Monday, May 23rd 2022

AMD Unveils 5 nm Ryzen 7000 "Zen 4" Desktop Processors & AM5 DDR5 Platform
AMD today unveiled its next-generation Ryzen 7000 desktop processors, based on the Socket AM5 desktop platform. The new Ryzen 7000 series processors introduce the new "Zen 4" microarchitecture, with the company claiming a 15% single-threaded uplift over "Zen 3" (16-core/32-thread Zen 4 processor prototype compared to a Ryzen 9 5950X). Other key specs about the architecture put out by AMD include a doubling in per-core L2 cache to 1 MB, up from 512 KB on all older versions of "Zen." The Ryzen 7000 desktop CPUs will boost to frequencies above 5.5 GHz. Based on the way AMD has worded their claims, it seems that the "+15%" number includes IPC gains, plus gains from higher clocks, plus what the DDR4 to DDR5 transition achieves. With Zen 4, AMD is introducing a new instruction set for AI compute acceleration. The transition to the LGA1718 Socket AM5 allows AMD to use next-generation I/O, including DDR5 memory, and PCI-Express Gen 5, both for the graphics card, and the M.2 NVMe slot attached to the CPU socket.
Much like Ryzen 3000 "Matisse," and Ryzen 5000 "Vermeer," the Ryzen 7000 "Raphael" desktop processor is a multi-chip module with up to two "Zen 4" CCDs (CPU core dies), and one I/O controller die. The CCDs are built on the 5 nm silicon fabrication process, while the I/O die is built on the 6 nm process, a significant upgrade from previous-generation I/O dies that were built on 12 nm. The leap to 5 nm for the CCD enables AMD to cram up to 16 "Zen 4" cores per socket, all of which are "performance" cores. The "Zen 4" CPU core is larger, on account of more number-crunching machinery to achieve the IPC increase and new instruction-sets, as well as the larger per-core L2 cache. The cIOD packs a pleasant surprise—an iGPU based on the RDNA2 graphics architecture! Now most Ryzen 7000 processors will pack integrated graphics, just like Intel Core desktop processors.




 The Socket AM5 platform is capable of up to 24 PCI-Express 5.0 lanes from the processor. 16 of these are meant for the PCI-Express graphics slots (PEG), while four of these go toward an M.2 NVMe slot attached to the CPU—if you recall, Intel "Alder Lake" processors have 16 Gen 5 lanes toward PEG, but the CPU-attached NVMe slot runs at Gen 4. The processor features dual-channel DDR5 (four sub-channel) memory, identical to "Alder Lake," but with no DDR4 memory support. Unlike Intel, the AM5 Socket retains cooler compatibility with AM4, so the cooler you have sitting on your Ryzen CPU right now, will work perfectly fine.
The Socket AM5 platform is capable of up to 24 PCI-Express 5.0 lanes from the processor. 16 of these are meant for the PCI-Express graphics slots (PEG), while four of these go toward an M.2 NVMe slot attached to the CPU—if you recall, Intel "Alder Lake" processors have 16 Gen 5 lanes toward PEG, but the CPU-attached NVMe slot runs at Gen 4. The processor features dual-channel DDR5 (four sub-channel) memory, identical to "Alder Lake," but with no DDR4 memory support. Unlike Intel, the AM5 Socket retains cooler compatibility with AM4, so the cooler you have sitting on your Ryzen CPU right now, will work perfectly fine.


The platform also puts out up to 14 USB 20 Gbps ports, including type-C. With onboard graphics now making it to most processor models, motherboards will feature up to four DisplayPort 2 or HDMI 2.1 ports. The company will also standardize Wi-Fi 6E + Bluetooth WLAN solutions it co-developed with MediaTek, weaning motherboard designers away from Intel-made WLAN solutions.
At its launch, in Fall 2022, AMD's AM5 platform will come with three motherboard chipset options—the AMD X670 Extreme (X670E), the AMD X670, and the AMD B650. The X670 Extreme was probably made by re-purposing the new-generation 6 nm cIOD die to work as a motherboard chipset, which means its 24 PCIe Gen 5 lanes work toward building an "all Gen 5" motherboard platform. The X670 (non-extreme), is very likely a rebadged X570, which means you get up to 20 Gen 4 PCIe lanes from the chipset, while retaining PCIe Gen 5 PEG and CPU-attached NVMe connectivity. The B650 chipset is designed to offer Gen 4 PCIe PEG, Gen 5 CPU-attached NVMe, and likely Gen 3 connectivity from the chipset.
 AMD is betting big on next-generation M.2 NVMe SSDs with PCI-Express Gen 5, and is gunning to be the first desktop platform with PCIe Gen 5-based M.2 slots. The company is said to be working with Phison to optimize the first round of Gen 5 SSDs for the platform.
AMD is betting big on next-generation M.2 NVMe SSDs with PCI-Express Gen 5, and is gunning to be the first desktop platform with PCIe Gen 5-based M.2 slots. The company is said to be working with Phison to optimize the first round of Gen 5 SSDs for the platform. All major motherboard vendors are ready with Socket AM5 motherboards. AMD showcased a handful, including the ASUS ROG Crosshair X670E Extreme, the ASRock X670E Taichi, MSI MEG X670E ACE, GIGABYTE X670E AORUS Xtreme, and the BIOSTAR X670E Valkyrie.
All major motherboard vendors are ready with Socket AM5 motherboards. AMD showcased a handful, including the ASUS ROG Crosshair X670E Extreme, the ASRock X670E Taichi, MSI MEG X670E ACE, GIGABYTE X670E AORUS Xtreme, and the BIOSTAR X670E Valkyrie.
AMD is working to introduce several platform-level innovations like it did with Smart Access Memory with its Radeon RX 6000 series, which builds on top of the PCIe Resizable BAR technology by the PCI-SIG. The new AMD Smart Access Storage technology builds on Microsoft DirectStorage, by adding AMD platform-awareness, and optimization for AMD CPU and GPU architectures. DirectStorage enables direct transfers between a storage device and the GPU memory, without the data having to route through the CPU cores. In terms of power delivery Zen 4 uses the same SVI3 voltage control interface that we saw introduced on the Ryzen Mobile 6000 Series. For desktop this means the ability to address a higher number of VRM phases and to process voltage changes much faster than with SVI2 on AM4. Taking a closer look at the AMD Footnotes, "RPL-001", we find out that the "15% IPC gain" figure is measured using Cinebench and compares a Ryzen 9 5950X processor (not 5800X3D), on a Socket AM4 platform with DDR4-3600 CL16 memory, to the new Zen 4 platform running at DDR5-6000 CL30 memory. If we go by the measurements from our Alder Lake DDR5 Performance Scaling article, then this memory difference alone will account for roughly 5% of the 15% gains.
Taking a closer look at the AMD Footnotes, "RPL-001", we find out that the "15% IPC gain" figure is measured using Cinebench and compares a Ryzen 9 5950X processor (not 5800X3D), on a Socket AM4 platform with DDR4-3600 CL16 memory, to the new Zen 4 platform running at DDR5-6000 CL30 memory. If we go by the measurements from our Alder Lake DDR5 Performance Scaling article, then this memory difference alone will account for roughly 5% of the 15% gains.


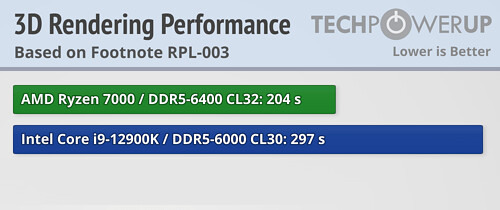
The footnotes also reference a "RPL-003" claim that's not used anywhere in our pre-briefing slide deck, but shown in the video presentation. In the presentation we're seeing a live demo comparison between a "Ryzen 7000 Series" processor and Intel's Core i9-12900K "Alder Lake." It's worth mentioning here that AMD isn't disclosing the exact processor model, only that it's a 16-core part, if we follow the Zen 3 naming, that would probably be the Ryzen 9 7950X flagship. The comparison runs the Blender rendering software, which loads all CPU cores. Here we see the Ryzen 7000 chip finish the task in 204 seconds, compared to the i9-12900K and its 297 seconds time, which is a huge 31% difference—very impressive. It's worth mentioning that the memory configurations are slightly mismatched. Intel is running with DDR5-6000 CL30, whereas the Ryzen is tested with DDR5-6400 CL32—lower latency for Intel, higher MHz for Ryzen. While ideally we'd like to see identical memory used, the differences due to the memory configuration should be very small.
 AMD is targeting a Fall 2022 launch for the Ryzen 7000 "Zen 4" desktop processor family, which would put this sometime between September thru October. The company is likely to detail the "Zen 4" microarchitecture and the Ryzen 7000 SKU list in the coming weeks.
AMD is targeting a Fall 2022 launch for the Ryzen 7000 "Zen 4" desktop processor family, which would put this sometime between September thru October. The company is likely to detail the "Zen 4" microarchitecture and the Ryzen 7000 SKU list in the coming weeks.
Update 21:00 UTC: AMD has clarified that the 170 W PPT power numbers seen are the absolute max limits, not "typical" like the 105 W, on Zen 3, which were often exceeded during heavy usage.
Update May 26th: AMD further clarified that the 170 W number is "TDP", not "PPT", which means that when the usual x1.35 factor is applied, actual power usage can go up to 230 W.
You can watch the whole presentation again at YouTube:
Much like Ryzen 3000 "Matisse," and Ryzen 5000 "Vermeer," the Ryzen 7000 "Raphael" desktop processor is a multi-chip module with up to two "Zen 4" CCDs (CPU core dies), and one I/O controller die. The CCDs are built on the 5 nm silicon fabrication process, while the I/O die is built on the 6 nm process, a significant upgrade from previous-generation I/O dies that were built on 12 nm. The leap to 5 nm for the CCD enables AMD to cram up to 16 "Zen 4" cores per socket, all of which are "performance" cores. The "Zen 4" CPU core is larger, on account of more number-crunching machinery to achieve the IPC increase and new instruction-sets, as well as the larger per-core L2 cache. The cIOD packs a pleasant surprise—an iGPU based on the RDNA2 graphics architecture! Now most Ryzen 7000 processors will pack integrated graphics, just like Intel Core desktop processors.









At its launch, in Fall 2022, AMD's AM5 platform will come with three motherboard chipset options—the AMD X670 Extreme (X670E), the AMD X670, and the AMD B650. The X670 Extreme was probably made by re-purposing the new-generation 6 nm cIOD die to work as a motherboard chipset, which means its 24 PCIe Gen 5 lanes work toward building an "all Gen 5" motherboard platform. The X670 (non-extreme), is very likely a rebadged X570, which means you get up to 20 Gen 4 PCIe lanes from the chipset, while retaining PCIe Gen 5 PEG and CPU-attached NVMe connectivity. The B650 chipset is designed to offer Gen 4 PCIe PEG, Gen 5 CPU-attached NVMe, and likely Gen 3 connectivity from the chipset.



AMD is working to introduce several platform-level innovations like it did with Smart Access Memory with its Radeon RX 6000 series, which builds on top of the PCIe Resizable BAR technology by the PCI-SIG. The new AMD Smart Access Storage technology builds on Microsoft DirectStorage, by adding AMD platform-awareness, and optimization for AMD CPU and GPU architectures. DirectStorage enables direct transfers between a storage device and the GPU memory, without the data having to route through the CPU cores. In terms of power delivery Zen 4 uses the same SVI3 voltage control interface that we saw introduced on the Ryzen Mobile 6000 Series. For desktop this means the ability to address a higher number of VRM phases and to process voltage changes much faster than with SVI2 on AM4.





Update 21:00 UTC: AMD has clarified that the 170 W PPT power numbers seen are the absolute max limits, not "typical" like the 105 W, on Zen 3, which were often exceeded during heavy usage.
Update May 26th: AMD further clarified that the 170 W number is "TDP", not "PPT", which means that when the usual x1.35 factor is applied, actual power usage can go up to 230 W.
You can watch the whole presentation again at YouTube:
211 Comments on AMD Unveils 5 nm Ryzen 7000 "Zen 4" Desktop Processors & AM5 DDR5 Platform
1) obtain the render scene program;
2) set up a similar 12900k with as close to as posiible memory type, size and timings;
3) run program with core affinity set for E-cores only;
4) go to bios and dissable E-cores or core affinity for P-cores only;
would solve it?
I might finally upgrade my i7 2600k processor either with RocketLake or Zen 4, whichever turns out to be better and be done for the next 10 years. :)
For example, 1 cpu is better than another in one application and the another cpu is better than the first one in a different application. If IPC is a metric describing instructions per second which are a constant, the outcome should be the same for every app but it is not. So performance does not always equal IPC.
For instance.
5800x and 5800x3d in games. Normally these are the same processors but they behave differently in gaming and differently in office apps. So out of curiosity, am I talking here about IPC or a performance? Somehow, you say that IPC has to be measured across variety of benchmarks to be valid. I thought that is general performance of a CPU across mostly used applications.
In that case how do you know 7950X is the flagship and not the lower one?
It could be 7950X and 7950XT!jk
An I5 can beat a I7 in laptop land.
Go see.
As for this 15% ST /30% MT and pciex 5 all round, sounds good can't wait for the competition.
I wouldn't be buying gen 1 straight away though.
I do like the Intel fanbois declaration of failure, without the adequate facts available or tests to validate there concerns.
Plus Rocket lake , could be late , Intel likes late these days, so much still to be resolved.
Completing a workload in 31% less time means the rate of work done is 45% higher.
faster / slower refers to a comparison of value / time (like Frames Per Second for example 145fps is 45% faster than 100fps). Now AMD did not use faster / slower in the slide they said it took 31% less time which is the correct wording because they are doing a seconds / workload comparison and the seconds for the Zen 4 rig was 31% less than the 12900K rig. (297 * 0.69)
If you want to use faster / slower you need to calculate the rate which is easy enough, just do 1/204 to get the renders / s which is 0.0049. Do the same for the 12900K and you get 1/297 which is 0.0034
0.0049 is a 45% faster rate than 0.0034. 0.0034 is 31% slower than 0.0049.
On a TPU graph of rate with 12900K at 100% Zen 4 would be 145%. If Zen 4 was at 100% the 12900K would be at 69%. In both cases 12900K * 1.45 = zen 4 (100*1.45 = 145 and 69*1.45 = 100)
If you don't want to use rate you need to avoid faster / slower wording and stick to less time / more time wording where you can say that Zen 4 took 31% less time or the 12900K took 45% more time. These are simple calculations though so re-arranging them is pretty trivial.
However, the number of instructions that a given CPU core executes in one clock cycle is most certainly NOT a constant. Rather, it varies in a very wide range.
For me it's the Fall announcement. that is quite late in my opinion and it should have been released in my opinion early summer. Fall make it very close to Raptor lake and AMD will have to truly deliver.
We still don't know what AMD have made and many assumed that AMD went the intel way and went wider cores. They may have not. Cinebench R23 is not really cache/memory sensitive so if they went to improve the cache bandwidth and latency + increased the size + reworked the memory subsystem, their gain wouldn't show up really in CB R23. But they will show up on many others applications.
We will see, a reworked and improved memory subsystem will improve multithread score and gaming.
But it's way too early to tell. I am not sure that AMD sandbag that much. I think they went to design a CPU that will rock where they have the highest margin. EPYC lineup. People say AMD is dead, but if AMD suck 1 gen or 2 on desktop while still destroying everything on server, the company will still thrive. They make so much more money on a chiplet in an EPYC cpu than in a Ryzen.
I will wait to see the review number but right now i am neutral on the product. Not really hype but not really disappointed
That is a huge departure from the era of finely crafted benchmark to show the new product in his best light. AMD sandbagged a bit Zen 3, but that much? i don't know.
AMD are keeping true performance close to their chest.
With nearly +10% frequency in 1T (and much more in nT with 170W), IPC would just be 5%, deduct 2-5% or whatever due to high memory that they used and we are talking zen->zen+ IPC difference which I refuse to believe.
For the sake of competition they better deliver, I just want the pricing to be competitive (with that I mean if in 1080p gaming 7800X/7600X is similar to 13700K/13600K in performance (+3% is similar imo) while they lose with much higher margins in multithreading tests like Cinebench, V-ray, transcoding etc, they better be cheaper than Raptor Lake...)
So probably RDNA2 based?
But on 6nm it wouldn't be insignificant die size addition because it doesn't matter if it's just 4 CU, all the unslice (ACEs, HWS etc)+media engine+display engine+ etc is a lot of space.
I'm curious to see if it's only 256SP how much faster it would be vs Raptor Lake at 1080p (if Raptor Lake is 256EU, isn't time to upgrade the damn thing, since it isn't going to be ARC based at least Intel should made it a 1.6GHz 384EU design, since with DDR4 we had 1.3GHz 256EU design with 14nm Rocket Lake)