Micron to Launch HBM2 Memory This Year
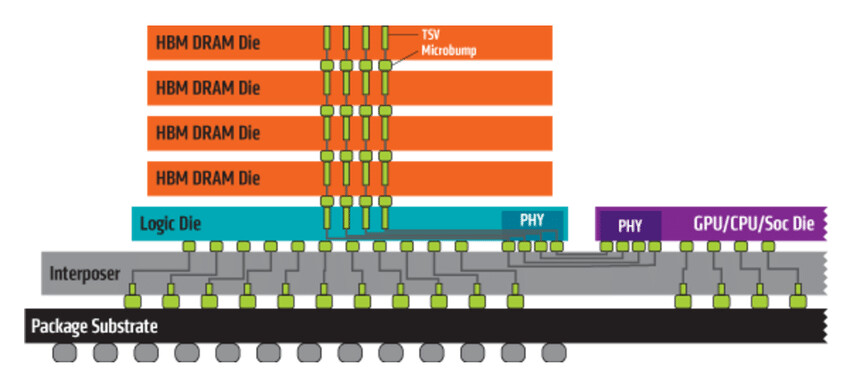
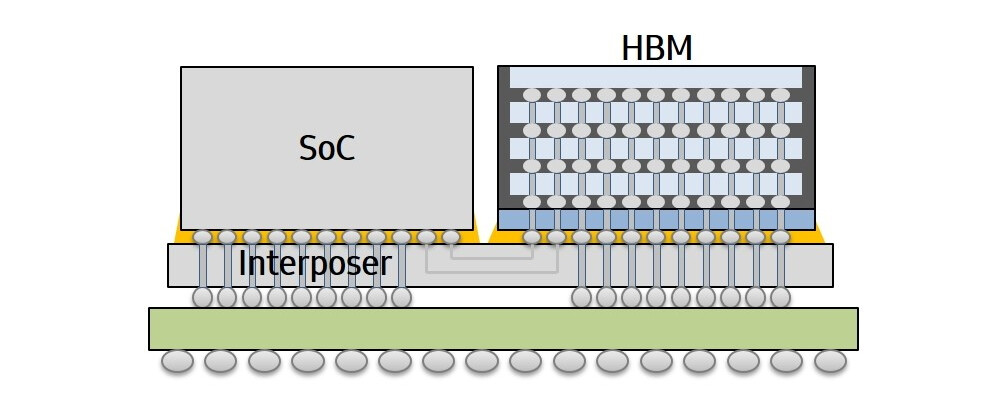
Micron Technologies, in the latest earnings report, announced that they will start shipping High-Bandwidth Memory 2 (HBM2) DRAM. Used for high-performance graphics cards, server processors and all kinds of processors, HBM2 memory is wanted and relatively expensive solution, however, when Micron enters the market of its manufacturing, prices, and the market should adjust for the new player. Previously, only SK-Hynix and Samsung were manufacturing the HBM2 DRAM, however, Micron will join them and they will again form a "big-three" pact that dominates the memory market.
Up until now, Micron used to lay all hopes on its proprietary Hybrid Memory Cube (HMC) DRAM type, which didn't gain much traction from customers and it never really took off. Only a few rare products used it, as Fujitsu SPARC64 XIfx CPU used in Fujitsu PRIMEHPC FX100 supercomputer introduced in 2015. Micron announced to suspend works on HMC in 2018 and decided to devote their efforts to GDDR6 and HBM development. So, as a result, we are seeing that they will launch HBM2 DRAM products sometime this year.
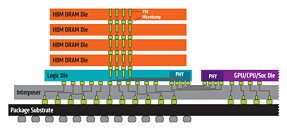
Up until now, Micron used to lay all hopes on its proprietary Hybrid Memory Cube (HMC) DRAM type, which didn't gain much traction from customers and it never really took off. Only a few rare products used it, as Fujitsu SPARC64 XIfx CPU used in Fujitsu PRIMEHPC FX100 supercomputer introduced in 2015. Micron announced to suspend works on HMC in 2018 and decided to devote their efforts to GDDR6 and HBM development. So, as a result, we are seeing that they will launch HBM2 DRAM products sometime this year.