Groq LPU AI Inference Chip is Rivaling Major Players like NVIDIA, AMD, and Intel
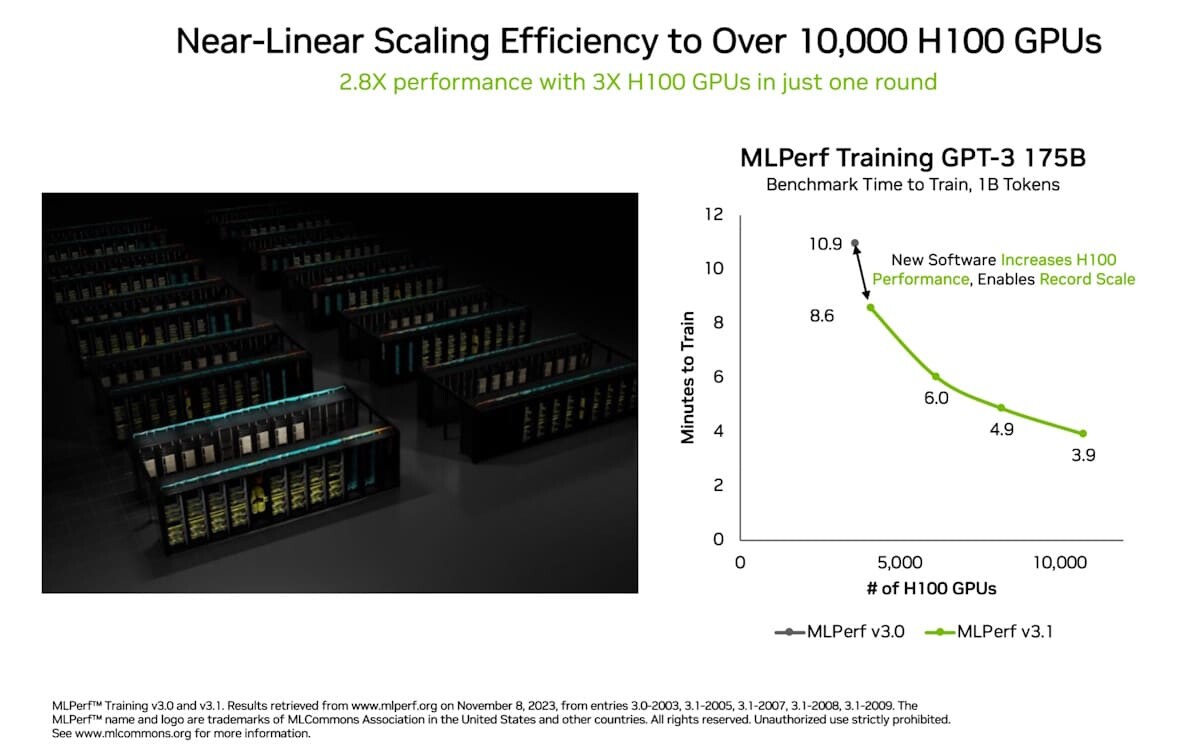
AI workloads are split into two different categories: training and inference. While training requires large computing and memory capacity, access speeds are not a significant contributor; inference is another story. With inference, the AI model must run extremely fast to serve the end-user with as many tokens (words) as possible, hence giving the user answers to their prompts faster. An AI chip startup, Groq, which was in stealth mode for a long time, has been making major moves in providing ultra-fast inference speeds using its Language Processing Unit (LPU) designed for large language models (LLMs) like GPT, Llama, and Mistral LLMs. The Groq LPU is a single-core unit based on the Tensor-Streaming Processor (TSP) architecture which achieves 750 TOPS at INT8 and 188 TeraFLOPS at FP16, with 320x320 fused dot product matrix multiplication, in addition to 5,120 Vector ALUs.
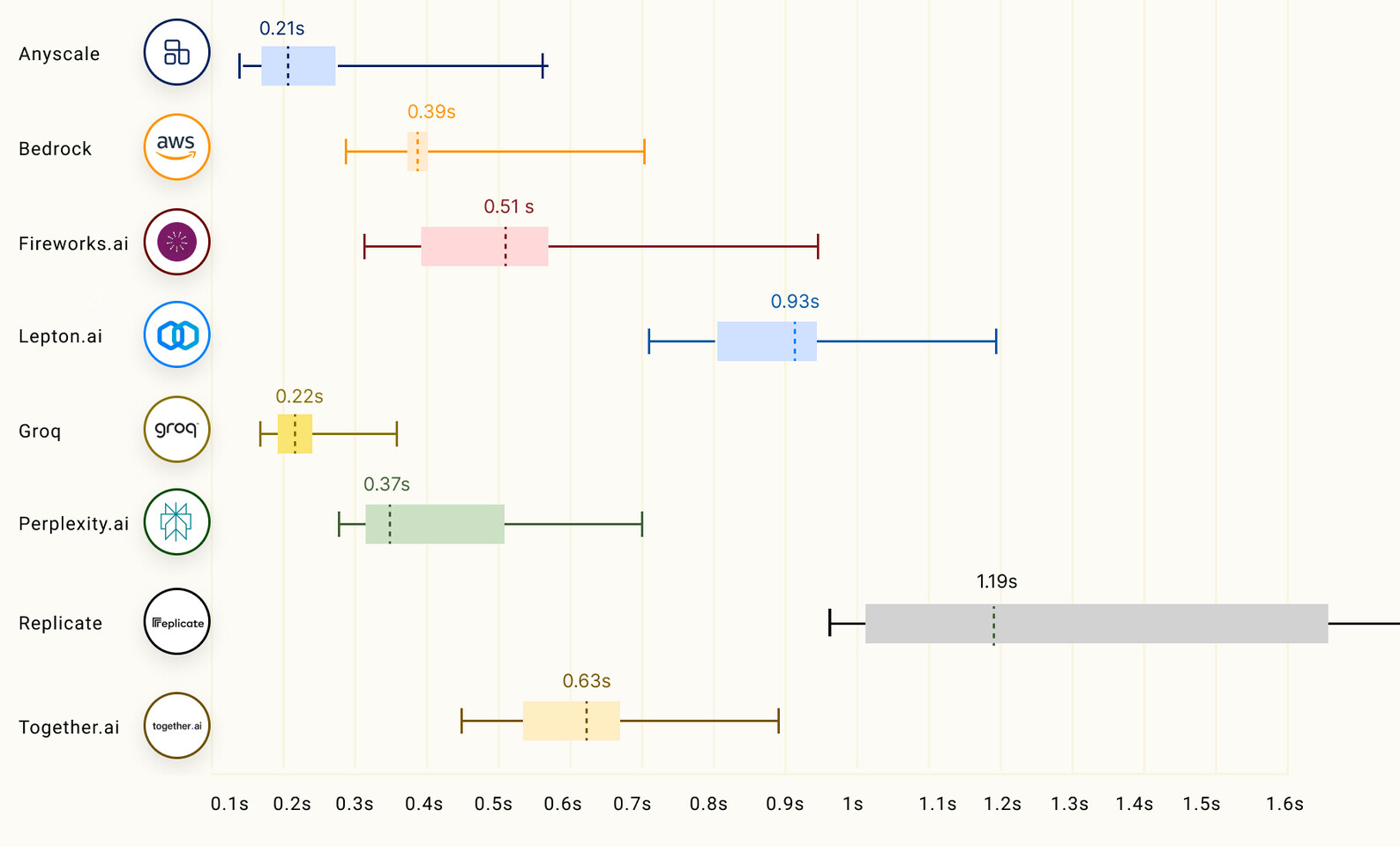
Having massive concurrency with 80 TB/s of bandwidth, the Groq LPU has 230 MB capacity of local SRAM. All of this is working together to provide Groq with a fantastic performance, making waves over the past few days on the internet. Serving the Mixtral 8x7B model at 480 tokens per second, the Groq LPU is providing one of the leading inference numbers in the industry. In models like Llama 2 70B with 4096 token context length, Groq can serve 300 tokens/s, while in smaller Llama 2 7B with 2048 tokens of context, Groq LPU can output 750 tokens/s. According to the LLMPerf Leaderboard, the Groq LPU is beating the GPU-based cloud providers at inferencing LLMs Llama in configurations of anywhere from 7 to 70 billion parameters. In token throughput (output) and time to first token (latency), Groq is leading the pack, achieving the highest throughput and second lowest latency.


Having massive concurrency with 80 TB/s of bandwidth, the Groq LPU has 230 MB capacity of local SRAM. All of this is working together to provide Groq with a fantastic performance, making waves over the past few days on the internet. Serving the Mixtral 8x7B model at 480 tokens per second, the Groq LPU is providing one of the leading inference numbers in the industry. In models like Llama 2 70B with 4096 token context length, Groq can serve 300 tokens/s, while in smaller Llama 2 7B with 2048 tokens of context, Groq LPU can output 750 tokens/s. According to the LLMPerf Leaderboard, the Groq LPU is beating the GPU-based cloud providers at inferencing LLMs Llama in configurations of anywhere from 7 to 70 billion parameters. In token throughput (output) and time to first token (latency), Groq is leading the pack, achieving the highest throughput and second lowest latency.