Friday, April 5th 2024

AMD Zen 5 Execution Engine Leaked, Features True 512-bit FPU
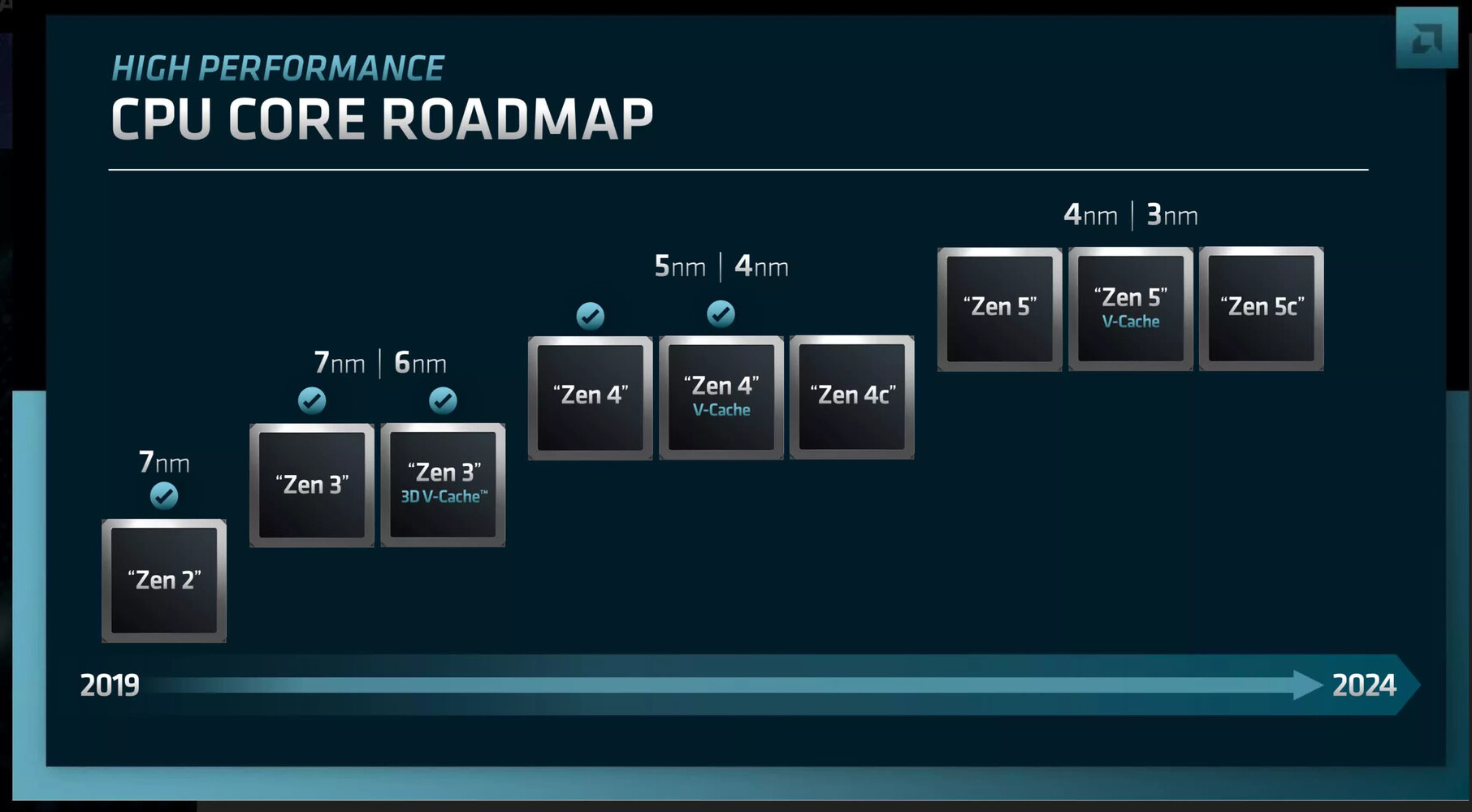
AMD "Zen 5" CPU microarchitecture will introduce a significant performance increase for AVX-512 workloads, with some sources reported as high as 40% performance increases over "Zen 4" in benchmarks that use AVX-512. A Moore's Law is Dead report detailing the execution engine of "Zen 5" holds the answer to how the company managed this—using a true 512-bit FPU. Currently, AMD uses a dual-pumped 256-bit FPU to execute AVX-512 workloads on "Zen 4." The updated FPU should significantly improve the core's performance in workloads that take advantage of 512-bit AVX or VNNI instructions, such as AI.
Giving "Zen 5" a 512-bit FPU meant that AMD also had to scale up the ancillaries—all the components that keep the FPU fed with data and instructions. The company therefore increased the capacity of the L1 DTLB. The load-store queues have been widened to meet the needs of the new FPU. The L1 Data cache has been doubled in bandwidth, and increased in size by 50%. The L1D is now 48 KB in size, up from 32 KB in "Zen 4." FPU MADD latency has been reduced by 1 cycle. Besides the FPU, AMD also increased the number of Integer execution pipes to 10, from 8 on "Zen 4." The exclusive L2 cache per core remains 1 MB in size. Update 07:02 UTC: Moore's Law is Dead reached out to us and said that the slide previously posted by them, which we had used in an earlier version of this article, is fake, but said that the information contained in that slide is correct, and that they stand by the information.
Update 07:02 UTC: Moore's Law is Dead reached out to us and said that the slide previously posted by them, which we had used in an earlier version of this article, is fake, but said that the information contained in that slide is correct, and that they stand by the information.
Source:
Moore's Law is Dead (YouTube)
Giving "Zen 5" a 512-bit FPU meant that AMD also had to scale up the ancillaries—all the components that keep the FPU fed with data and instructions. The company therefore increased the capacity of the L1 DTLB. The load-store queues have been widened to meet the needs of the new FPU. The L1 Data cache has been doubled in bandwidth, and increased in size by 50%. The L1D is now 48 KB in size, up from 32 KB in "Zen 4." FPU MADD latency has been reduced by 1 cycle. Besides the FPU, AMD also increased the number of Integer execution pipes to 10, from 8 on "Zen 4." The exclusive L2 cache per core remains 1 MB in size.
63 Comments on AMD Zen 5 Execution Engine Leaked, Features True 512-bit FPU
- A source for that leak is Very Questionable
- Intel AVX-512 ISA is a Complete Tech Disaster ( * )
( * ) It is based on my experience using an Intel Xeon Phi server. We reached its performance limitations in less than 4 weeks after a project was started.
Since then Intel designs have reduced the penalty and almost eliminated it altogether for Sapphire Rapids.Even with an older Skylake-X implementation that contained 2 AVX-512-capable units (one created by combining two 256-bit units, and one dedicated) the difference isn't as big, since only the red part is "dedicated" for AVX-512. Obviously there's other parts of the CPU that need to be extended for it as well.
SourceCurrent Intel desktop/mobile P-cores contain the transistors for one AVX-512 unit (the combined 2x256-bit), and the miscellaneous stuff all over the core. The server parts extend this base core with a second dedicated 512-bit unit, more cache, a mesh agent and an AMX unit, among other things we can't be sure of just from die shots.
Meteor Lake is also built on the same principle using Redwood Cove cores. It would be prohibitively expensive for Intel to design a special version of the core without them when the combined unit is used for AVX2 anyway. All that makes the E-core business even more controversial.
I doubt purging AVX-512 completely would result in 20-30% less area.
Gains from AVX-512 can be significant, some benchmarks on Phoronix show up to 20x improvement using AVX-512-FP16, but most are not as drastic. Another recent gain of 10x in AI LLM prompt evaluation speed. We're starting to see some Linux distributions compiling software specifically for the x86-64-v4 target which includes AVX-512. It's not only about the vector length, since AVX-512 contains other general improvements usable even by strictly integer-based software.
He complains at the time that Intel were trying to market AVX512 as the magic bullet to solve all problems. When in actual fact if you used it, it was horrible.
You run AVX512 code on Alder lake and your down in 3.5Ghz Territory when the Turbos were 5Ghz+ for most other things. It also meant the P Cores were physically larger per core for near 0 benefit for most work loads where as a 10-12 core design with only AVX2 would have been better for most use cases. And the other half of your die was completely useless for doing AVX512 workload so there was also that as you had to disable your E cores to use it effectively.
AMD at the time were giving him everything he wanted. More cores, Decent power levels/consumption per core and no gimmicky tools to use to extract extra performance. As he stated at the time AVX512 should have been only in HPC/Server areas and the desktop had little to no benefit from it then.
Have a quote:
Zen4 AVX512 is already a huge winner the way it is. It single-handedly turned the AVX512 ship around. It didn't need any measurable extra power to do amazing amounts of work. I now fear Zen5 is not going to be that good.
The way Zen 5 implements 512-bit operations is not yet clear. It may simply be fusing ports fp0/fp1, like they do for stores, in one cycle instead of doing it sequentially. It wouldn't take much extra area. Nor extra power compared to a dense AVX2 loop.
And what we do have evidence for from Zen 5 changes to Linux and GCC suggests general pipeline improvements too. 8 wide dispatch from micro-op cache, 6 ALU and 4 AGU. The only confirmed change for FP is a second FP store unit which does suggest improved throughput of AVX2 and AVX512 programs.
And where did you get the idea it'd be 40% faster? Discredited RDNA3 hypebeasts on twitter?
Also, keep in mind there are many more attributes than just size, like latency, number of banks, bandwidth, etc. If the next generation is moved to a new node with different characteristics, it may be achievable with e.g. a larger cache without worsening the latency significantly.
Additionally, many heavy AVX workloads are more sensitive to bandwidth than cache size.I've often criticized the large L3, as it's a very "brute force" attempt to make up for shortcomings in the architecture, a sort of "band-aid" like you rightfully call it. But if Zen 5 is significantly better, especially in the front-end and scheduling of instructions, the usefulness of extra L3 may be actually reduced.
There will obviously still be the edge-case scenarios where the extra L3 shines (mostly very bloated code), but the overall gain is close to negligible, and it's such a waste of silicon for most uses.AVX certainly support integer operations too as you say, but I suspect SPECint isn't compiled to use it, although I haven't checked thoroughly. But even so, modern CPUs do auto-vectorize in some cases, but I don't know if the front-end will be fast enough to vectorize more than 4 64-bit or 8 32-bit ops (per vector unit, so 2x) per clock. I suspect it will be very underutilized in reality, but still, in the worst case with AMD having their vector units on separate execution ports, it will allow each vector unit to work as a single ALU. Or probably split, so each FMA-pair as ALU+MUL. (whether it's worth it in power draw is uncertain)
When the prick has a long track record of deleting all his BS leak videos when they don't come true.
Longer cadence with more features and performance on the same established platform as the last gen. This is a big reason I buy AMD.
Nevermind that the slide turned out to be fake, you are drawing a conclusion based on wholly incomplete information. As usual with these kind of rumors and "leaked" slides, they are designed to generate clicks and engagement like what you've provided here. Don't fall for it, wait for official info to draw an informed conclusion.
Silly leaks aside this should finally be a very exciting year for HEDT CPUs.