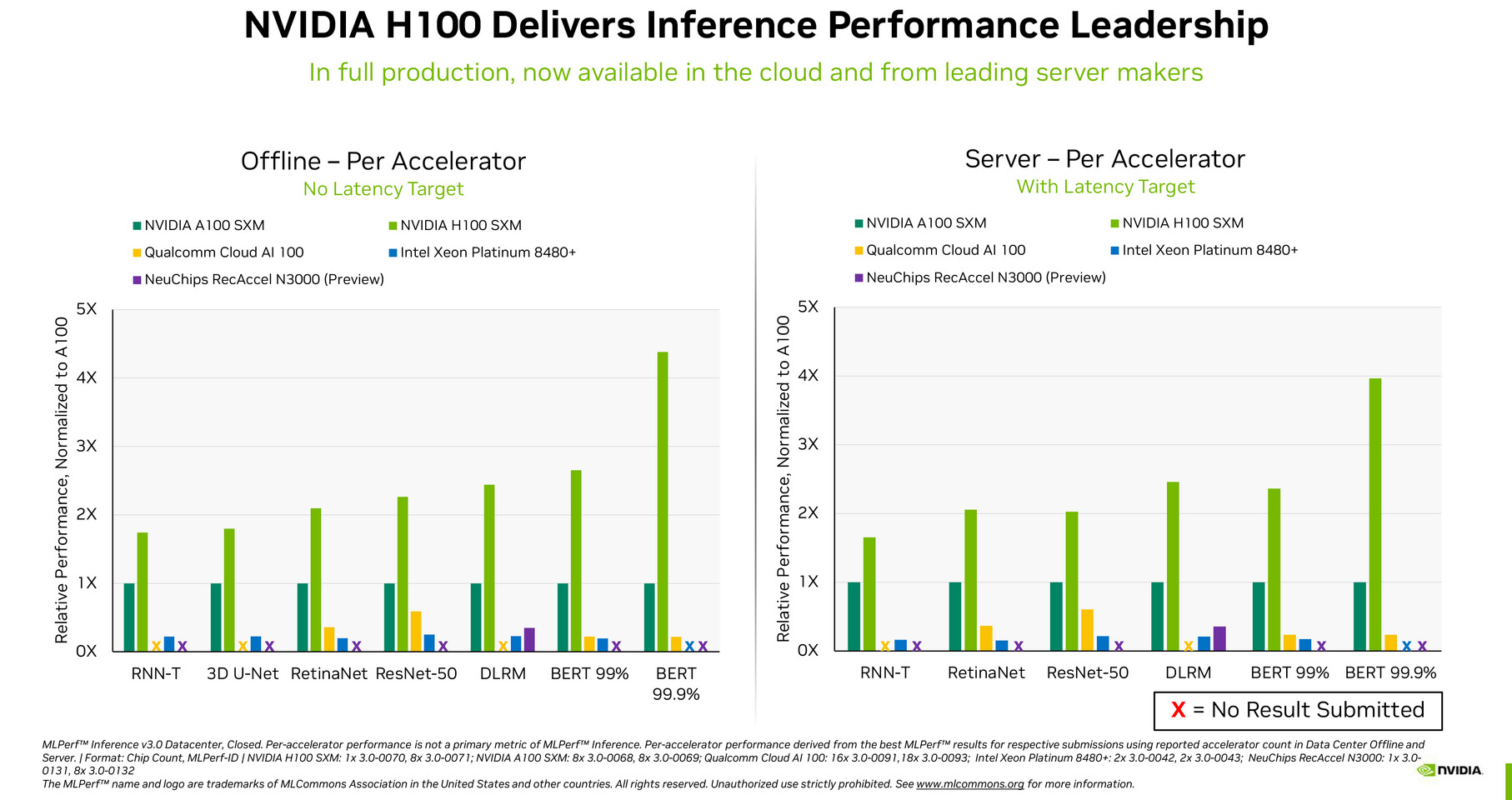
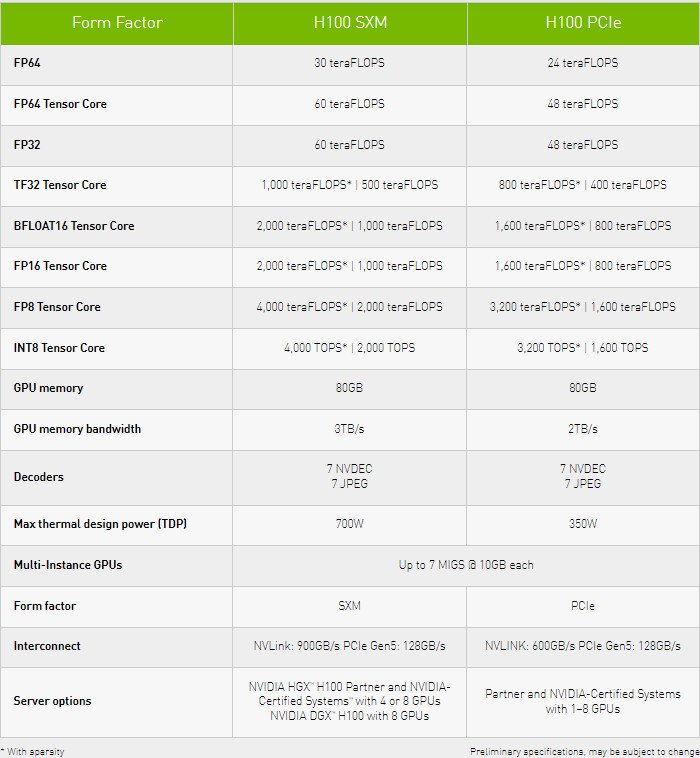
NVIDIA DGX H100 Systems are Now Shipping
Customers from Japan to Ecuador and Sweden are using NVIDIA DGX H100 systems like AI factories to manufacture intelligence. They're creating services that offer AI-driven insights in finance, healthcare, law, IT and telecom—and working to transform their industries in the process. Among the dozens of use cases, one aims to predict how factory equipment will age, so tomorrow's plants can be more efficient.
Called Green Physics AI, it adds information like an object's CO2 footprint, age and energy consumption to SORDI.ai, which claims to be the largest synthetic dataset in manufacturing.
Called Green Physics AI, it adds information like an object's CO2 footprint, age and energy consumption to SORDI.ai, which claims to be the largest synthetic dataset in manufacturing.