precision is yearned for. The only reason why everything isn't double precision is because, until recently, graphics cards either didn't support double precision or took a huge performance penalty if they did double precision. These cards are going to end up in multi-million dollar science-conducting machines. Double precision performance is going to be a huge selling point for these cards.
Basically it's a 50 Pentium Pro cluster in an add-on card. Can't wait for some of these to appear in retail... in a couple of years. :banghead:
Three or four of these new Phi's could do it, and in a couple years it'll only take one.
Their X86 interface is the same idea behind AMD's "Fabric", one interface that handles the requests and issues them to the faster or least busy of the CPU cores, or GPU "shaders".
Larrabee, plus all the IP that AMD handed over a couple years ago to Intel as part of the monopoly payment/trade.