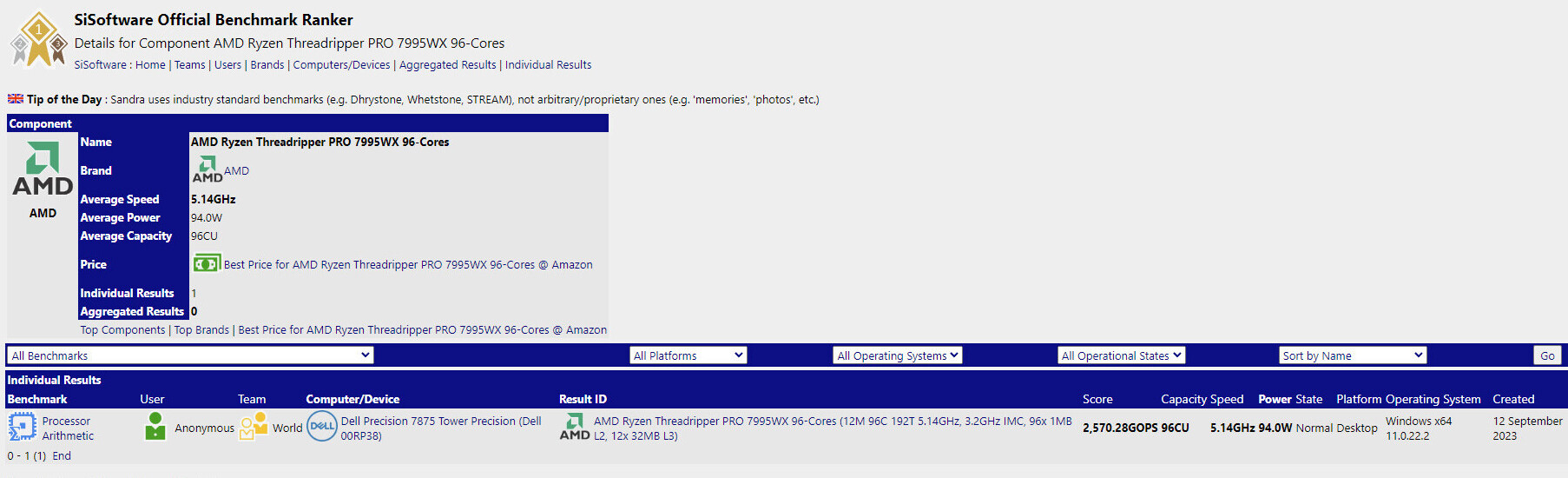
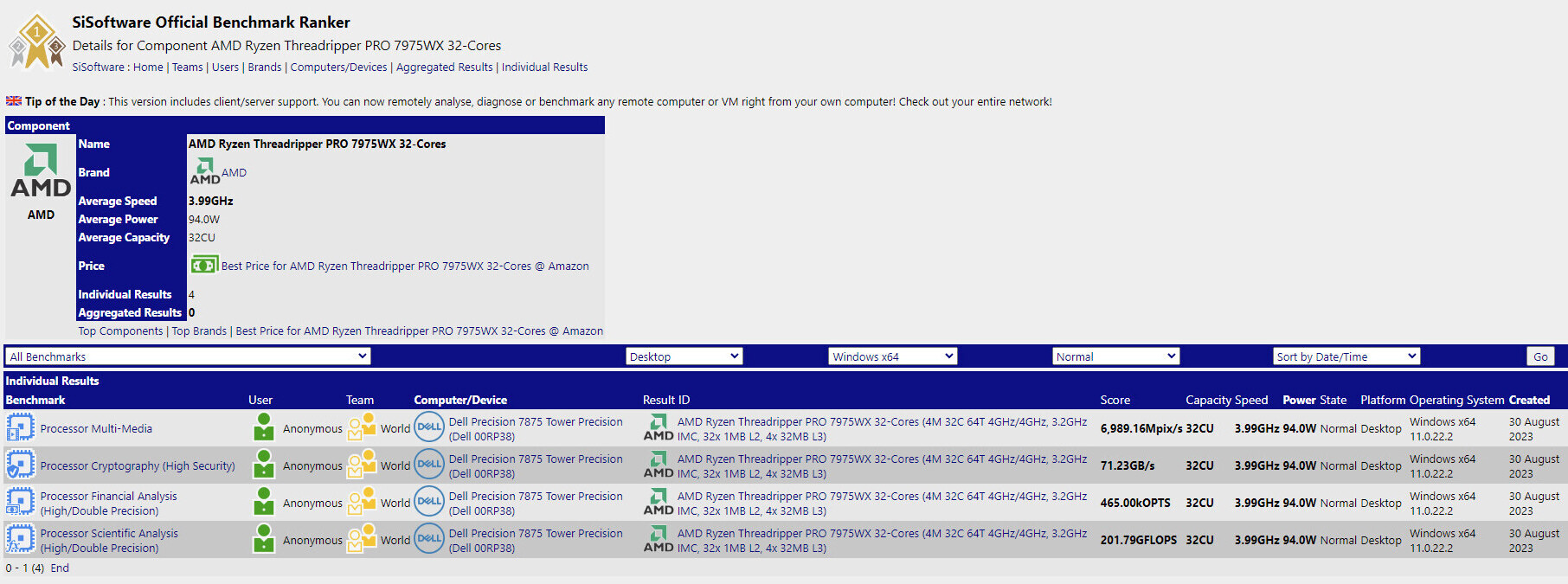
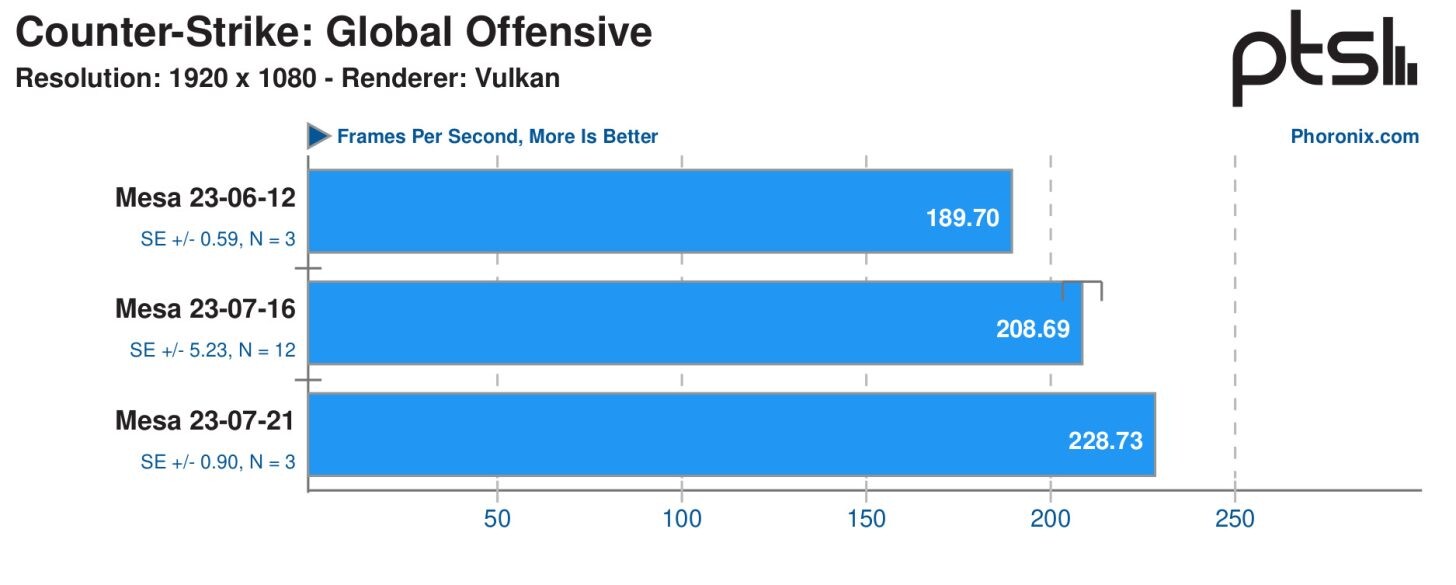
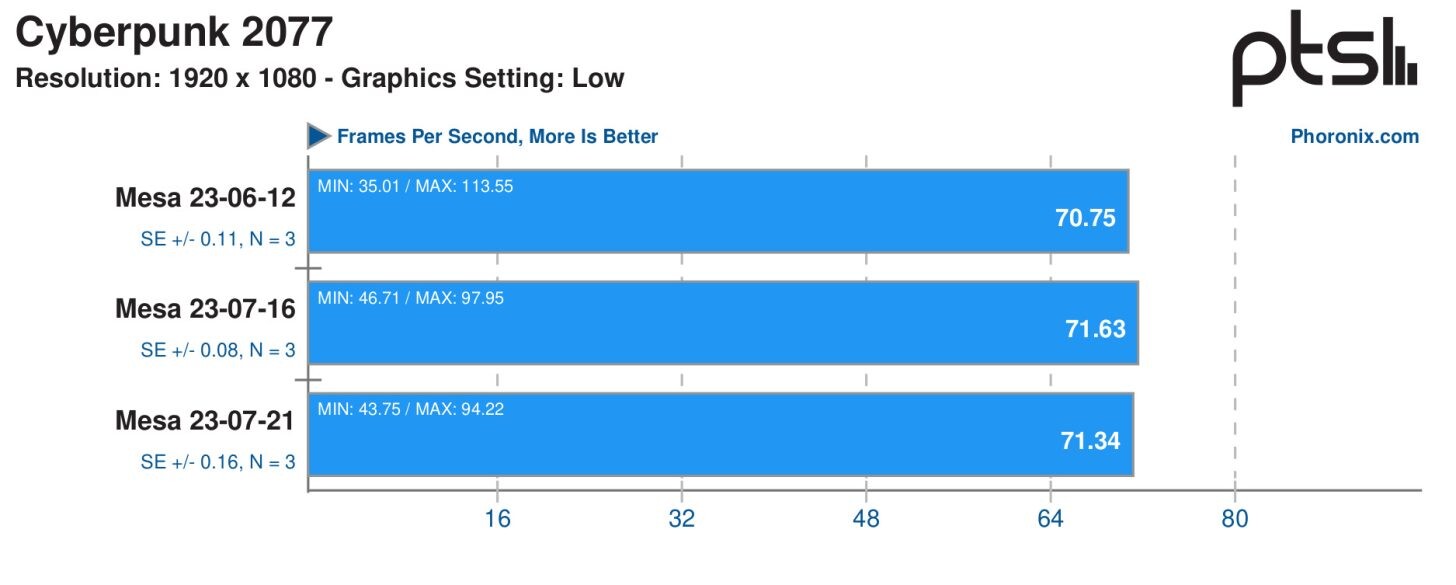
ScaleFlux SFX 5016 Will Set New Benchmarks for Enterprise SSD Efficiency and AI Workload Performance
As the IT sector continues to seek answers for scaling data processing performance while simultaneously improving efficiency - in terms of performance and density per watt, per system, per rack, and per dollar of CapEx and OpEx - ScaleFlux is answering the call with innovative design choices in its SSD controllers. The SFX 5016 promises to set new standards both for performance and for power efficiency.
In addition to carrying forward the transparent compression feature that ScaleFlux first released in 2020 in upgraded in 2022 with the SFX 3016 computational storage drive controller, the new SFX 5016 SOC processor includes a number of design advances.
In addition to carrying forward the transparent compression feature that ScaleFlux first released in 2020 in upgraded in 2022 with the SFX 3016 computational storage drive controller, the new SFX 5016 SOC processor includes a number of design advances.