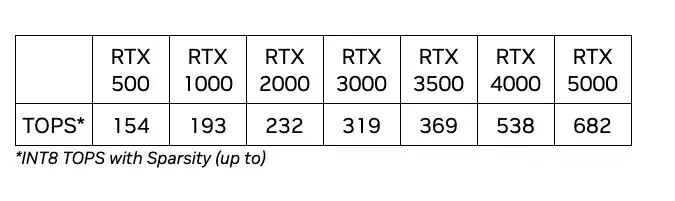
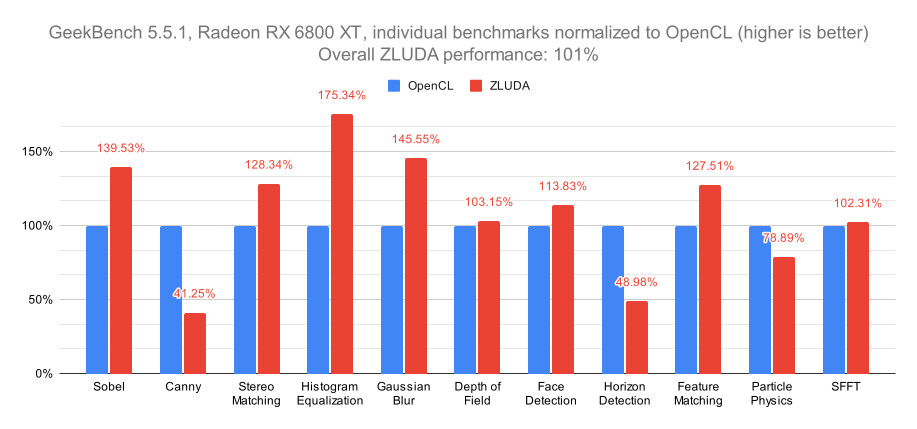
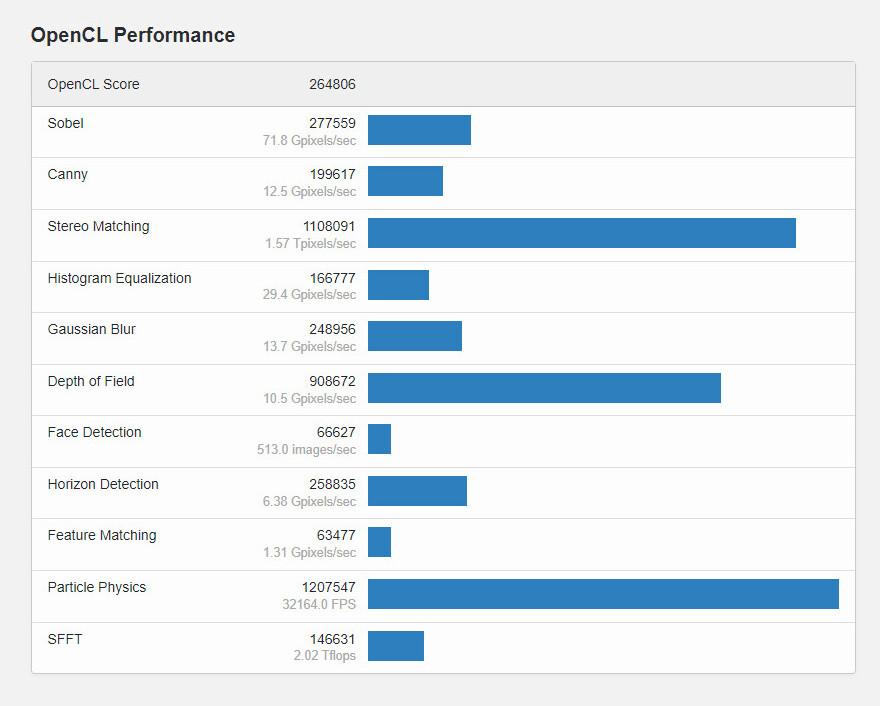
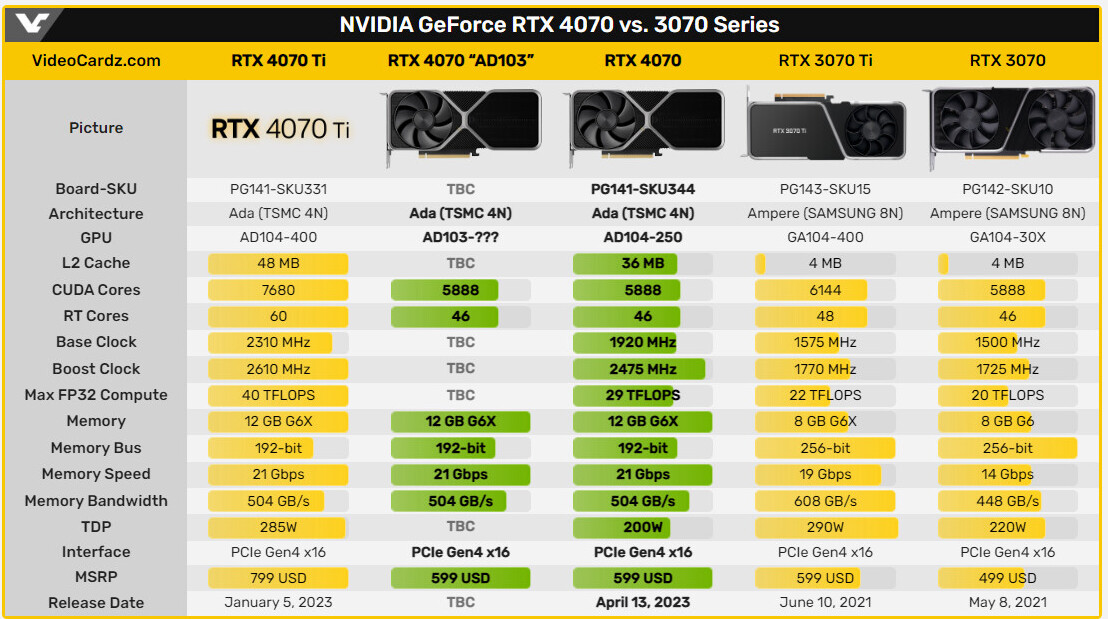
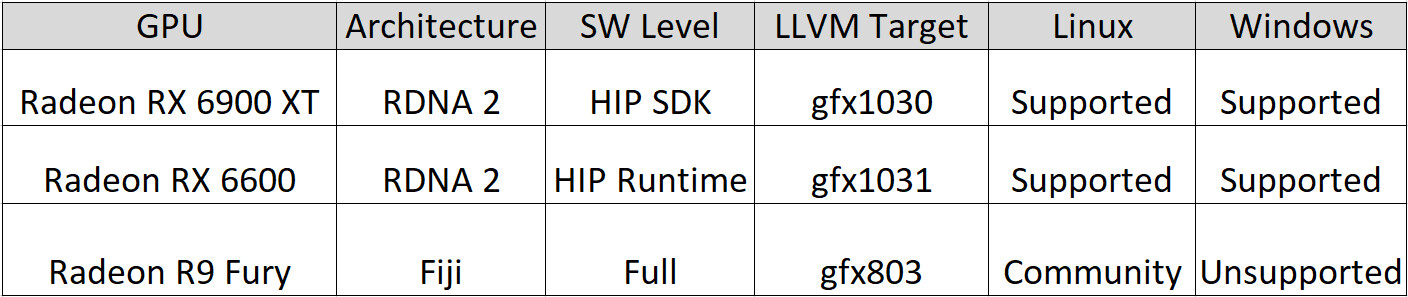
NVIDIA Cracks Down on CUDA Translation Layers, Changes Licensing Terms
NVIDIA's Compute Unified Device Architecture (CUDA) has long been the de facto standard programming interface for developing GPU-accelerated software. Over the years, NVIDIA has built an entire ecosystem around CUDA, cementing its position as the leading GPU computing and AI manufacturer. However, rivals AMD and Intel have been trying to make inroads with their own open API offerings—ROCm from AMD and oneAPI from Intel. The idea was that developers could more easily run existing CUDA code on non-NVIDIA GPUs by providing open access through translation layers. Developers had created projects like ZLUDA to translate CUDA to ROCm, and Intel's CUDA to SYCL aimed to do the same for oneAPI. However, with the release of CUDA 11.5, NVIDIA appears to have cracked down on these translation efforts by modifying its terms of use, according to developer Longhorn on X.
"You may not reverse engineer, decompile or disassemble any portion of the output generated using Software elements for the purpose of translating such output artifacts to target a non-NVIDIA platform," says the CUDA 11.5 terms of service document. The changes don't seem to be technical in nature but rather licensing restrictions. The impact remains to be seen, depending on how much code still requires translation versus running natively on each vendor's API. While CUDA gave NVIDIA a unique selling point, its supremacy has diminished as more libraries work across hardware. Still, the move could slow the adoption of AMD and Intel offerings by making it harder for developers to port existing CUDA applications. As GPU-accelerated computing grows in fields like AI, the battle for developer mindshare between NVIDIA, AMD, and Intel is heating up.
"You may not reverse engineer, decompile or disassemble any portion of the output generated using Software elements for the purpose of translating such output artifacts to target a non-NVIDIA platform," says the CUDA 11.5 terms of service document. The changes don't seem to be technical in nature but rather licensing restrictions. The impact remains to be seen, depending on how much code still requires translation versus running natively on each vendor's API. While CUDA gave NVIDIA a unique selling point, its supremacy has diminished as more libraries work across hardware. Still, the move could slow the adoption of AMD and Intel offerings by making it harder for developers to port existing CUDA applications. As GPU-accelerated computing grows in fields like AI, the battle for developer mindshare between NVIDIA, AMD, and Intel is heating up.