AMD's RDNA 4 GPUs Could Stick with 18 Gbps GDDR6 Memory
Today, we have the latest round of leaks that suggest that AMD's upcoming RDNA 4 graphics cards, codenamed the "RX 8000-series," might continue to rely on GDDR6 memory modules. According to Kepler on X, the next-generation GPUs from AMD are expected to feature 18 Gbps GDDR6 memory, marking the fourth consecutive RDNA architecture to employ this memory standard. While GDDR6 may not offer the same bandwidth capabilities as the newer GDDR7 standard, this decision does not necessarily imply that RDNA 4 GPUs will be slow performers. AMD's choice to stick with GDDR6 is likely driven by factors such as meeting specific memory bandwidth requirements and cost optimization for PCB designs. However, if the rumor of 18 Gbps GDDR6 memory proves accurate, it would represent a slight step back from the 18-20 Gbps GDDR6 memory used in AMD's current RDNA 3 offerings, such as the RX 7900 XT and RX 7900 XTX GPUs.
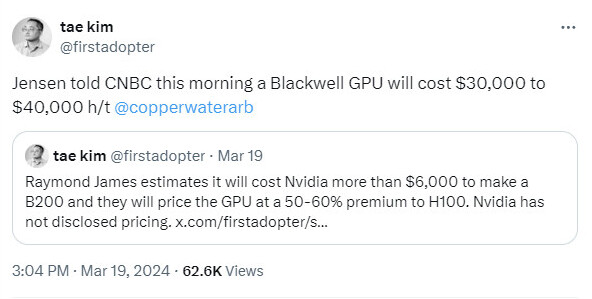
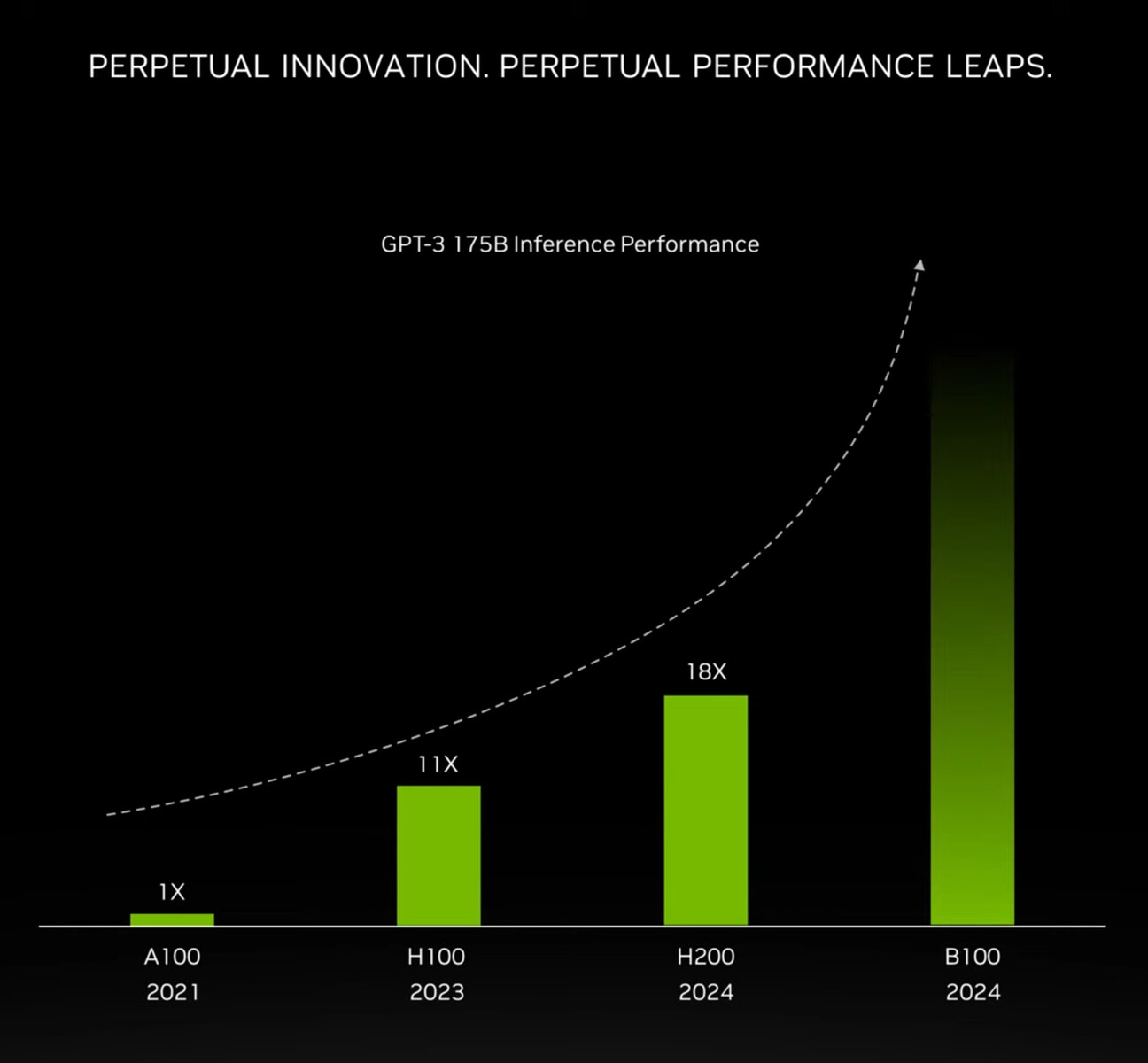
AMD's first generation RDNA used GDDR6 with 12-14 Gbps speeds, RDNA 2 came with GDDR6 at 14-18 Gbps, and the current RDNA 3 used 18-20 Gbps GDDR6. Without an increment in memory generation, speeds should stay the same at 18 Gbps. However, it is crucial to remember that leaks should be treated with skepticism, as AMD's final memory choices for RDNA 4 could change before the official launch. The decision to use GDDR6 versus GDDR7 could have significant implications in the upcoming battle between AMD, NVIDIA, and Intel's next-generation GPU architectures. If AMD indeed opts for GDDR6 while NVIDIA pivots to GDDR7 for its "Blackwell" GPUs, it could create a disparity in memory bandwidth performance between the competing products. All three major GPU manufacturers—AMD, NVIDIA, and Intel with its "Battlemage" architecture—are expected to unveil their next-generation offerings in the fall of this year. As we approach these highly anticipated releases, more concrete details on specifications and performance capabilities will emerge, providing a clearer picture of the competitive landscape.
AMD's first generation RDNA used GDDR6 with 12-14 Gbps speeds, RDNA 2 came with GDDR6 at 14-18 Gbps, and the current RDNA 3 used 18-20 Gbps GDDR6. Without an increment in memory generation, speeds should stay the same at 18 Gbps. However, it is crucial to remember that leaks should be treated with skepticism, as AMD's final memory choices for RDNA 4 could change before the official launch. The decision to use GDDR6 versus GDDR7 could have significant implications in the upcoming battle between AMD, NVIDIA, and Intel's next-generation GPU architectures. If AMD indeed opts for GDDR6 while NVIDIA pivots to GDDR7 for its "Blackwell" GPUs, it could create a disparity in memory bandwidth performance between the competing products. All three major GPU manufacturers—AMD, NVIDIA, and Intel with its "Battlemage" architecture—are expected to unveil their next-generation offerings in the fall of this year. As we approach these highly anticipated releases, more concrete details on specifications and performance capabilities will emerge, providing a clearer picture of the competitive landscape.