Thursday, March 21st 2019

Intel "Ice Lake" GPU Docs Reveal Unganged Memory Mode
When reading through the Gen11 GT2 whitepaper by Intel, which describes their upcoming integrated graphics architecture, we may have found a groundbreaking piece of information that concerns the memory architecture of computers running 10 nm "Ice Lake" processors. The whitepaper mentions the chip to feature a 4x32-bit LPDDR4/DDR4 interface as opposed to the 2x64-bit LPDDR4/DDR4 interface of current-generation chips such as "Coffee Lake." This is strong evidence that Intel's new architecture will have unganged dual-channel memory controllers (2x 64-bit), as opposed to the monolithic 128-bit IMC found on current-generation chips.
An unganged dual-channel memory interface consists of two independent memory controllers, each handling a 64-bit wide memory channel. This approach lets the processor execute two operations in tandem, given the accesses go to distinct memory banks. On top of that it's now possible to read and write at the same time, something that's can't be done in 128-bit memory mode. From a processor's perspective DRAM is very slow, and what takes up most of the time (= latency), is opening the memory and preparing the read/write operation - the actual data transfer is fairly quick.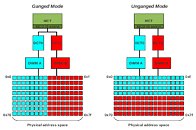
 With two independent memory controllers these latencies can be mitigated, in several ways in unganged mode. While single-threaded workloads, or workloads that operate on a relatively small problem set, benefit more from ganged mode, unganged mode can shine when multiple (or multi-threaded) applications work with vast amounts of memory, which increases the likelihood that two independent banks of memory get accessed. Perhaps unganged-aware software, such as OS-level memory management could help make the most out of unganged mode, by trying to spread out processes evenly throughout the physical memory, so independent memory accesses can be executed as often as possible.
With two independent memory controllers these latencies can be mitigated, in several ways in unganged mode. While single-threaded workloads, or workloads that operate on a relatively small problem set, benefit more from ganged mode, unganged mode can shine when multiple (or multi-threaded) applications work with vast amounts of memory, which increases the likelihood that two independent banks of memory get accessed. Perhaps unganged-aware software, such as OS-level memory management could help make the most out of unganged mode, by trying to spread out processes evenly throughout the physical memory, so independent memory accesses can be executed as often as possible.
For integrated graphics, unganged mode is a real killer application though. The iGPU reserves a chunk of system memory for geometry, textures and framebuffer. This memory range is typically placed at the end of the physical memory space, whereas the Windows OS and applications usually are located near the start of physical memory. This effectively gives the GPU its own dedicated memory controller, which also reduces memory latency, because one controller can hold the IGP's memory pages open almost all the time, whereas the second controller takes care of the OS and application memory requests.
AMD has been supporting unganged dual-channel memory interfaces for over a decade now. The company's first Phenom processors introduced unganged memory with a BIOS option to force the CPU to interleave all data, called ganged mode. The consensus among the tech-community over the past ten years and the evolution of the modern processor toward more parallelism favors unganged mode. With CPU core counts heading north of 8 for mainstream-desktop processors, and integrated GPUs becoming the norm, it was natural for Intel to add support for an unganged memory interface.Image Courtesy: ilsistemista.net
An unganged dual-channel memory interface consists of two independent memory controllers, each handling a 64-bit wide memory channel. This approach lets the processor execute two operations in tandem, given the accesses go to distinct memory banks. On top of that it's now possible to read and write at the same time, something that's can't be done in 128-bit memory mode. From a processor's perspective DRAM is very slow, and what takes up most of the time (= latency), is opening the memory and preparing the read/write operation - the actual data transfer is fairly quick.


For integrated graphics, unganged mode is a real killer application though. The iGPU reserves a chunk of system memory for geometry, textures and framebuffer. This memory range is typically placed at the end of the physical memory space, whereas the Windows OS and applications usually are located near the start of physical memory. This effectively gives the GPU its own dedicated memory controller, which also reduces memory latency, because one controller can hold the IGP's memory pages open almost all the time, whereas the second controller takes care of the OS and application memory requests.
AMD has been supporting unganged dual-channel memory interfaces for over a decade now. The company's first Phenom processors introduced unganged memory with a BIOS option to force the CPU to interleave all data, called ganged mode. The consensus among the tech-community over the past ten years and the evolution of the modern processor toward more parallelism favors unganged mode. With CPU core counts heading north of 8 for mainstream-desktop processors, and integrated GPUs becoming the norm, it was natural for Intel to add support for an unganged memory interface.Image Courtesy: ilsistemista.net
15 Comments on Intel "Ice Lake" GPU Docs Reveal Unganged Memory Mode
seems they try to improve the perf. this way also; if i read between lines .... they're aware of having perf. issues vs amd.... "Houston, we have a problem"
AMD for reference:
Only cache misses have to be read from or written to memory.
I don't see as being a huge performance factor.
They need a lot of bandwidth which is rather scarce on the current DDR4 platform, AMD faces the same problem.
Anyone can steal someones entire IP and manufacture the design.
To figure out how it works, iterate on the design and compete... that is innovation.Yeah, the 2200g can keep pace with the 2400g when clocked the same despite the ~40% increase in sp, definitely memory starved.