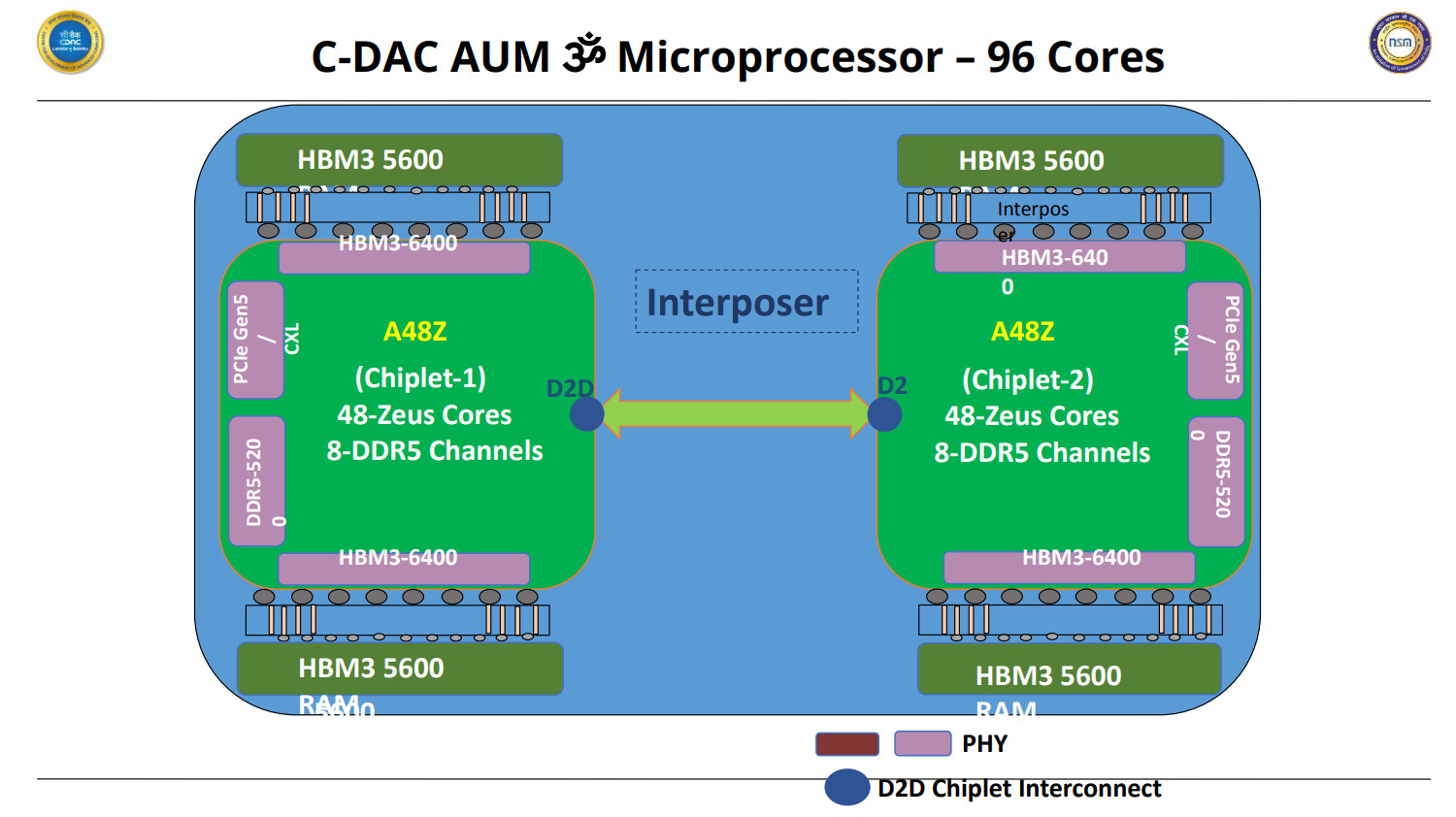
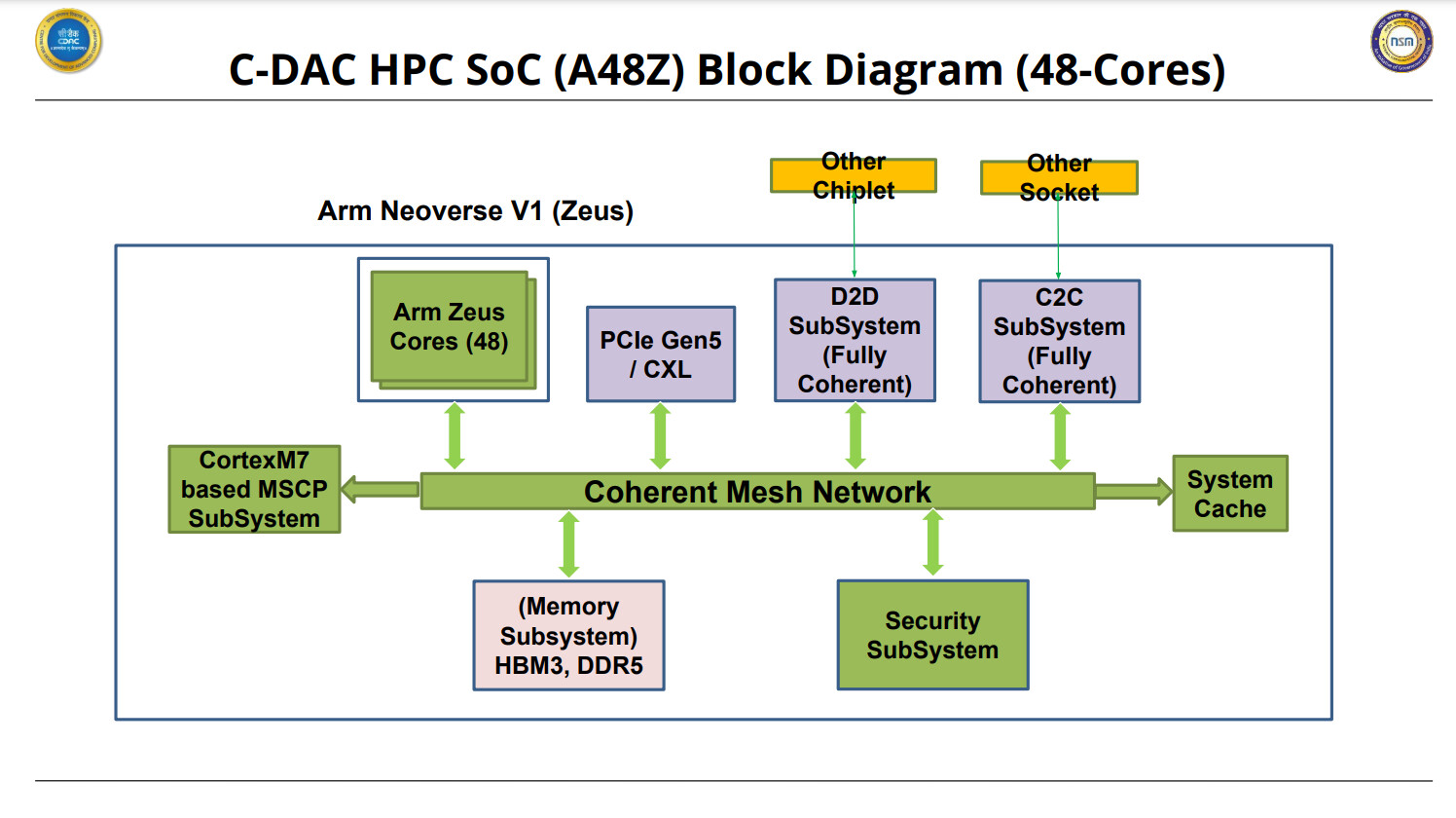
AMD today announced a new addition to the Instinct MI200 family of accelerators. Officially titled Instinct MI210 accelerator, AMD tries to bring exascale-class technologies to mainstream HPC and AI customers with this model. Based on CDNA2 compute architecture built for heavy HPC and AI workloads, the card features 104 compute units (CUs), totaling 6656 Streaming Processors (SPs). With a peak engine clock of 1700 MHz, the card can output 181 TeraFLOPs of FP16 half-precision peak compute, 22.6 TeraFLOPs peak FP32 single-precision, and 22.6 TFLOPs peak FP62 double-precision compute. For single-precision matrix (FP32) compute, the card can deliver a peak of 45.3 TFLOPs. The INT4/INT8 precision settings provide 181 TOPs, while MI210 can compute the bfloat16 precision format with 181 TeraFLOPs at peak.
The card uses a 4096-bit memory interface connecting 64 GBs of HMB2e to the compute silicon. The total memory bandwidth is 1638.4 GB/s, while memory modules run at a 1.6 GHz frequency. It is important to note that the ECC is supported on the entire chip. AMD provides an Instinct MI210 accelerator as a PCIe solution, based on a PCIe 4.0 standard. The card is rated for a TDP of 300 Watts and is cooled passively. There are three infinity fabric links enabled, and the maximum bandwidth of the infinity fabric link is 100 GB/s. Pricing is unknown; however, availability is March 22nd, which is the immediate launch date.
AMD places this card directly aiming at NVIDIA A100 80 GB accelerator as far as the targeted segment, with emphasis on half-precision and INT4/INT8 heavy applications.