NVIDIA A800 China-Tailored GPU Performance within 70% of A100
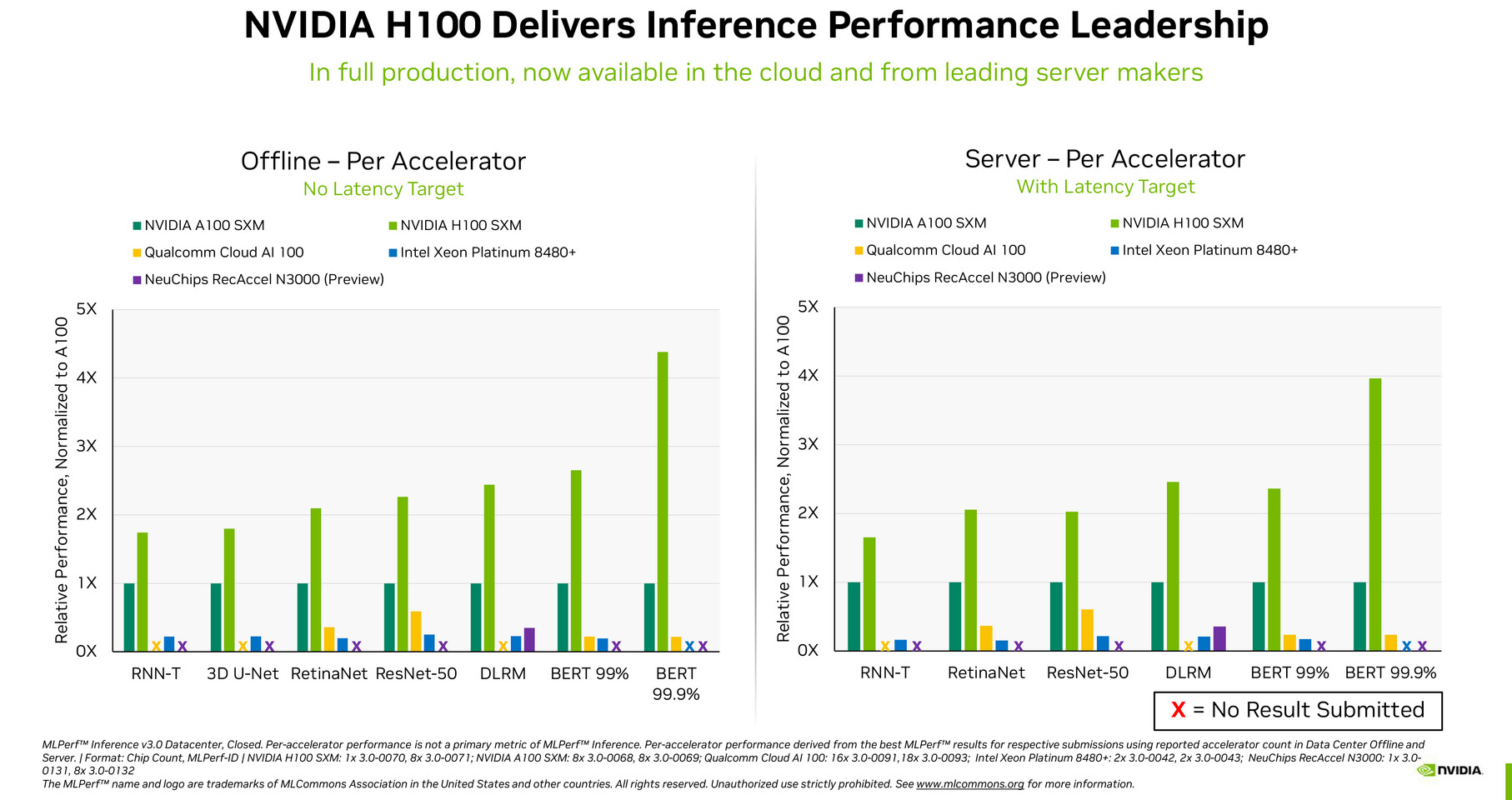
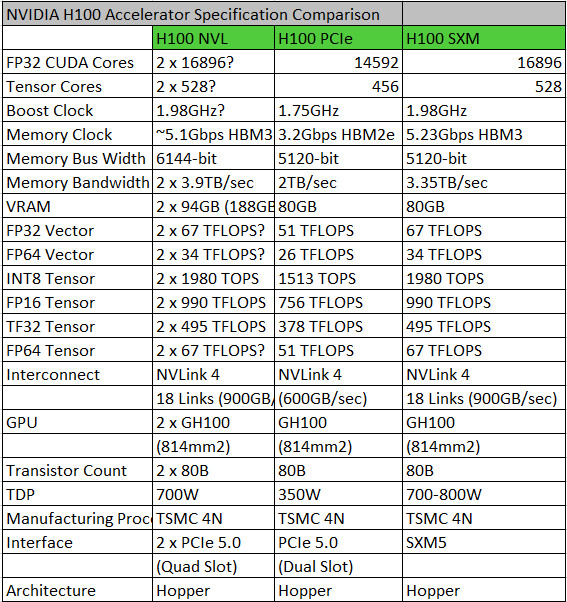
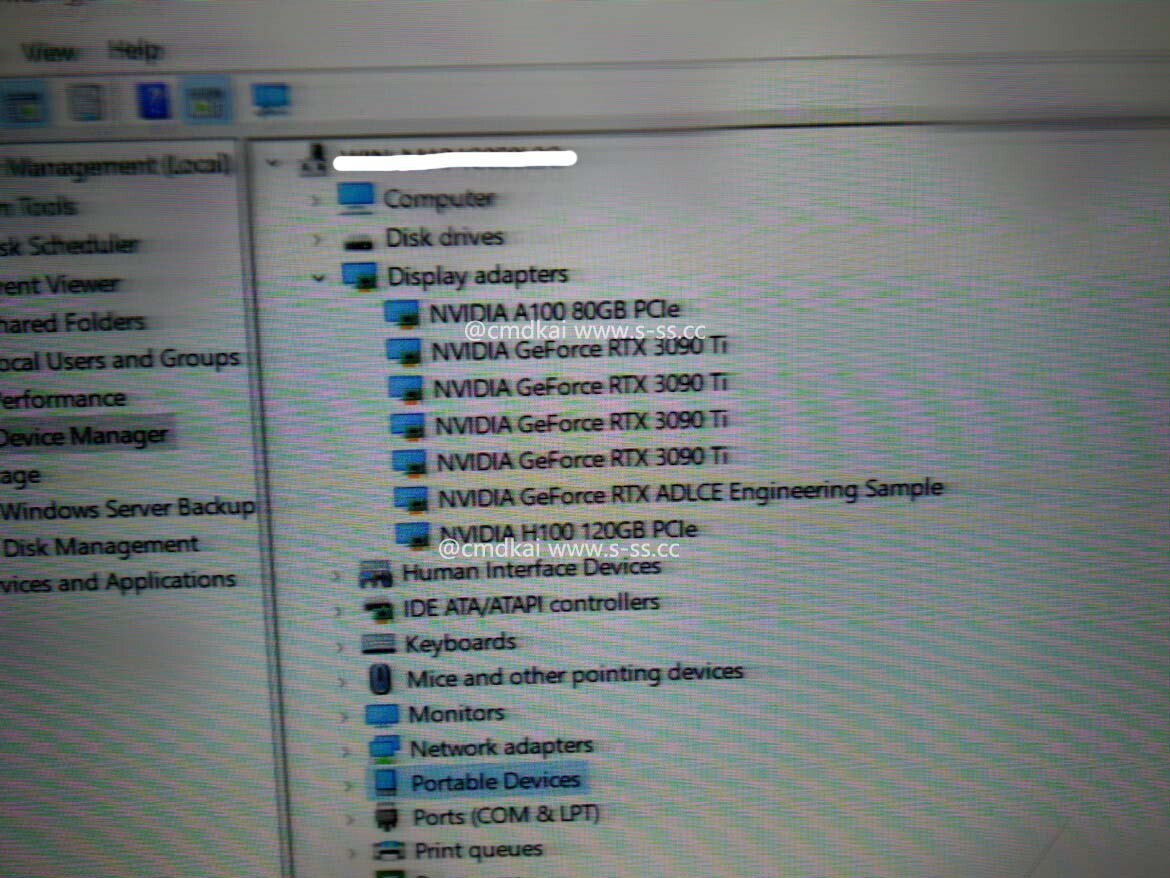
The recent growth in demand for training Large Language Models (LLMs) like Generative Pre-trained Transformer (GPT) has sparked the interest of many companies to invest in GPU solutions that are used to train these models. However, countries like China have struggled with US sanctions, and NVIDIA has to create custom models that meet US export regulations. Carrying two GPUs, H800 and A800, they represent cut-down versions of the original H100 and A100, respectively. We reported about H800; however, it remained as mysterious as A800 that we are talking about today. Thanks to MyDrivers, we have information that the A800 GPU performance is within 70% of the regular A100.
The regular A100 GPU manages 9.7 TeraFLOPs of FP64, 19.5 TeraFLOPS of FP64 Tensor, and up to 624 BF16/FP16 TeraFLOPS with sparsity. A rough napkin math would suggest that 70% performance of the original (a 30% cut) would equal 6.8 TeraFLOPs of FP64 precision, 13.7 TeraFLOPs of FP64 Tensor, and 437 BF16/FP16 TeraFLOPs with sparsity. MyDrivers notes that A800 can be had for 100,000 Yuan, translating to about 14,462 USD at the time of writing. This is not the most capable GPU that Chinese companies can acquire, as H800 exists. However, we don't have any information about its performance for now.
The regular A100 GPU manages 9.7 TeraFLOPs of FP64, 19.5 TeraFLOPS of FP64 Tensor, and up to 624 BF16/FP16 TeraFLOPS with sparsity. A rough napkin math would suggest that 70% performance of the original (a 30% cut) would equal 6.8 TeraFLOPs of FP64 precision, 13.7 TeraFLOPs of FP64 Tensor, and 437 BF16/FP16 TeraFLOPs with sparsity. MyDrivers notes that A800 can be had for 100,000 Yuan, translating to about 14,462 USD at the time of writing. This is not the most capable GPU that Chinese companies can acquire, as H800 exists. However, we don't have any information about its performance for now.