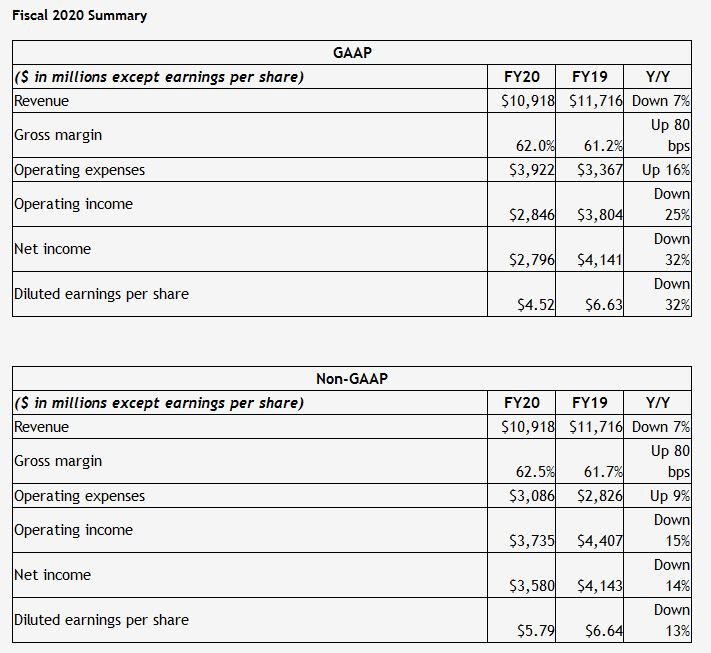
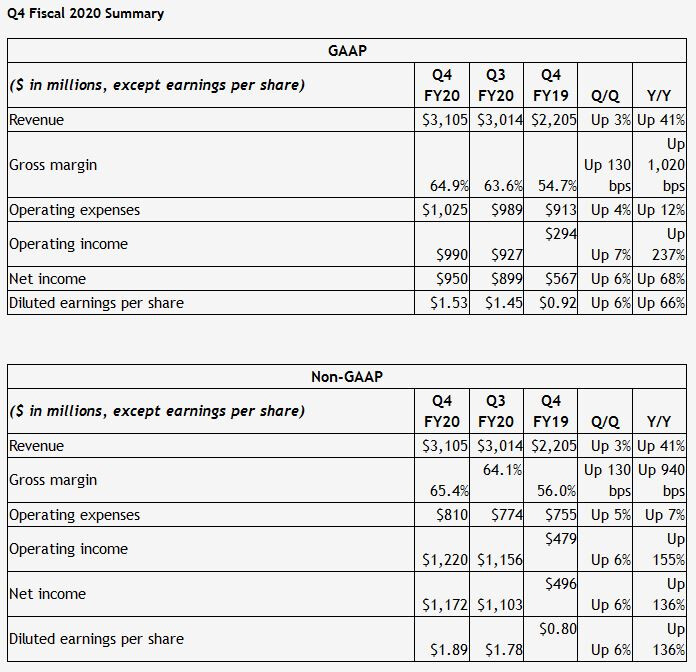
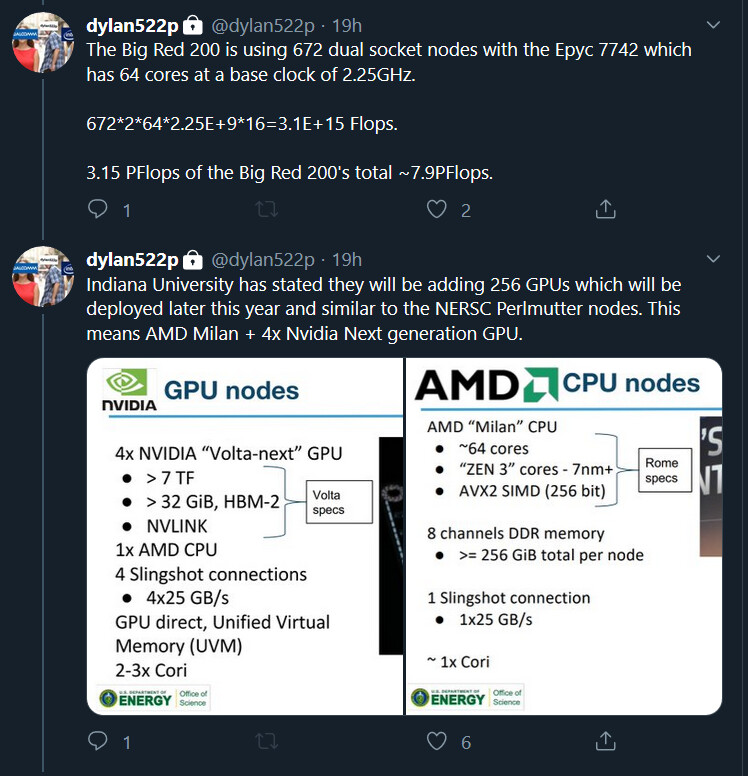
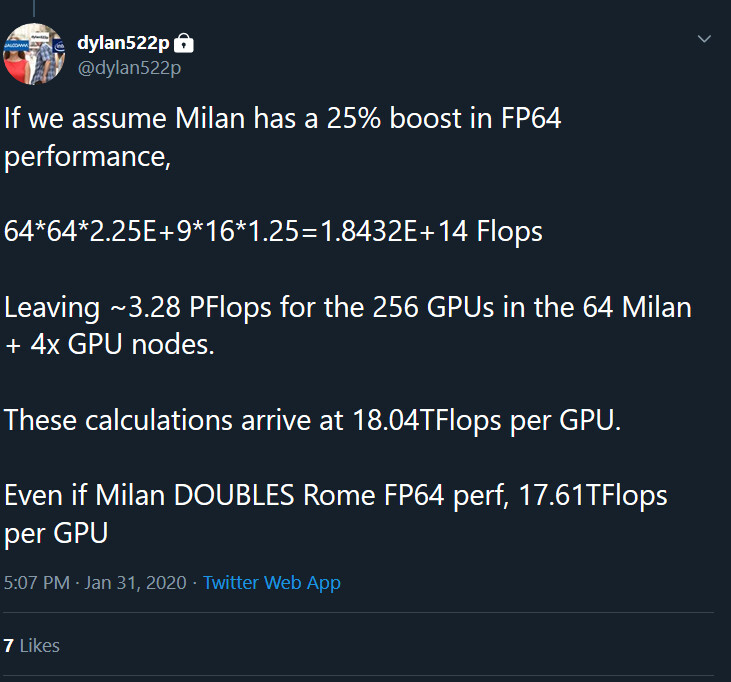
NVIDIA Ampere Cooling Solution Heatsink Pictured, Rumors of Airflow Magic Quashed
Although still a blurry-cam pic, this new picture of three GeForce RTX 3080 "Ampere" graphics card reference heatsinks on a factory-floor reveals exactly how the cooling solution works. The main heat-dissipation component appears to be a vapor chamber base, above which there are four flattened copper heat pipes, which hold the cooler's four aluminium fin arrays together. The first array is directly above the CPU/memory/VRM area, and consists of a dense stack of aluminium fins that make up a cavity for the fan on the obverse side of the graphics card. This fan vents air onto the first heatsink element, and some of its air is guided by the heatsink to two trapezium shaped aluminium fin-stacks that pull heat from the flattened heat pipes, and get airflow from the obverse fan.
The heat pipes make their way to the card's second dense aluminium fin-stack. This fin-stack is as thick as the card itself, as there's no PCB here. This fin-stack is ventilated by the card's second fan, located on the reverse side, which pulls air through this fin-stack and vents upward. We attempted to detail the cooling solution, the card, and other SKU details in an older article. We've also added a picture of a Sapphire Radeon RX Vega 56 Pulse graphics card. This NVIDIA heatsink is essentially like that, but with the second fan on the other side of the card to make it look more complicated than it actually is.

The heat pipes make their way to the card's second dense aluminium fin-stack. This fin-stack is as thick as the card itself, as there's no PCB here. This fin-stack is ventilated by the card's second fan, located on the reverse side, which pulls air through this fin-stack and vents upward. We attempted to detail the cooling solution, the card, and other SKU details in an older article. We've also added a picture of a Sapphire Radeon RX Vega 56 Pulse graphics card. This NVIDIA heatsink is essentially like that, but with the second fan on the other side of the card to make it look more complicated than it actually is.