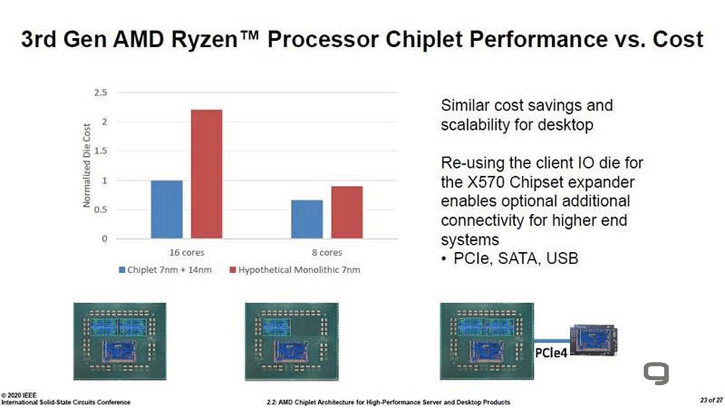
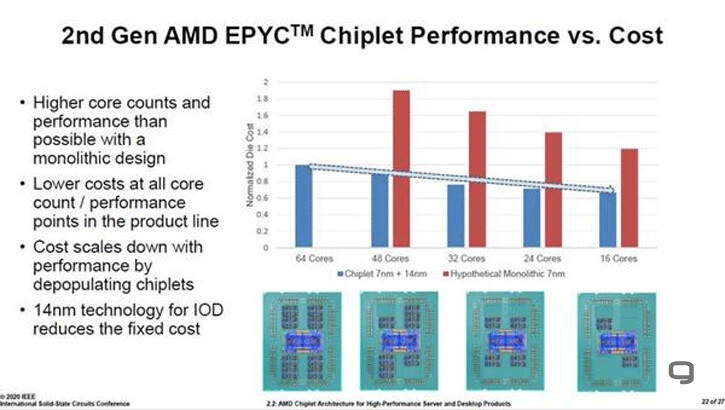
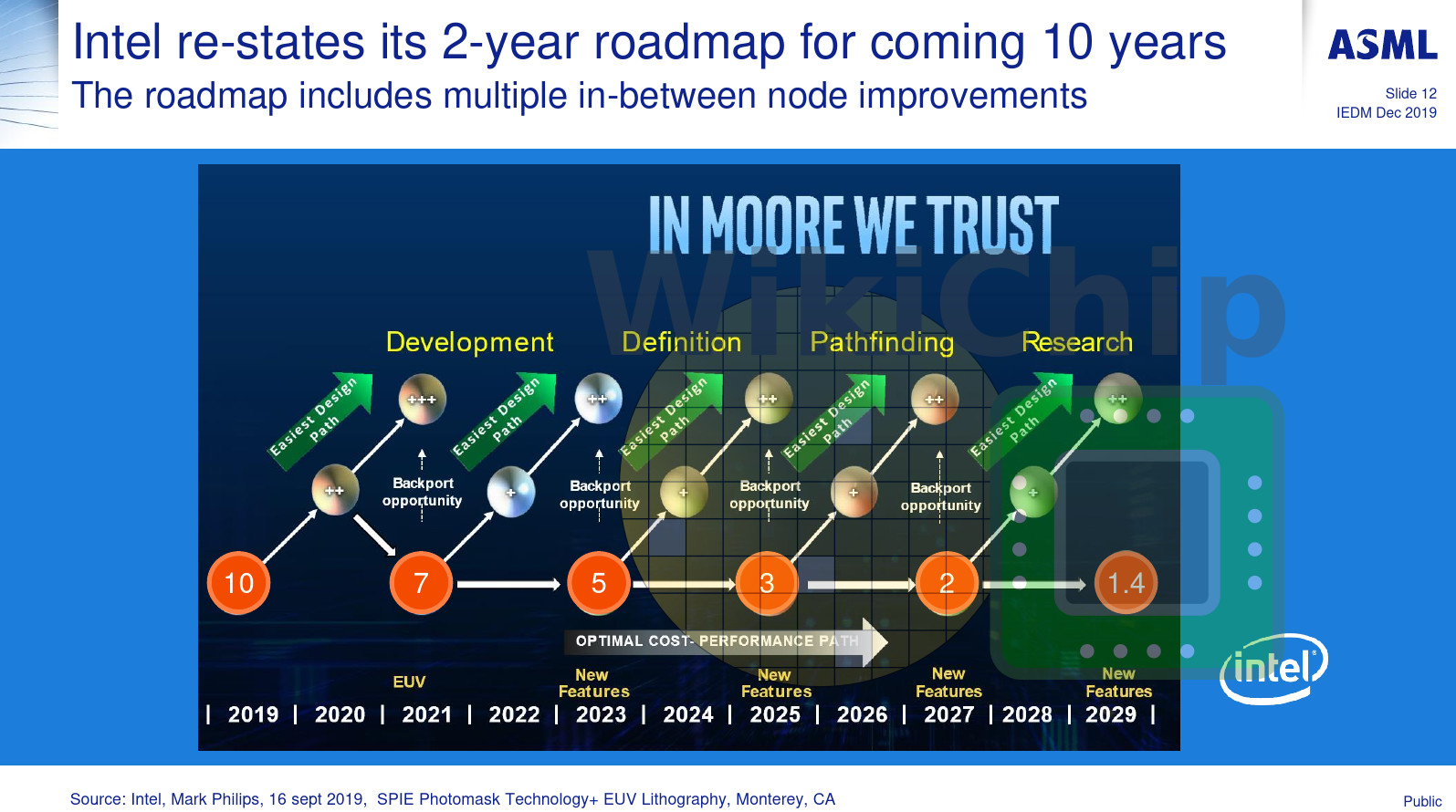
Intel, Marvell, and Synopsys to Showcase Next-Gen Memory PHY IP Capable of 224 Gbps on 3nm-class FinFET Nodes
The sneak peeks from the upcoming IEEE Solid State Circuit Conference continues, as the agenda items unveil interesting tech that will be either unveiled or demonstrated there. Intel, Synopsys, and Marvell, are leading providers of DRAM physical layer interface (PHY) IP. Various processor, GPU, and SoC manufacturers license PHY and memory controller IP from these companies, to integrate with their designs. All three companies are ready with over 200 Gbps around the 2.69 to 3 petajoule per bit range. This energy cost is as important as the data-rate on offer; as it showcases the viability of the PHY for a specific application (for example, a smartphone SoC has to conduct its memory sub-system at a vastly more constrained energy budget compared to an HPC processor).
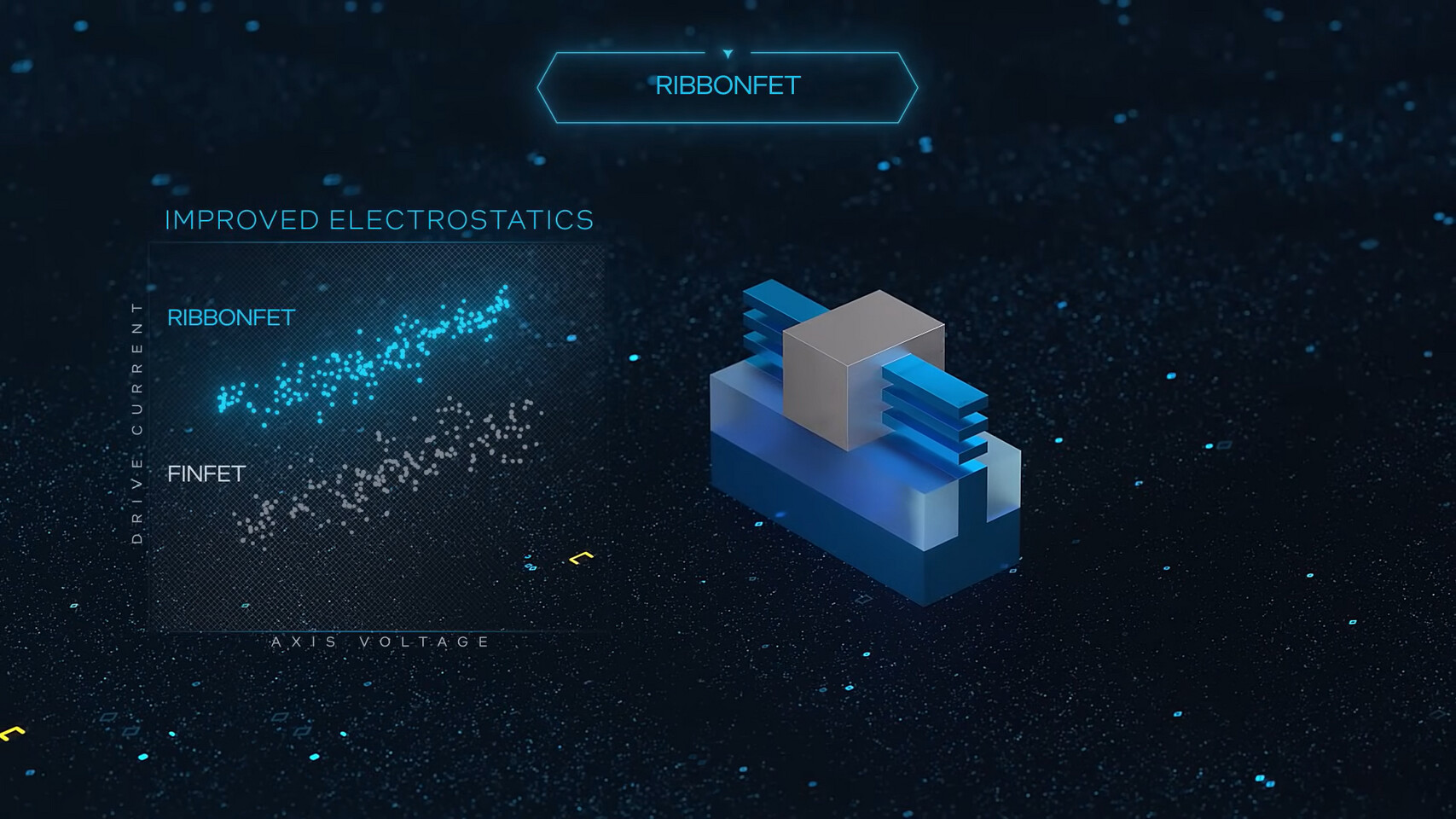
Intel is the first in the pack to showcase a 224 Gbps sub-picojoule/bit PHY transmitter that supports PAM4 and PAM6 signaling, and is designed for 3 nm-class FinFET foundry nodes. If you recall, Intel 3 will be the company's final FinFET node before it transitions to nanosheets with the Intel 20A node. At the physical layer, all digital memory signal is analogue, and Intel's IP focuses on the DAC aspect of the PHY. Next up, is a somewhat similar transceiver IP by Synopsys. This too claims 224 Gbps speeds at 3 pJ/b, but at a 40 dB insertion loss; and is designed for 3 nm class FinFET nodes such as the TSMC N3 family and Intel 3. Samsung's 3 nm node uses the incompatible GAAFET technology for its 3 nm EUV node. Lastly, there's Marvell, with a 212 Gb/s DSP-based transceiver for optical direct-detect applications on the 5 nm FinFET nodes, which is relevant for high speed network switching fabrics.
Intel is the first in the pack to showcase a 224 Gbps sub-picojoule/bit PHY transmitter that supports PAM4 and PAM6 signaling, and is designed for 3 nm-class FinFET foundry nodes. If you recall, Intel 3 will be the company's final FinFET node before it transitions to nanosheets with the Intel 20A node. At the physical layer, all digital memory signal is analogue, and Intel's IP focuses on the DAC aspect of the PHY. Next up, is a somewhat similar transceiver IP by Synopsys. This too claims 224 Gbps speeds at 3 pJ/b, but at a 40 dB insertion loss; and is designed for 3 nm class FinFET nodes such as the TSMC N3 family and Intel 3. Samsung's 3 nm node uses the incompatible GAAFET technology for its 3 nm EUV node. Lastly, there's Marvell, with a 212 Gb/s DSP-based transceiver for optical direct-detect applications on the 5 nm FinFET nodes, which is relevant for high speed network switching fabrics.