NVIDIA Announces Financial Results for First Quarter Fiscal 2023
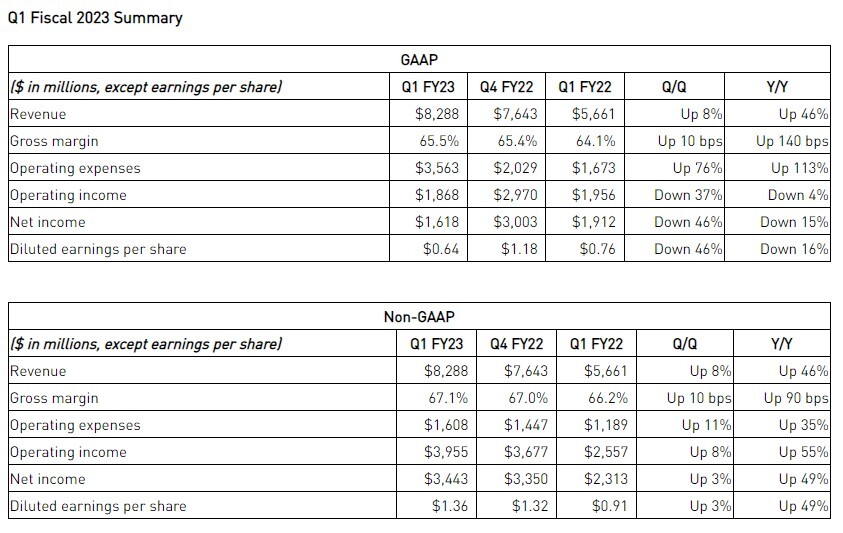
NVIDIA (NASDAQ: NVDA) today reported record revenue for the first quarter ended May 1, 2022, of $8.29 billion, up 46% from a year ago and up 8% from the previous quarter, with record revenue in Data Center and Gaming. GAAP earnings per diluted share for the quarter were $0.64, down 16% from a year ago and down 46% from the previous quarter, and include an after-tax impact of $0.52 related to the $1.35 billion Arm acquisition termination charge. Non-GAAP earnings per diluted share were $1.36, up 49% from a year ago and up 3% from the previous quarter.
"We delivered record results in Data Center and Gaming against the backdrop of a challenging macro environment," said Jensen Huang, founder and CEO of NVIDIA. "The effectiveness of deep learning to automate intelligence is driving companies across industries to adopt NVIDIA for AI computing. Data Center has become our largest platform, even as Gaming achieved a record quarter.
"We delivered record results in Data Center and Gaming against the backdrop of a challenging macro environment," said Jensen Huang, founder and CEO of NVIDIA. "The effectiveness of deep learning to automate intelligence is driving companies across industries to adopt NVIDIA for AI computing. Data Center has become our largest platform, even as Gaming achieved a record quarter.