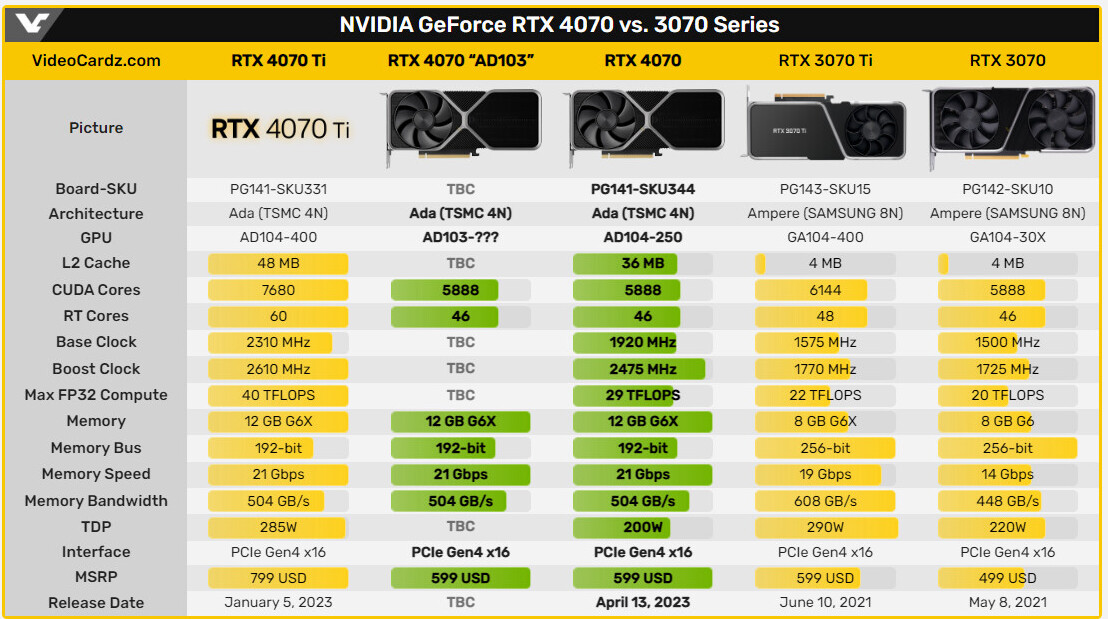
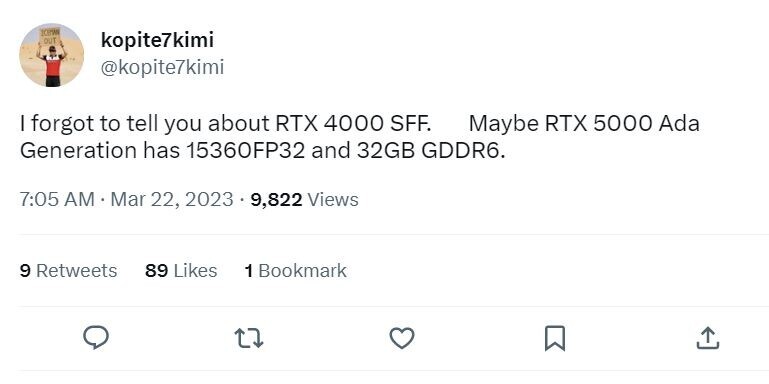
NVIDIA GeForce RTX 4070 Variant Could be Refreshed With AD103 GPU
Hardware tipster kopite7kimi has learned from insider sources that a variant of NVIDIA's GeForce RTX 4070 graphic card could be lined up with a different GPU - the AD103 instead of the currently utilized AD104-derived AD104-250-A1. The Ada Lovelace-based architecture is a staple across the RTX 40-series of graphics cards, but a fully unlocked AD103 is not yet attached to any product on the market - it will be a strange move for NVIDIA to refresh or expand the mid-range RTX 4070 lineup with a much larger GPU, albeit in a reduced form. A cut down variant of the AD103 is currently housed within NVIDIA's GeForce RTX 4080 graphics card - its AD103-300-A1 GPU has 9728 CUDA Cores and Team Green's engineers have chosen to disable 5% of the full article's capabilities.
The hardware boffins will need to do a lot of pruning if the larger GPU ends up on the rumored RTX 4070 sort-of upgrade - the SKU's 5,888 CUDA core count spec would require a 42% reduction in GPU potency. It is somewhat curious that the RTX 4070 Ti has not been mentioned by the tipster - you would think that the more powerful card (than the standard 4070) would be the logical and immediate candidate for this type of treatment. In theory NVIDIA could be re-purposing dies that do not meet RTX 4080-level standards, thus salvaging rejected material and repurposing it for step down card models.


The hardware boffins will need to do a lot of pruning if the larger GPU ends up on the rumored RTX 4070 sort-of upgrade - the SKU's 5,888 CUDA core count spec would require a 42% reduction in GPU potency. It is somewhat curious that the RTX 4070 Ti has not been mentioned by the tipster - you would think that the more powerful card (than the standard 4070) would be the logical and immediate candidate for this type of treatment. In theory NVIDIA could be re-purposing dies that do not meet RTX 4080-level standards, thus salvaging rejected material and repurposing it for step down card models.