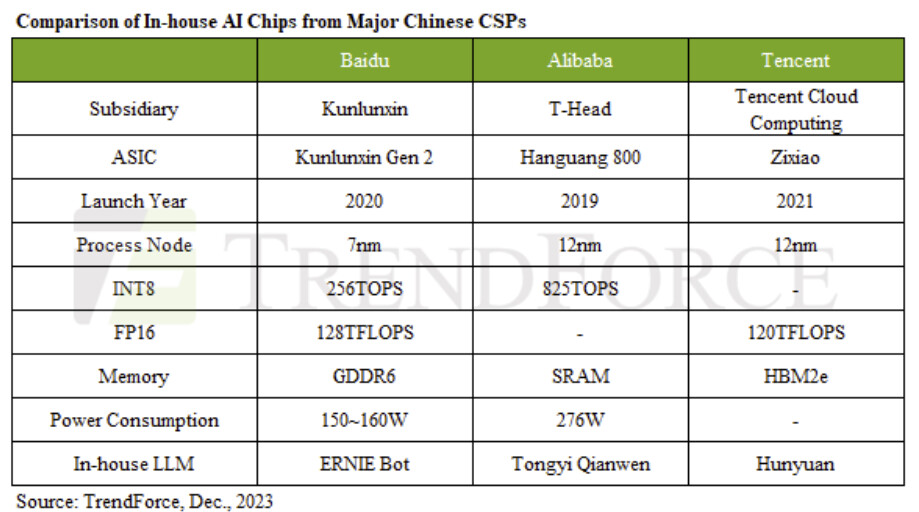
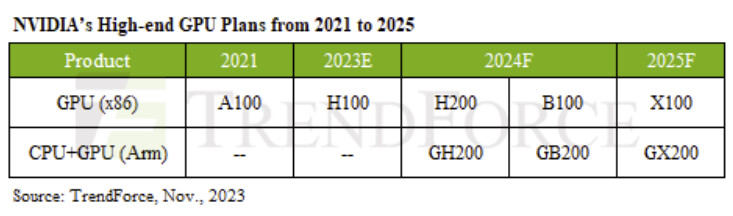
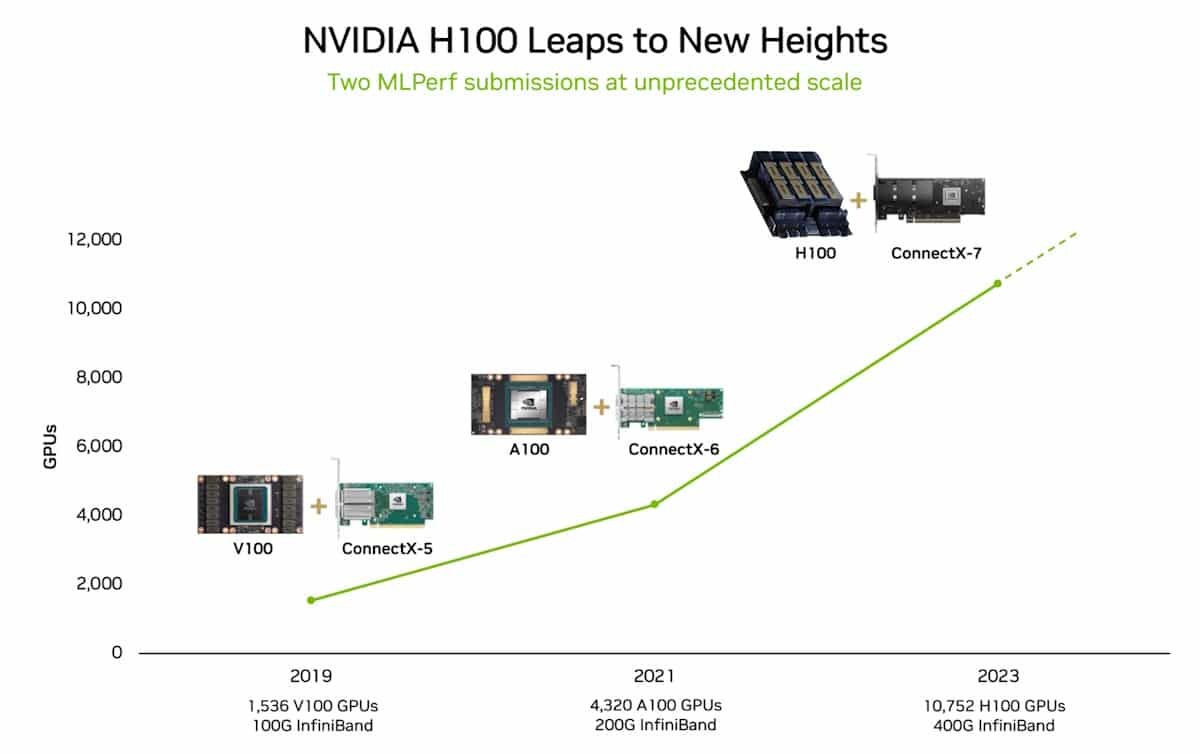
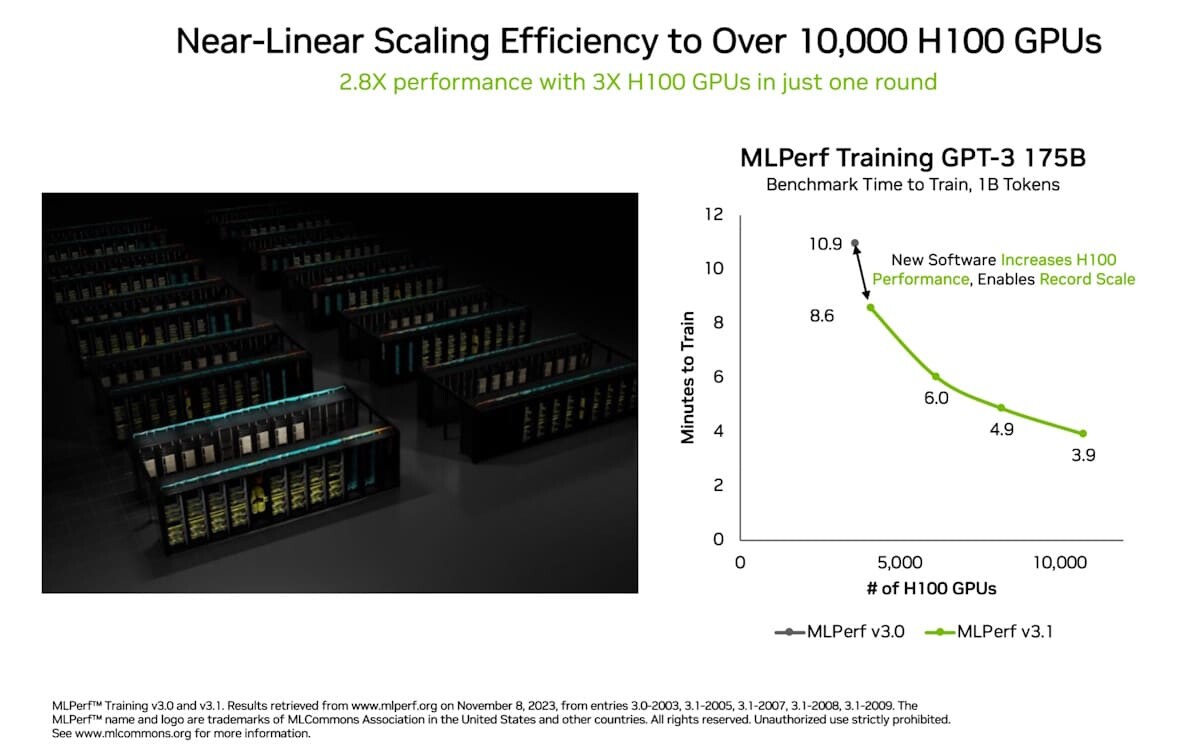
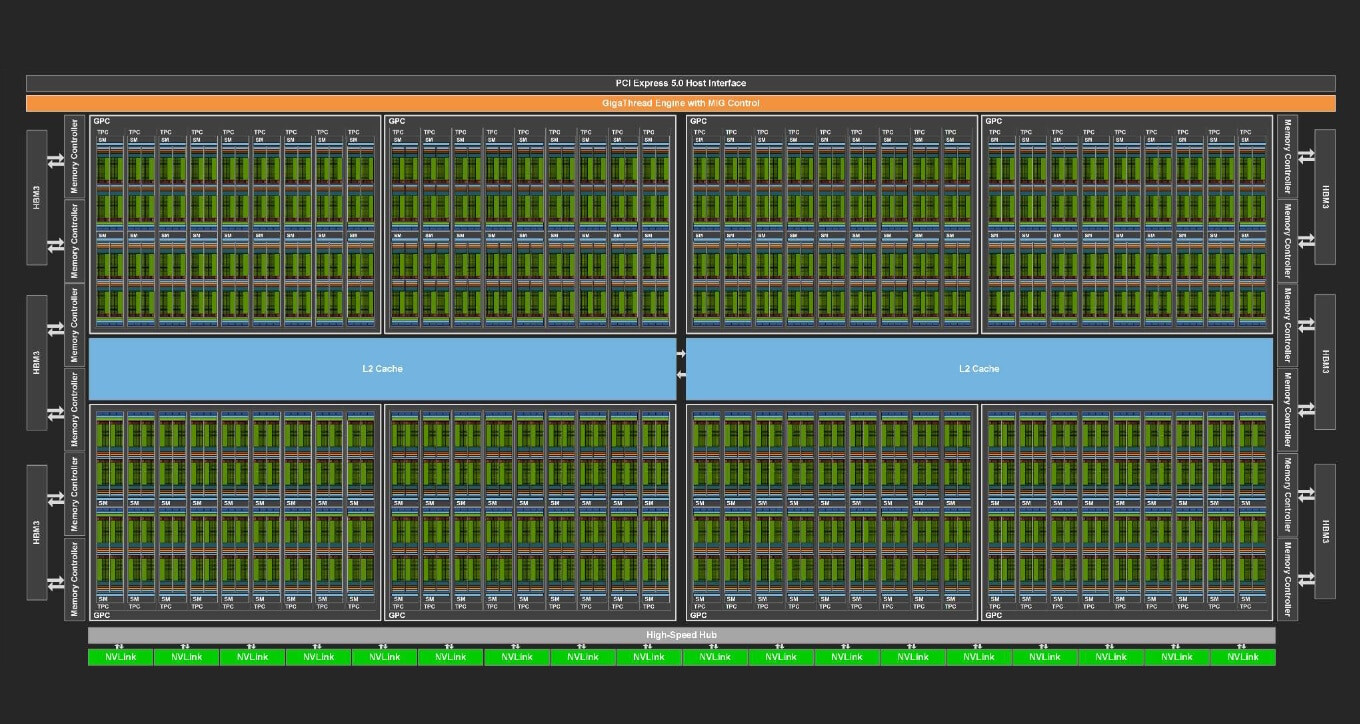
AMD Instinct MI300X GPUs Featured in LaminiAI LLM Pods
LaminiAI appears to be one of AMD's first customers to receive a bulk order of Instinct MI300X GPUs—late last week, Sharon Zhou (CEO and co-founder) posted about the "next batch of LaminiAI LLM Pods" up and running with Team Red's cutting-edge CDNA 3 series accelerators inside. Her short post on social media stated: "rocm-smi...like freshly baked bread, 8x MI300X is online—if you're building on open LLMs and you're blocked on compute, lmk. Everyone should have access to this wizard technology called LLMs."
An attached screenshot of a ROCm System Management Interface (ROCm SMI) session showcases an individual Pod configuration sporting eight Instinct MI300X GPUs. According to official blog entries, LaminiAI has utilized bog-standard MI300 accelerators since 2023, so it is not surprising to see their partnership continue to grow with AMD. Industry predictions have the Instinct MI300X and MI300A models placed as great alternatives to NVIDIA's dominant H100 "Hopper" series—AMD stock is climbing due to encouraging financial analyst estimations.



An attached screenshot of a ROCm System Management Interface (ROCm SMI) session showcases an individual Pod configuration sporting eight Instinct MI300X GPUs. According to official blog entries, LaminiAI has utilized bog-standard MI300 accelerators since 2023, so it is not surprising to see their partnership continue to grow with AMD. Industry predictions have the Instinct MI300X and MI300A models placed as great alternatives to NVIDIA's dominant H100 "Hopper" series—AMD stock is climbing due to encouraging financial analyst estimations.