Tenstorrent Selects Samsung Foundry to Manufacture Next-Generation AI Chiplet
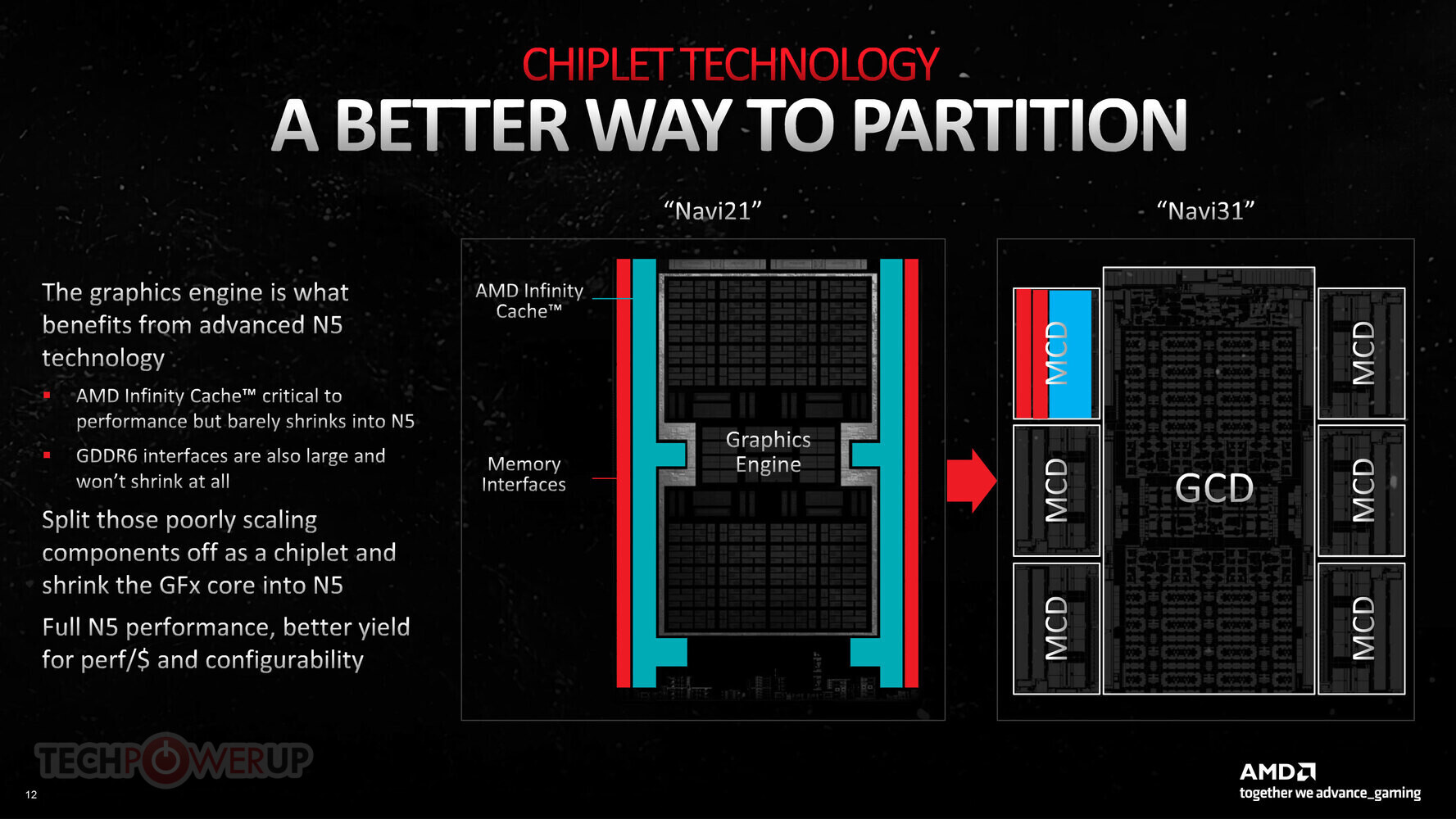
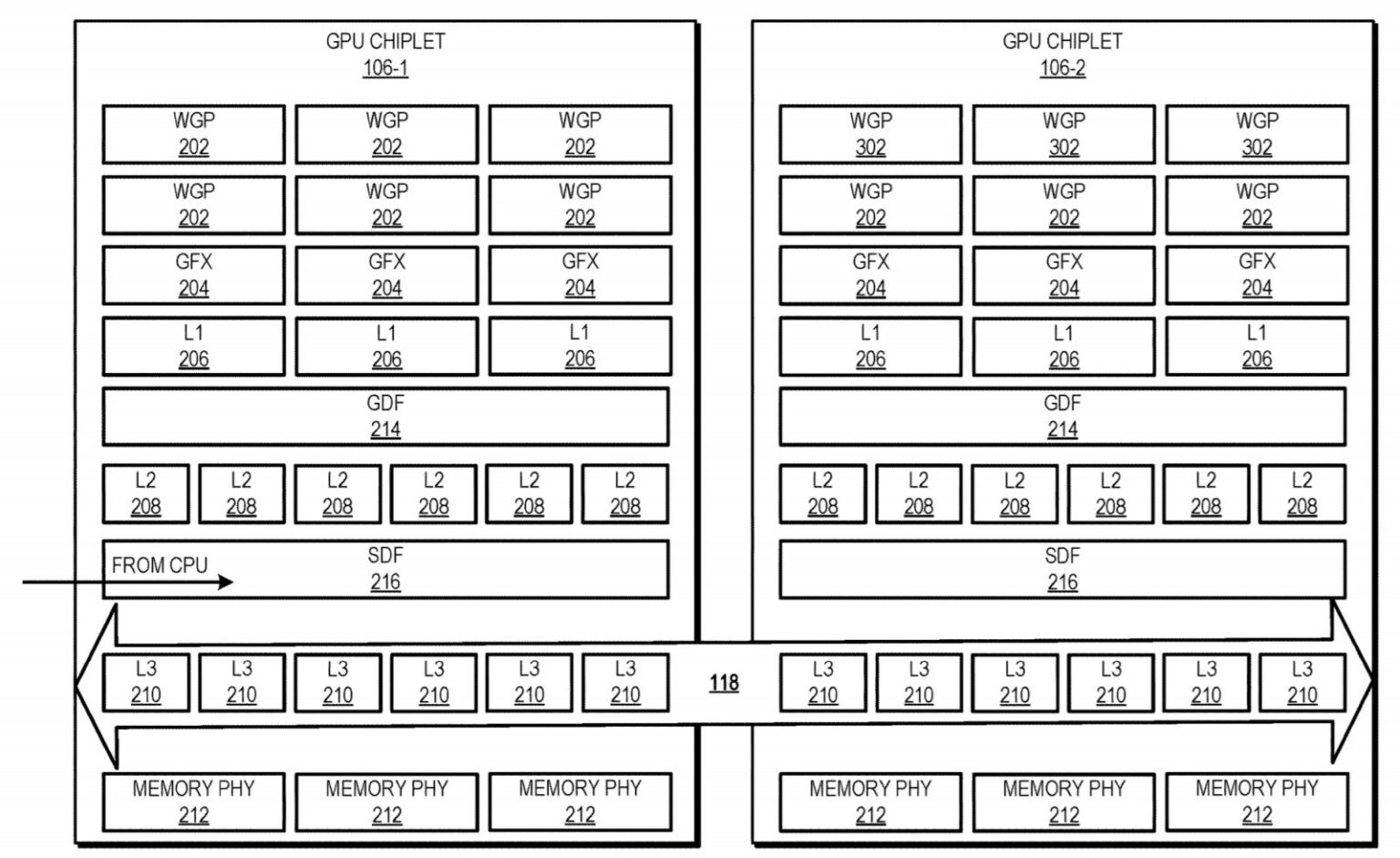
Tenstorrent, a company that sells AI processors and licenses AI and RISC-V IP, announced today that it selected Samsung Foundry to bring Tenstorrent's next generation of AI chiplets to market. Tenstorrent builds powerful RISC-V CPU and AI acceleration chiplets, aiming to push the boundaries of compute in multiple industries such as data center, automotive and robotics. These chiplets are designed to deliver scalable power from milliwatts to megawatts, catering to a wide range of applications from edge devices to data centers.
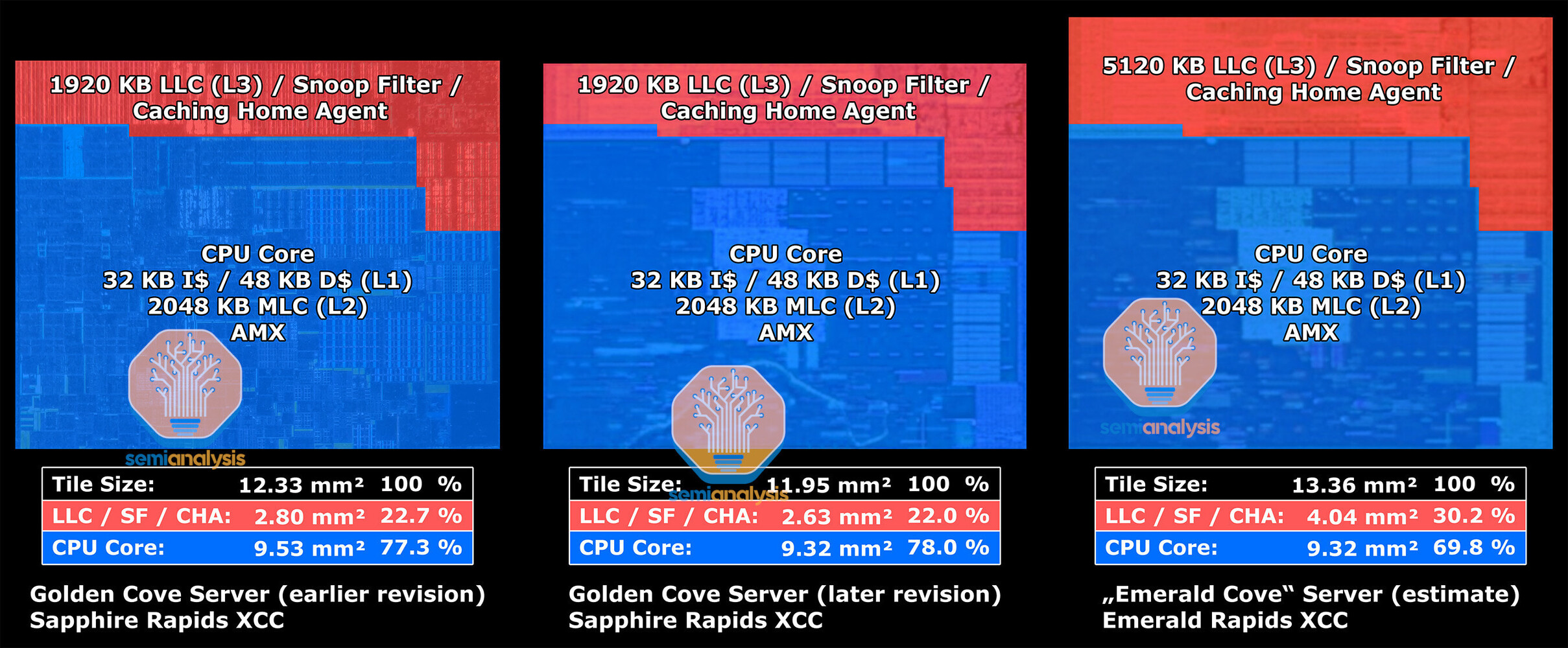
To ensure the highest quality and cutting-edge manufacturing capabilities for its chiplet, Tenstorrent has selected Samsung's Foundry Design Service team, known for their expertise in silicon manufacturing. The chiplets will be manufactured using Samsung's state-of-the-art SF4X process, which boasts an impressive 4 nm architecture.
To ensure the highest quality and cutting-edge manufacturing capabilities for its chiplet, Tenstorrent has selected Samsung's Foundry Design Service team, known for their expertise in silicon manufacturing. The chiplets will be manufactured using Samsung's state-of-the-art SF4X process, which boasts an impressive 4 nm architecture.