MSI First with Motherboard BIOS that Supports Ryzen 9000 "Zen 5" Processors
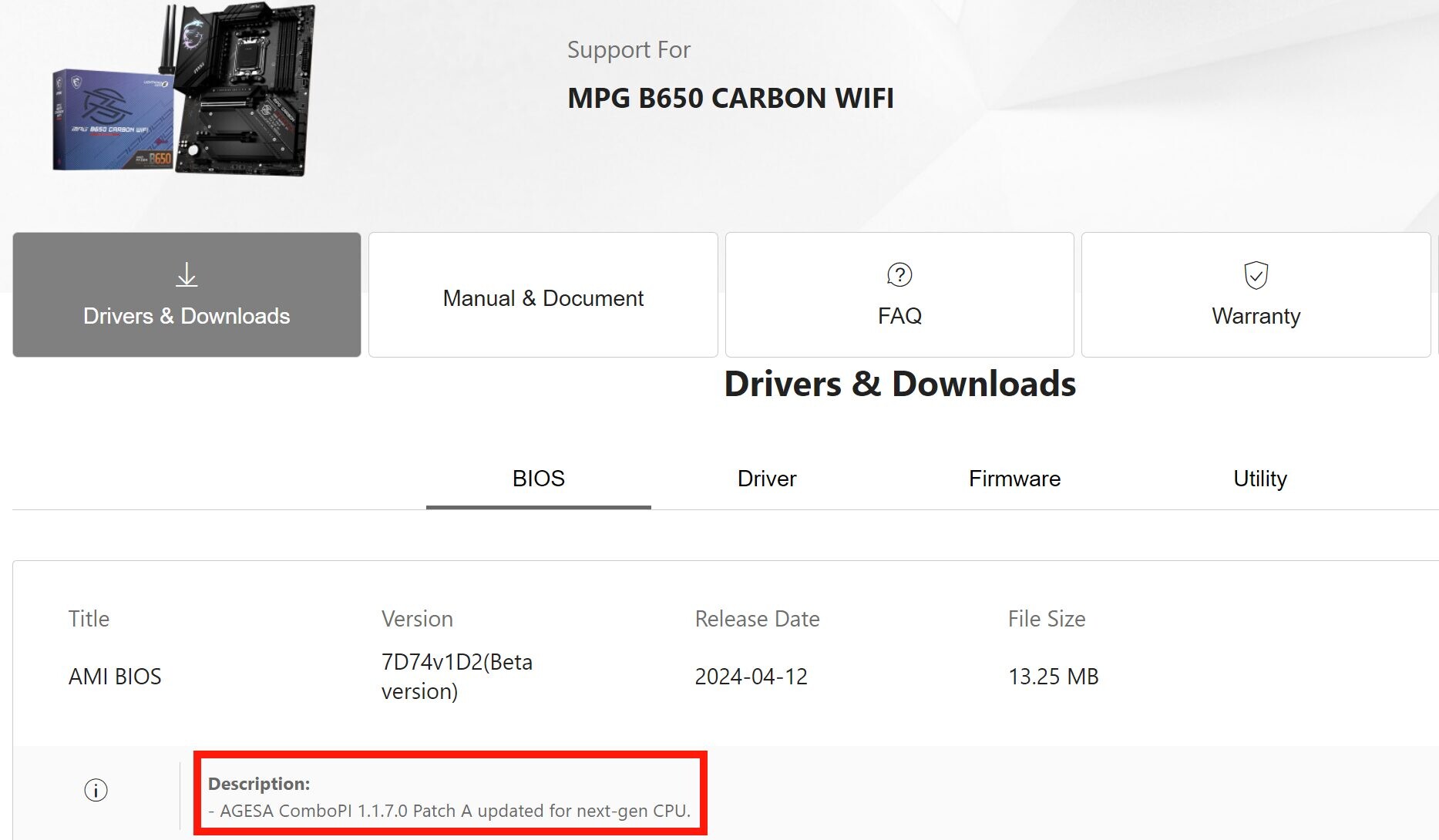
In yet another clear sign that we could see some action from AMD on the next-gen desktop processor front this Computex, motherboard maker MSI released its first beta UEFI firmware update that packs an AGESA microcode that reportedly supports the upcoming AMD Ryzen 9000 "Granite Ridge" processors. The "7D74v1D2 beta" firmware update for the MSI MPG B650 Carbon Wi-Fi motherboard encapsulates AGESA ComboPI 1.1.7.0 patch-A, with the description that it supports a "next-gen CPU," a reference to the Ryzen 9000 "Granite Ridge."
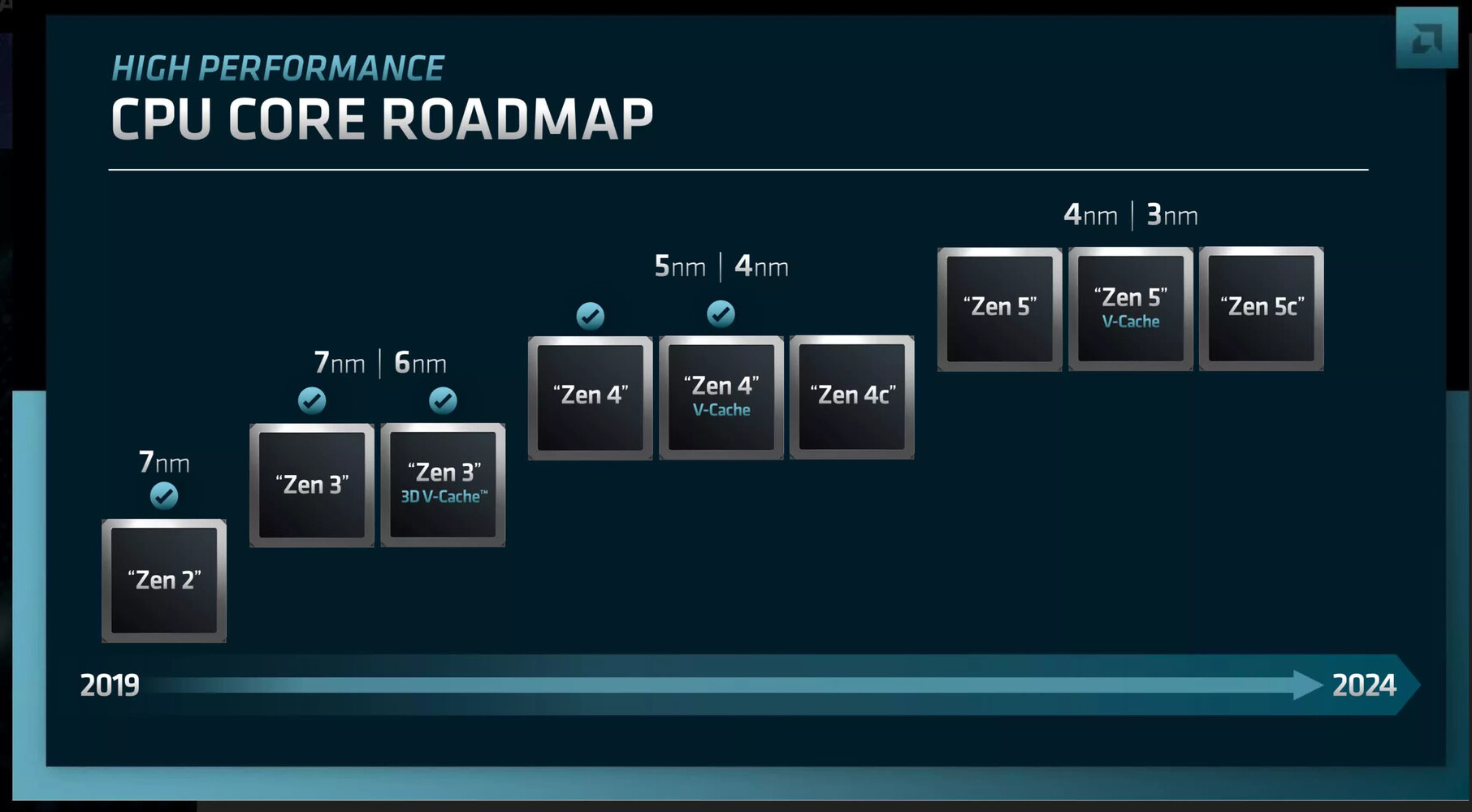
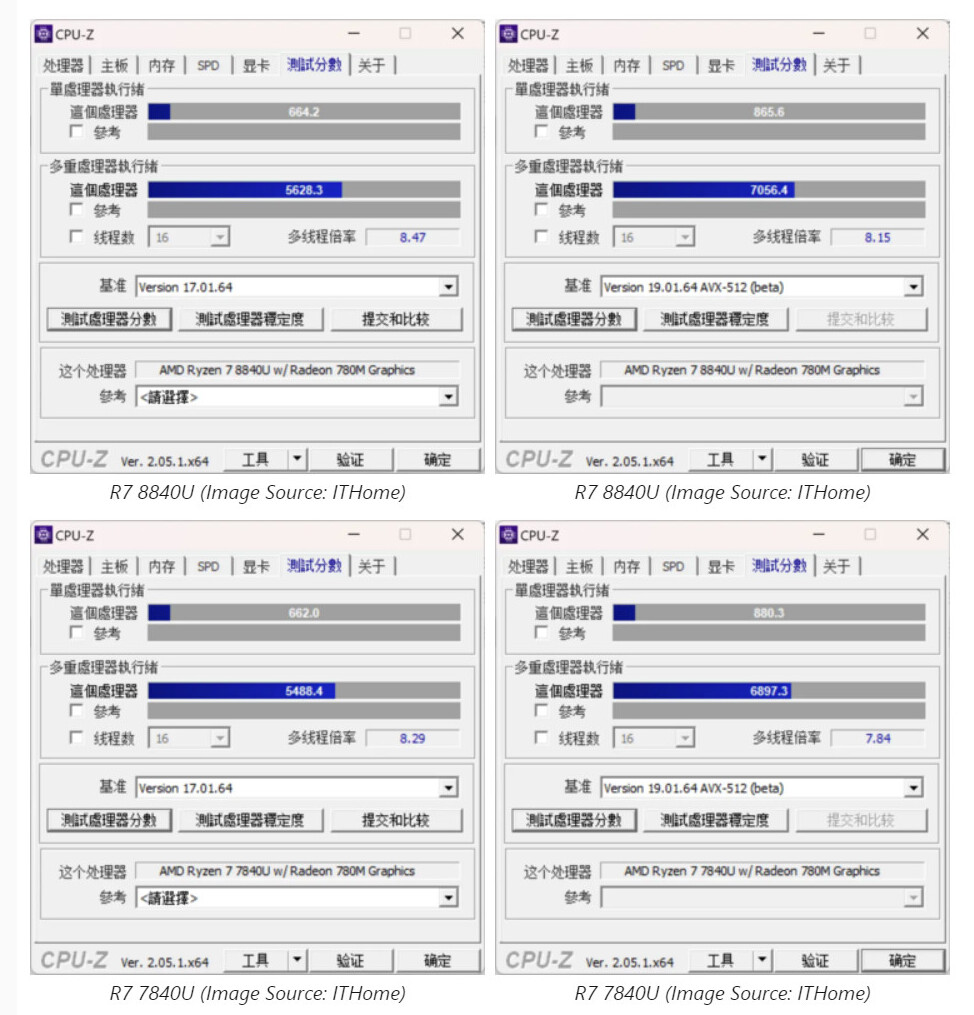
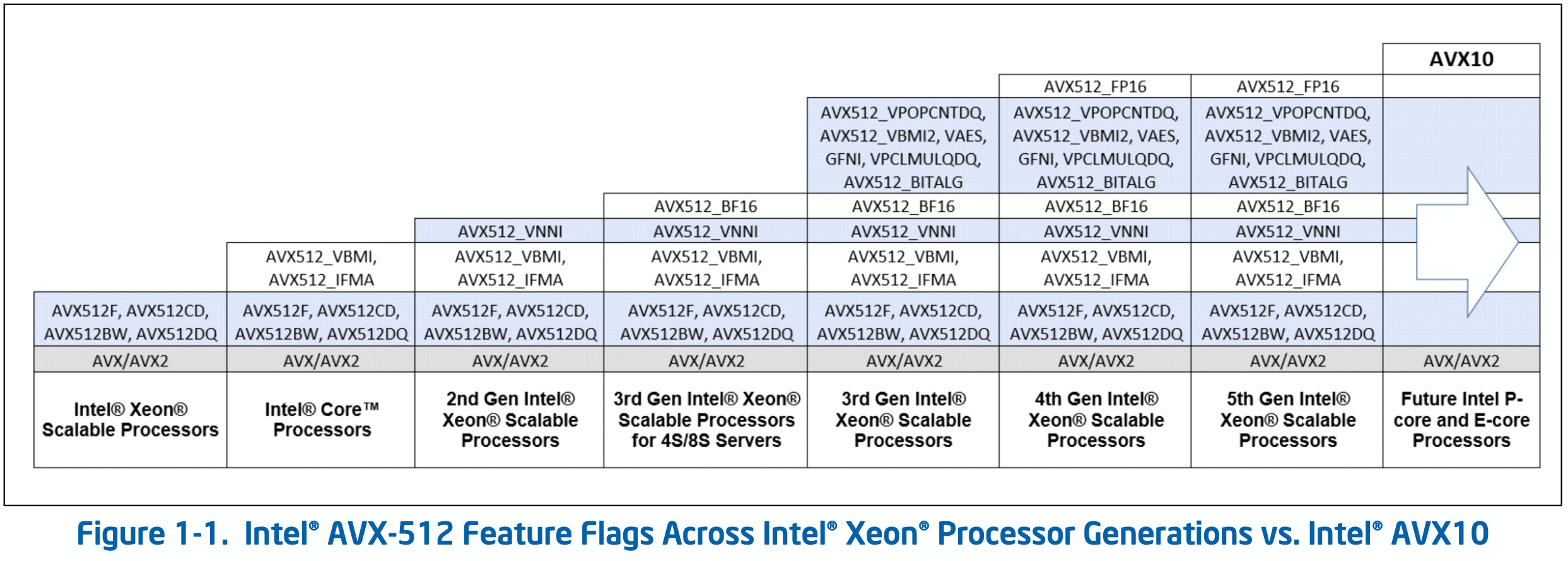
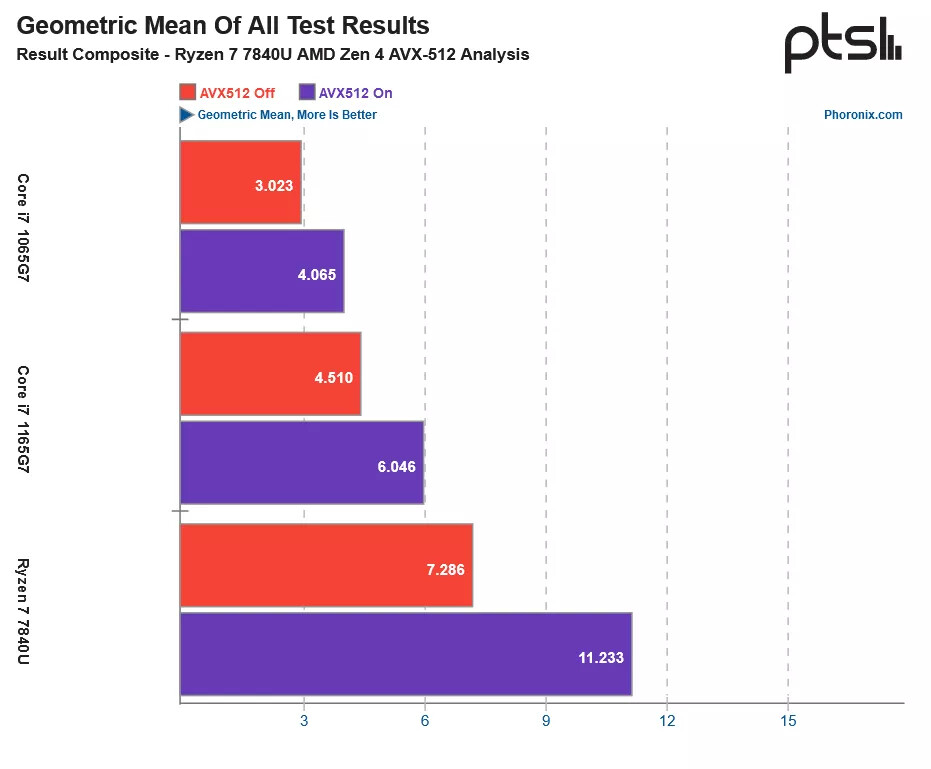
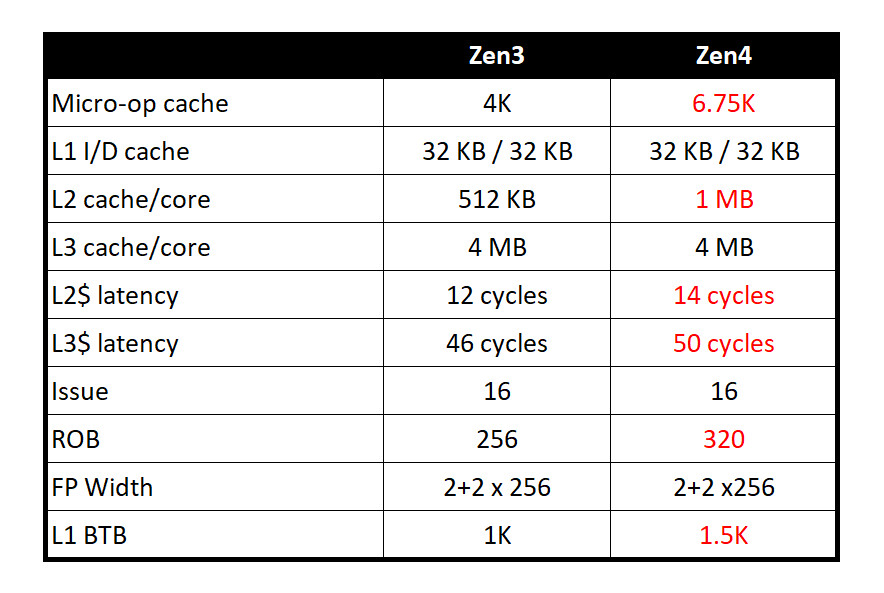
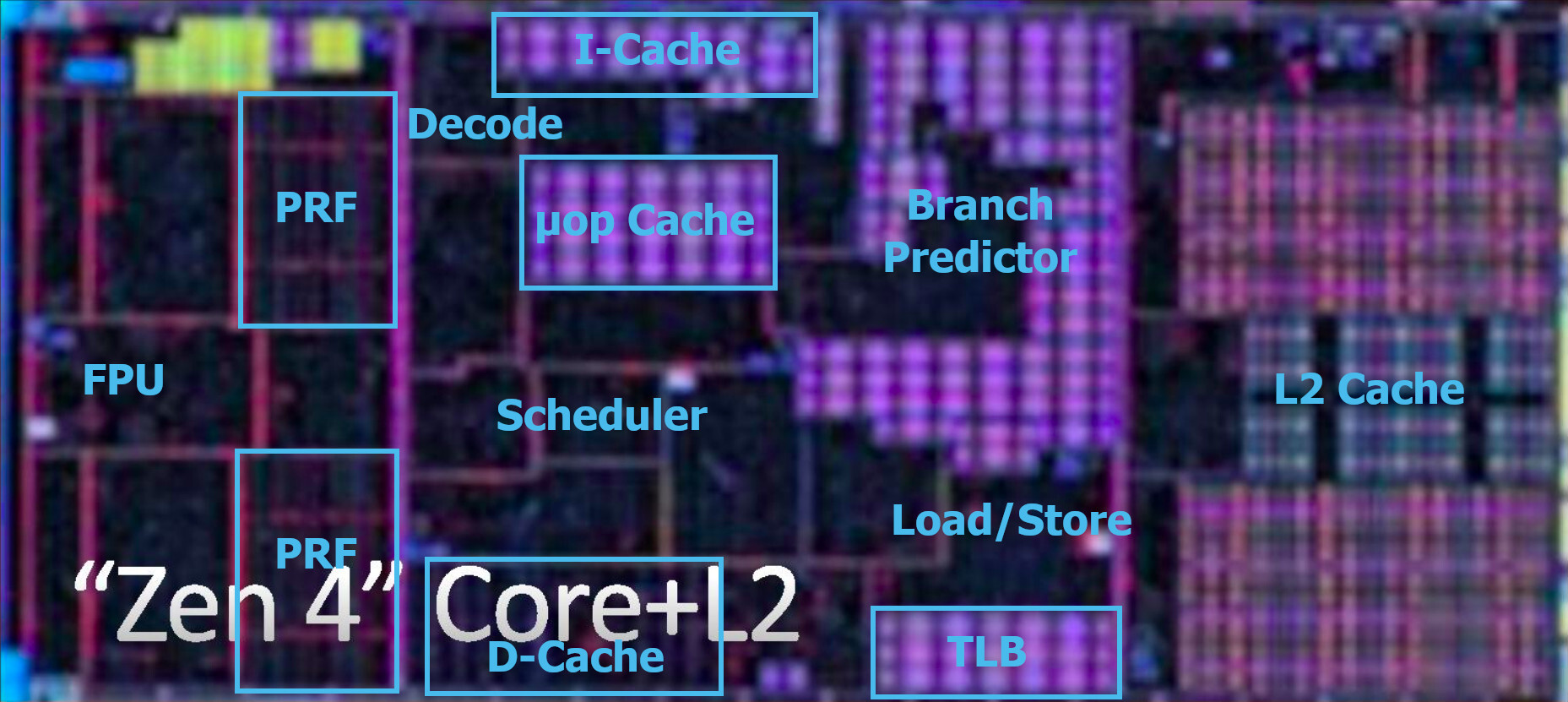
A successor to the Ryzen 7000 Raphael, the Ryzen 9000 Granite Ridge introduces the new "Zen 5" microarchitecture to the desktop platform, with CPU core counts remaining up to 16-core/32-thread. The new microarchitecture is expected to introduce generational increase in IPC, as well as improve performance of certain exotic workloads such as AVX-512. The processors are said to be launching alongside the new AMD 800-series motherboard chipset. If AMD is using Computex as a platform to showcase these processors, it's likely we might see the first of these motherboards as well.
A successor to the Ryzen 7000 Raphael, the Ryzen 9000 Granite Ridge introduces the new "Zen 5" microarchitecture to the desktop platform, with CPU core counts remaining up to 16-core/32-thread. The new microarchitecture is expected to introduce generational increase in IPC, as well as improve performance of certain exotic workloads such as AVX-512. The processors are said to be launching alongside the new AMD 800-series motherboard chipset. If AMD is using Computex as a platform to showcase these processors, it's likely we might see the first of these motherboards as well.