Supermicro Expands AI Solutions with the Upcoming NVIDIA HGX H200 and MGX Grace Hopper Platforms Featuring HBM3e Memory
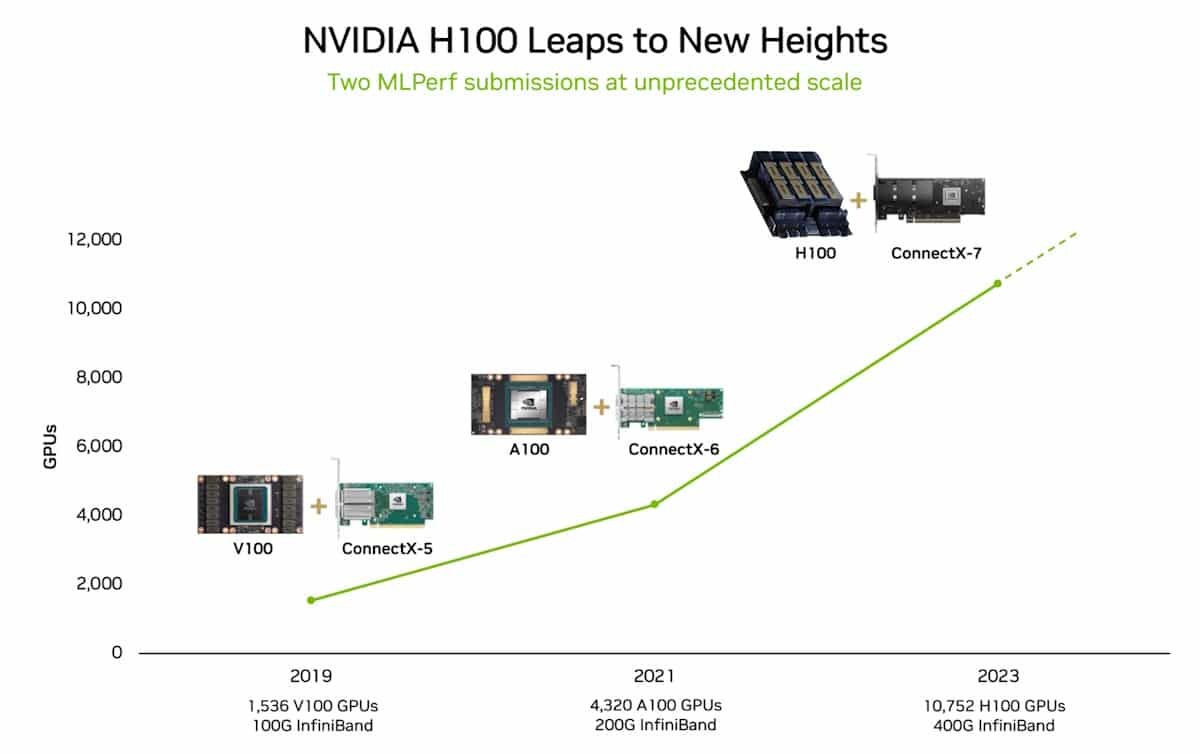
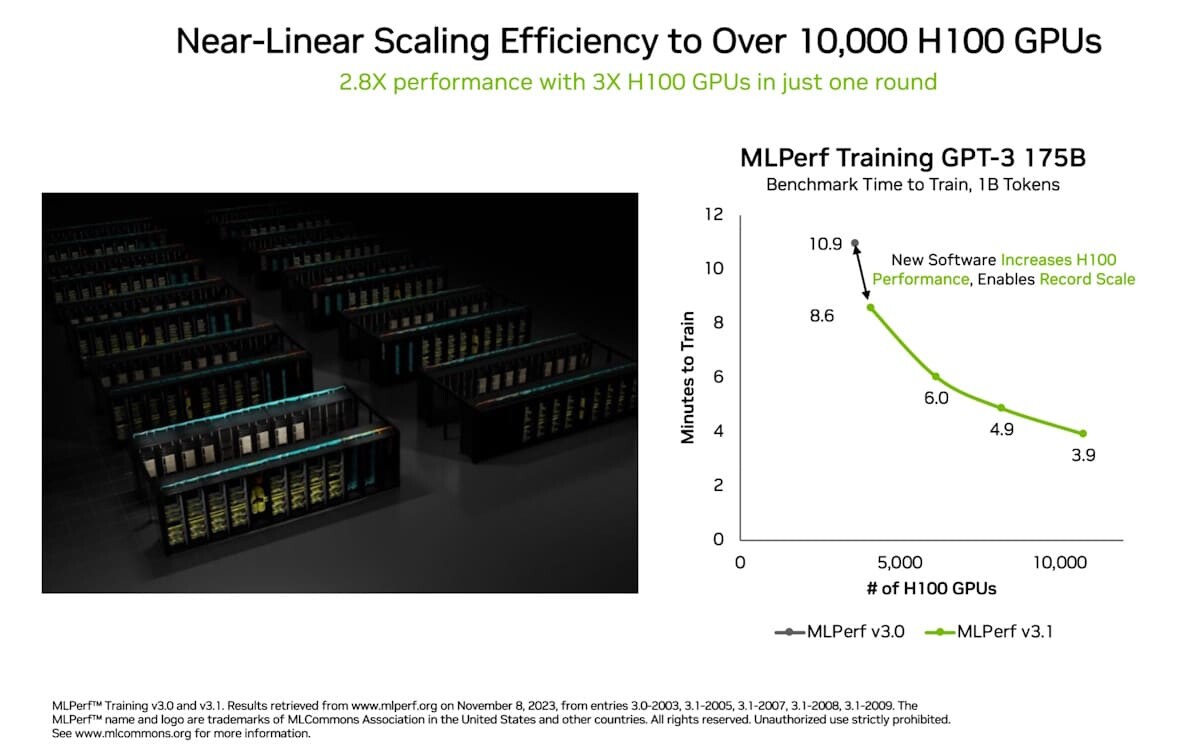
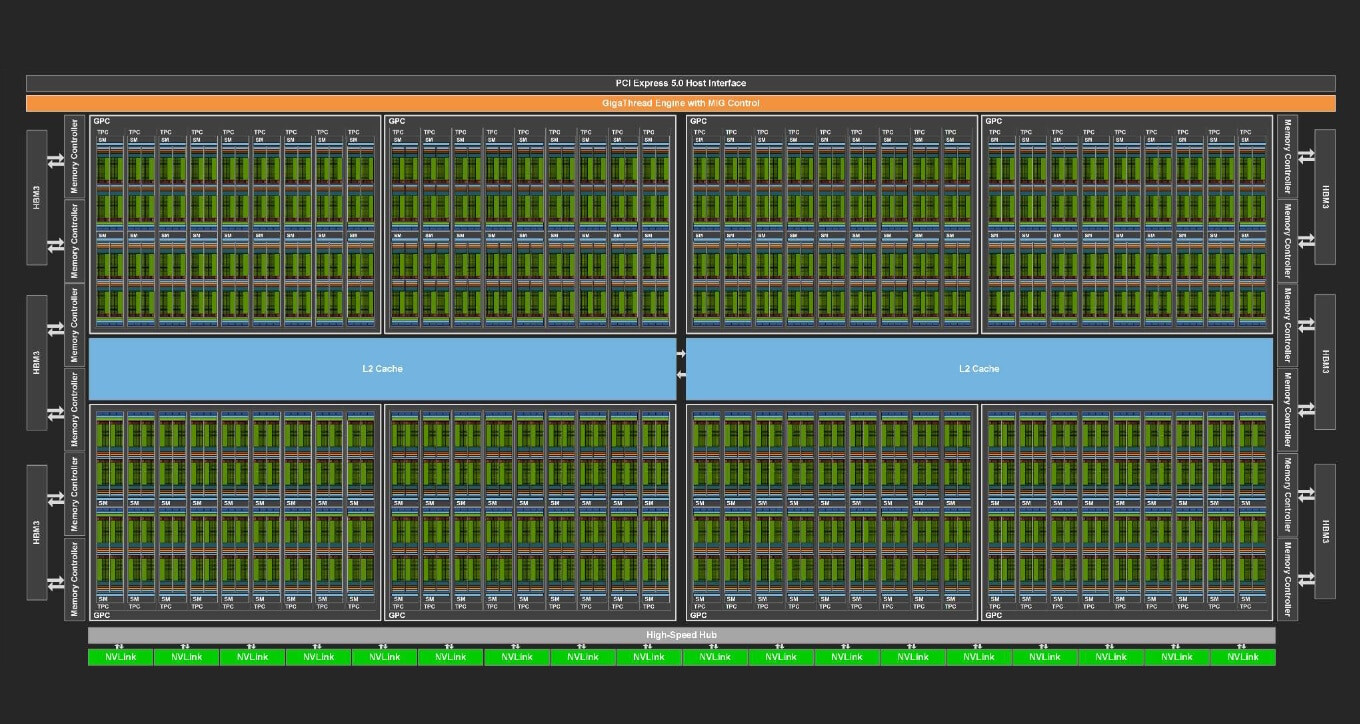
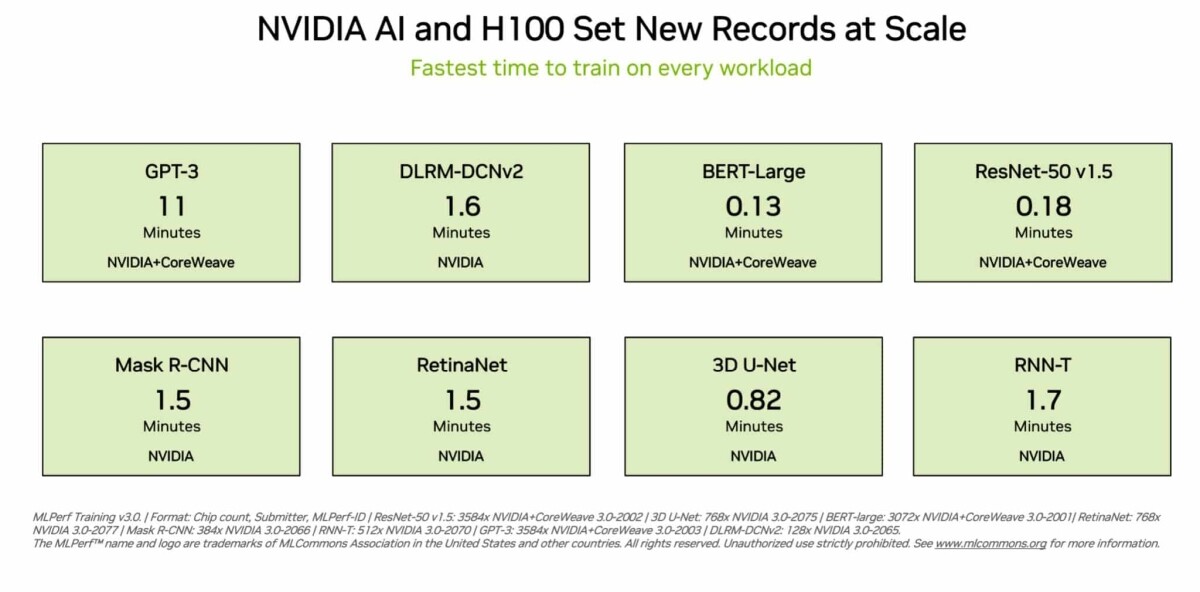
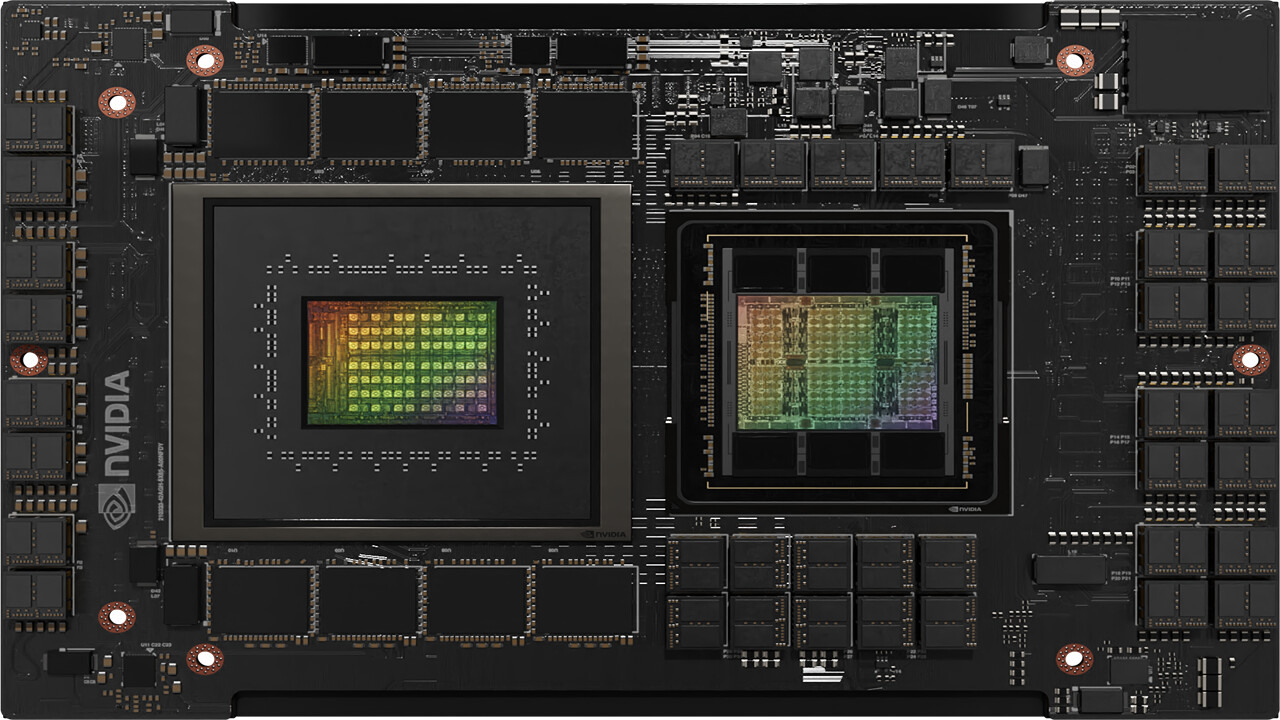
Supermicro, Inc., a Total IT Solution Provider for AI, Cloud, Storage, and 5G/Edge, is expanding its AI reach with the upcoming support for the new NVIDIA HGX H200 built with H200 Tensor Core GPUs. Supermicro's industry leading AI platforms, including 8U and 4U Universal GPU Systems, are drop-in ready for the HGX H200 8-GPU, 4-GPU, and with nearly 2x capacity and 1.4x higher bandwidth HBM3e memory compared to the NVIDIA H100 Tensor Core GPU. In addition, the broadest portfolio of Supermicro NVIDIA MGX systems supports the upcoming NVIDIA Grace Hopper Superchip with HBM3e memory. With unprecedented performance, scalability, and reliability, Supermicro's rack scale AI solutions accelerate the performance of computationally intensive generative AI, large language Model (LLM) training, and HPC applications while meeting the evolving demands of growing model sizes. Using the building block architecture, Supermicro can quickly bring new technology to market, enabling customers to become more productive sooner.
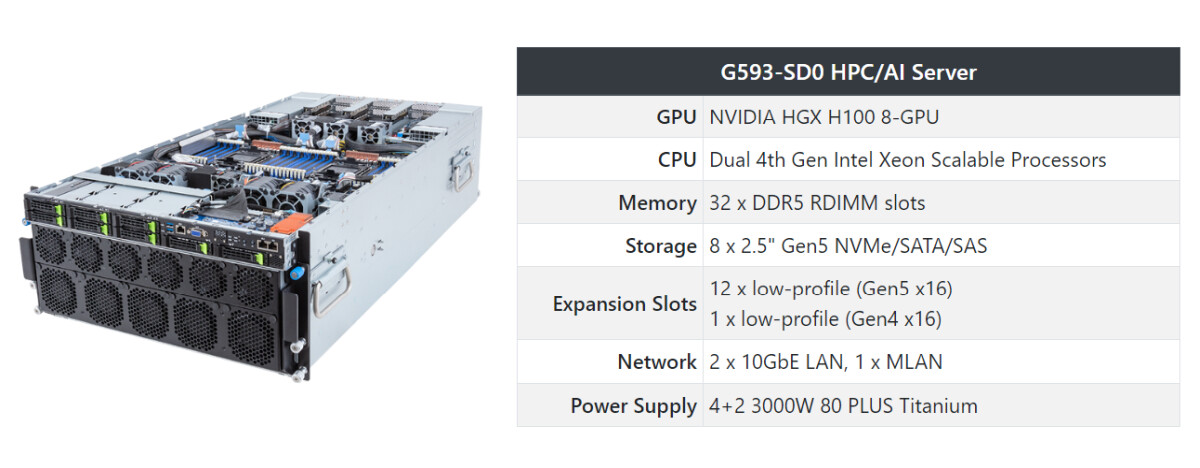
Supermicro is also introducing the industry's highest density server with NVIDIA HGX H100 8-GPUs systems in a liquid cooled 4U system, utilizing the latest Supermicro liquid cooling solution. The industry's most compact high performance GPU server enables data center operators to reduce footprints and energy costs while offering the highest performance AI training capacity available in a single rack. With the highest density GPU systems, organizations can reduce their TCO by leveraging cutting-edge liquid cooling solutions.
Supermicro is also introducing the industry's highest density server with NVIDIA HGX H100 8-GPUs systems in a liquid cooled 4U system, utilizing the latest Supermicro liquid cooling solution. The industry's most compact high performance GPU server enables data center operators to reduce footprints and energy costs while offering the highest performance AI training capacity available in a single rack. With the highest density GPU systems, organizations can reduce their TCO by leveraging cutting-edge liquid cooling solutions.