Unwrapping the NVIDIA B200 and GB200 AI GPU Announcements
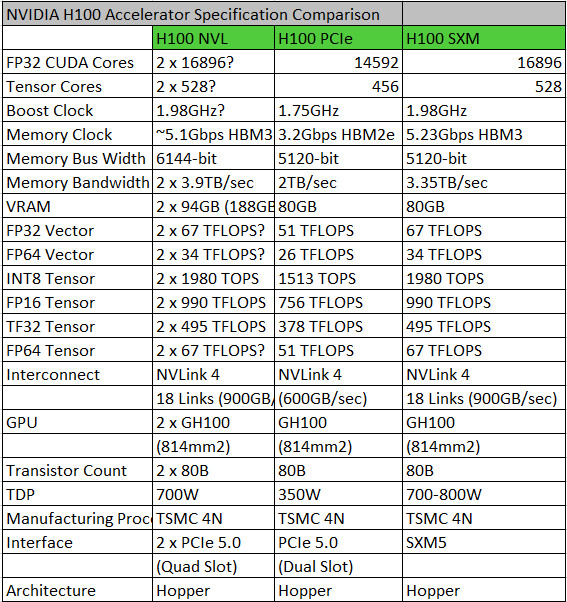
NVIDIA on Monday, at the 2024 GTC conference, unveiled the "Blackwell" B200 and GB200 AI GPUs. These are designed to offer an incredible 5X the AI inferencing performance gain over the current-gen "Hopper" H100, and come with four times the on-package memory. The B200 "Blackwell" is the largest chip physically possible using existing foundry tech, according to its makers. The chip is an astonishing 208 billion transistors, and is made up of two chiplets, which by themselves are the largest possible chips.
Each chiplet is built on the TSMC N4P foundry node, which is the most advanced 4 nm-class node by the Taiwanese foundry. Each chiplet has 104 billion transistors. The two chiplets have a high degree of connectivity with each other, thanks to a 10 TB/s custom interconnect. This is enough bandwidth and latency for the two to maintain cache coherency (i.e. address each other's memory as if they're their own). Each of the two "Blackwell" chiplets has a 4096-bit memory bus, and is wired to 96 GB of HBM3E spread across four 24 GB stacks; which totals to 192 GB for the B200 package. The GPU has a staggering 8 TB/s of memory bandwidth on tap. The B200 package features a 1.8 TB/s NVLink interface for host connectivity, and connectivity to another B200 chip.



Each chiplet is built on the TSMC N4P foundry node, which is the most advanced 4 nm-class node by the Taiwanese foundry. Each chiplet has 104 billion transistors. The two chiplets have a high degree of connectivity with each other, thanks to a 10 TB/s custom interconnect. This is enough bandwidth and latency for the two to maintain cache coherency (i.e. address each other's memory as if they're their own). Each of the two "Blackwell" chiplets has a 4096-bit memory bus, and is wired to 96 GB of HBM3E spread across four 24 GB stacks; which totals to 192 GB for the B200 package. The GPU has a staggering 8 TB/s of memory bandwidth on tap. The B200 package features a 1.8 TB/s NVLink interface for host connectivity, and connectivity to another B200 chip.